Lass uns am Anfang beginnen und uns hocharbeiten.
Grundlagen#
KI vs ML vs Deep Learning#
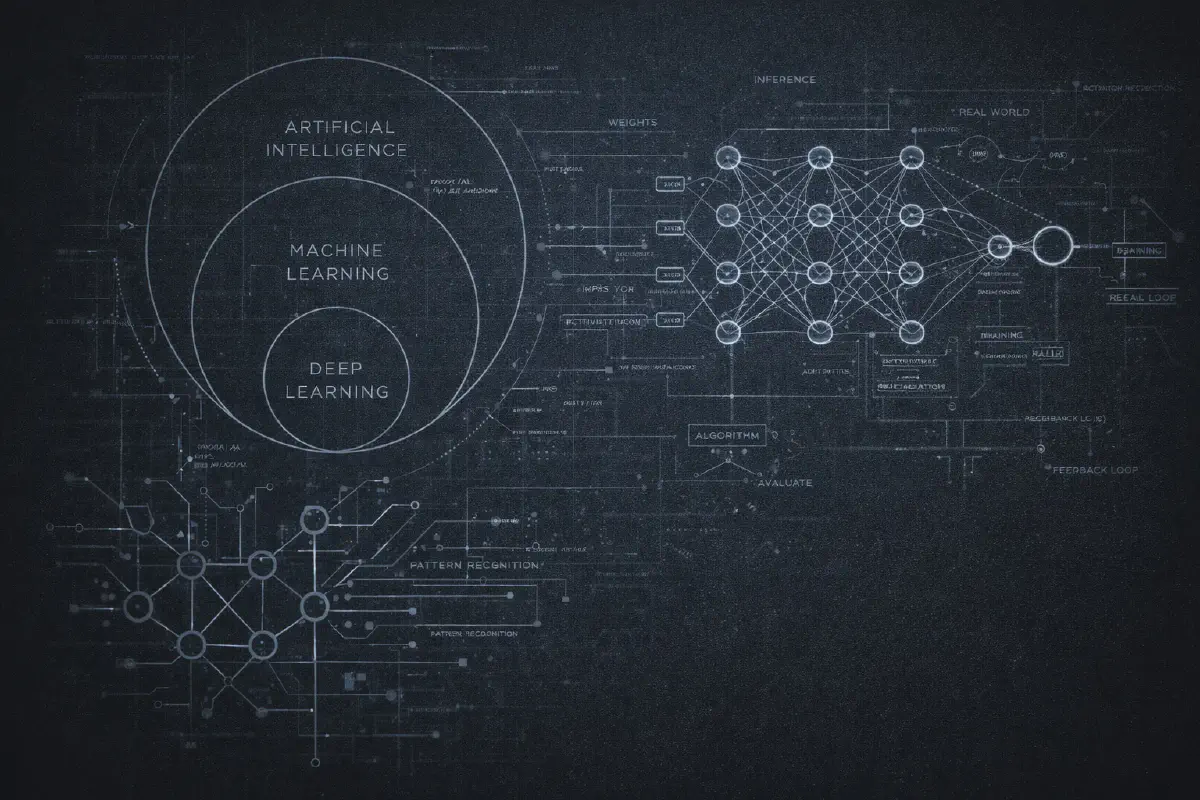
Du hast wahrscheinlich das Diagramm gesehen: drei konzentrische Kreise mit KI aussen, Machine Learning in der Mitte und Deep Learning im Kern. Es ist zu einem Klischee geworden, aber es ist wirklich nuetzlich, um zu verstehen, wie diese Begriffe zusammenhaengen.
Kuenstliche Intelligenz ist der breiteste Begriff. Er bedeutet einfach “Computer dazu zu bringen, Dinge zu tun, die Intelligenz erfordern wuerden, wenn Menschen sie taeten.” Das ist alles. Ein Schachprogramm aus den 1970ern? KI. Dein Spam-Filter? KI. Eine einfache If-Else-Regel, die entscheidet, ob dir ein Popup angezeigt wird? Technisch gesehen auch KI. Der Begriff ist so breit, dass er allein fast bedeutungslos ist.
Machine Learning ist eine Teilmenge von KI, bei der man anstatt explizite Regeln zu programmieren, dem Computer Beispiele gibt und ihn die Muster herausfinden laesst. Anstatt “wenn E-Mail ’nigerianischer Prinz’ enthaelt, als Spam markieren” zu schreiben, zeigst du ihm 10.000 E-Mails, die als “Spam” oder “kein Spam” gekennzeichnet sind, und laesst den Algorithmus lernen, was Spam… spammig macht.
Deep Learning ist eine Teilmenge von Machine Learning, die neuronale Netze mit vielen Schichten verwendet (daher “deep/tief”). Hier wurde es in den 2010ern interessant. Deep Learning ermoeglichte Durchbrueche in der Bilderkennung, Spracherkennung und schliesslich die Sprachmodelle, von denen wir jetzt alle besessen sind.
Neuronale Netzwerke#
Hier ist eine Analogie, die nicht perfekt, aber nuetzlich ist: Ein neuronales Netz ist wie eine sehr komplizierte Tabellenkalkulation mit Millionen von anpassbaren Zahlen.
Daten gehen auf der einen Seite rein. Sie werden mit diesen Zahlen multipliziert, zusammenaddiert, durch einige mathematische Funktionen geleitet und produzieren schliesslich auf der anderen Seite eine Ausgabe. Der “Lern”-Teil besteht darin, all diese Zahlen anzupassen, bis die Ausgaben mit dem uebereinstimmen, was du willst.
Wenn du tiefer gehen moechtest: Das Netzwerk ist in Schichten organisiert. Jede Schicht enthaelt “Neuronen” (eigentlich nur mathematische Funktionen). Jedes Neuron nimmt Eingaben, multipliziert sie mit Gewichten, addiert sie und leitet das Ergebnis durch eine Aktivierungsfunktion. Die Magie passiert, weil das Netzwerk, wenn man viele Schichten uebereinander stapelt, unglaublich komplexe Muster lernen kann - Dinge, die kein Mensch von Hand programmieren koennte.
Der Begriff “neural” stammt von einer lockeren Analogie zu biologischen Neuronen im Gehirn. Nimm das nicht zu woertlich. Diese Systeme funktionieren nichts wie echte Gehirne. Die Metapher war nuetzlich fuer die urspruenglichen Forscher in den 1940ern, ist aber inzwischen etwas irrefuehrend geworden.
Training vs Inferenz#
Jedes KI-System hat zwei unterschiedliche Phasen, und ihre Verwechslung verursacht endlose Missverstaendnisse.
Training ist der teure Teil. Hier zeigst du dem Modell Millionen (oder Milliarden) von Beispielen und passt all diese internen Zahlen an, bis das Modell in seiner Aufgabe gut wird. Das Training von GPT-4 soll allein ueber 100 Millionen Dollar an Rechenleistung gekostet haben. Training findet einmal statt (oder periodisch, wenn du das Modell aktualisieren moechtest).
Inferenz ist der guenstige Teil - relativ gesehen. Hier benutzt du das trainierte Modell tatsaechlich. Du gibst ihm eine Eingabe, es produziert eine Ausgabe. Jedes Mal, wenn du mit ChatGPT chattest, machst du Inferenz. Die Zahlen des Modells sind eingefroren; es fuehrt nur Berechnungen aus.
Denk daran wie Ausbildung vs. Arbeiten. Training sind Jahre in Schule und Studium. Inferenz ist zur Arbeit zu erscheinen und das anzuwenden, was du gelernt hast. Die Investition erfolgt im Voraus; die Rendite kommt waehrend der Nutzung.
LLMs verstehen#
Was LLMs besonders macht#
Large Language Models sind eine spezifische Art von Deep-Learning-Modellen, die darauf trainiert sind, Text vorherzusagen. Das ist die Kernerkenntnis: Im Herzen versuchen LLMs nur, das naechste Wort (oder Token) in einer Sequenz vorherzusagen.
“Die Katze sass auf der ___” → “Matte” (wahrscheinlich)
Aber hier ist, was verrueckt ist: Wenn du dieses einfache Ziel auf Billionen von Woertern aus dem Internet, Buechern, Code und wissenschaftlichen Arbeiten trainierst, passiert etwas Bemerkenswertes. Das Modell lernt nicht nur Grammatik. Es lernt Fakten, Schlussfolgerungsmuster, Codierungskonventionen und sogar etwas, das wie gesunder Menschenverstand aussieht.
Das nennt man emergentes Verhalten - Faehigkeiten, die nicht explizit trainiert wurden, sondern aus dem Umfang des Trainings entstanden sind. Niemand hat GPT-4 programmiert, Gedichte zu schreiben oder Matheaufgaben zu loesen. Diese Faehigkeiten sind aus dem Ziel entstanden, das naechste Token wirklich, wirklich gut vorherzusagen.
Transformer und Attention#
Die Architektur, die moderne LLMs ermoeglicht hat, heisst Transformer, eingefuehrt in einem Paper von 2017 mit dem beruehmten Titel “Attention Is All You Need.”
Die Schluesselinnovation ist der Attention-Mechanismus. Fruehere Modelle verarbeiteten Text sequentiell - Wort fuer Wort, von links nach rechts. Attention erlaubt dem Modell, alle Woerter gleichzeitig zu betrachten und zu lernen, welche Woerter fuereinander relevant sind.
Einfaches Beispiel: “Das Tier ueberquerte die Strasse nicht, weil es zu muede war.”
Worauf bezieht sich “es”? Auf das Tier. Aber woher weiss das Modell das? Der Attention-Mechanismus lernt, dass “es” stark auf “Tier” und schwach auf “Strasse” achten sollte. Diese Faehigkeit, weitreichende Abhaengigkeiten zu erfassen, macht Transformer so maechtig fuer Sprache.
Token und Kontextfenster#
LLMs sehen nicht wirklich Woerter - sie sehen Token. Ein Token ist ein Textstueck, typischerweise ein Wort oder Teil eines Wortes. “Verstaendnis” koennte ein Token sein, waehrend “Ver” + “staend” + “nis” drei Token sein koennten, abhaengig vom Tokenizer des Modells.
Warum ist das wichtig? Weil Modelle begrenzte Kontextfenster haben - die maximale Anzahl von Token, die sie auf einmal verarbeiten koennen. Fruehes GPT-3 hatte einen 4K-Token-Kontext. GPT-4 Turbo erweiterte auf 128K. Claude kann 200K verarbeiten. Einige neuere Modelle behaupten Millionen.
Denk an das Kontextfenster als das Arbeitsgedaechtnis des Modells. Alles, was das Modell beruecksichtigen soll - deine Frage, alle Dokumente, die du teilst, die Gespraechshistorie - muss in dieses Fenster passen.
| Modell | Kontextfenster | Ungefaehre Entsprechung |
|---|---|---|
| GPT-3 (2020) | 4K Token | ~3.000 Woerter |
| GPT-4 Turbo | 128K Token | ~100.000 Woerter |
| Claude 3.5 | 200K Token | ~150.000 Woerter |
| Gemini 1.5 Pro | 1M+ Token | ~750.000 Woerter |
Prompt Engineering#
Ein Prompt ist einfach der Text, den du an ein LLM sendest. Deine Frage, deine Anweisungen, jeder Kontext, den du bereitstellst - das alles ist Teil des Prompts.
Prompt Engineering ist die Kunst (und zunehmend Wissenschaft), Prompts zu schreiben, die bessere Ergebnisse liefern. Es klingt albern - deine Fragen “engineeren”? - aber es macht wirklich einen Unterschied.
Einige Techniken, die funktionieren:
- Sei spezifisch. “Schreib ein Gedicht” vs. “Schreib ein 14-zeiliges Sonett ueber den Klimawandel im Stil von Shakespeare” - das zweite liefert dramatisch bessere Ergebnisse.
- Zeig Beispiele. Gib dem Modell ein paar Beispiele dessen, was du willst, bevor du nach der eigentlichen Ausgabe fragst. Das nennt man “Few-Shot Prompting.”
- Denk Schritt fuer Schritt. “Lass uns das Schritt fuer Schritt durchdenken” vor einem komplexen Problem hinzuzufuegen, verbessert die Genauigkeit. Das nennt man “Chain-of-Thought” Prompting.
- Weise eine Rolle zu. “Du bist ein Experten-Steuerberater” fokussiert die Antworten des Modells.
Temperature & Parameter#
Wenn du eine LLM-API verwendest, kannst du mehrere Parameter anpassen, die die Ausgabe beeinflussen. Der wichtigste ist Temperature.
Temperature kontrolliert die Zufaelligkeit. Bei Temperature 0 waehlt das Modell immer das wahrscheinlichste naechste Token - deterministisch, vorhersagbar, manchmal langweilig. Bei Temperature 1 oder hoeher ist es eher bereit, weniger wahrscheinliche Token zu waehlen - kreativer, vielfaeltiger, manchmal unsinnig.
- Temperature 0: “Die Hauptstadt von Frankreich ist Paris.”
- Temperature 1: “Die Hauptstadt von Frankreich ist Paris, diese prachtvolle Stadt der Lichter, wo Revolution und Romantik durch Kopfsteinpflasterstrassen tanzen…”
Andere gaengige Parameter:
- Top-p (Nucleus Sampling): Eine weitere Moeglichkeit, Zufaelligkeit zu kontrollieren, indem eingeschraenkt wird, welche Token beruecksichtigt werden.
- Max tokens: Wie lang die Antwort sein kann.
- Stop sequences: Teilt dem Modell mit, wann es aufhoeren soll zu generieren.
- Frequency/presence penalty: Reduziert Wiederholungen.
Halluzinationen#
LLMs erfinden Dinge. Sie behaupten Unwahrheiten mit voller Ueberzeugung. Sie zitieren Paper, die nicht existieren. Sie erfinden Statistiken. Das nennt man Halluzination, und es ist kein Bug, der behoben wird - es ist eine Konsequenz davon, wie diese Modelle funktionieren.
Denk daran: LLMs werden trainiert, plausiblen Text vorherzusagen, nicht wahren Text. Wenn du nach einem Thema fragst, zu dem das Modell begrenzte Trainingsdaten hat, wird es etwas generieren, das korrekt klingt. Das Modell hat keinen internen Faktenchecker, keine Verbindung zur Grundwahrheit, keine Moeglichkeit zu sagen “Ich weiss es nicht.”
Warum passiert das?
- Trainingsziel: Sage das naechste Token vorher, nicht verifiziere die Wahrheit.
- Wahrscheinlichkeitsverteilung: Das Modell sampelt aus Moeglichkeiten. Selbst wenn die wahre Antwort am wahrscheinlichsten ist, koennte das Sampling etwas anderes waehlen.
- Kein Bewusstsein fuer Wissensgrenzen: Das Modell weiss nicht zuverlaessig, wo die Grenzen seines Wissens liegen.
Strategien zur Reduzierung von Halluzinationen:
- Verwende RAG, um Antworten in echten Dokumenten zu verankern
- Bitte das Modell, Quellen zu zitieren und verifiziere sie
- Niedrigere Temperature fuer faktische Aufgaben
- Verwende strukturierte Ausgaben, die die Antwort einschraenken
- Implementiere Faktenpruefungsschichten
Die Modelllandschaft#
Open vs Closed Models#
Closed Source: Du kannst das Modell per API nutzen, aber die Gewichte nicht sehen, die Architektur nicht modifizieren oder es selbst ausfuehren. OpenAIs GPT-4, Anthropics Claude, Googles Gemini.
Open Source/Open Weights: Gewichte sind oeffentlich verfuegbar. Du kannst sie herunterladen, lokal ausfuehren, feinabstimmen, modifizieren. Metas Llama, Mistral, Alibabas Qwen, DeepSeek und viele andere.
Die Unterscheidung ist wichtig, aber nuanciert:
- “Open Weights” bedeutet, du kannst das Modell herunterladen und ausfuehren
- “Open Source” bedeutet traditionell, dass auch der Trainingscode und die Daten verfuegbar sind (selten bei grossen Modellen)
- Lizenzen variieren - einige offene Modelle haben kommerzielle Einschraenkungen
Warum veroeffentlicht Meta Llama kostenlos? Strategische Gruende: Komplementaerprodukte zur Ware machen, Oekosystem aufbauen, Talente anziehen, Standards setzen. Die zynische Sicht: Sie koennen nicht mit OpenAI bei API-Einnahmen konkurrieren, also konkurrieren sie, indem sie die Modellschicht kostenlos machen und woanders profitieren.
Multimodale Modelle#
Fruehe LLMs verstanden nur Text. Multimodale Modelle verstehen mehrere Datentypen - Text, Bilder, Audio, Video.
GPT-4V kann ein Foto betrachten und es beschreiben. Claude kann Diagramme und Schaubilder analysieren. Gemini kann Videos ansehen. Das ist nicht nur eine Spielerei - es eroeffnet voellig neue Anwendungsfaelle:
- Mach einen Screenshot eines Bugs und bitte um Hilfe beim Debuggen
- Lade ein handgezeichnetes Diagramm hoch und bekomme Code
- Analysiere medizinische Bilder
- Verarbeite Videos zur Inhaltsmoderation
- Sprachschnittstellen ohne separate Speech-to-Text-Umwandlung
Die Architekturen variieren. Einige Modelle werden nativ multimodal trainiert. Andere verbinden separate Vision- und Sprachmodelle. Der Unterschied ist wichtig fuer die Leistung, aber nicht fuer die meisten Benutzer.
Reasoning-Modelle#
Standard-LLMs generieren Antworten Token fuer Token ohne explizites “Nachdenken.” Reasoning-Modelle verfolgen einen anderen Ansatz - sie verwenden zusaetzliche Rechenleistung, um Probleme durchzudenken, bevor sie antworten.
OpenAIs o1- und o3-Modelle haben diesen Ansatz pioniert. Anstatt sofort zu antworten, generieren diese Modelle interne Gedankenketten (manchmal vor Benutzern verborgen), erwaegen mehrere Ansaetze und ueberpruefen ihre Arbeit, bevor sie eine endgueltige Antwort liefern.
Die Ergebnisse sind bemerkenswert: Reasoning-Modelle uebertreffen Standard-LLMs dramatisch bei Mathematik, Programmierung, Wissenschaft und Logikproblemen. o3 erreichte Punktzahlen bei bestimmten Benchmarks, die als Jahre entfernt galten.
Der Kompromiss: Reasoning-Modelle sind langsamer und teurer. Eine einfache Frage, die GPT-4 sofort beantwortet, koennte o1 mehrere Sekunden (und das 10-fache der Kosten) kosten, waehrend es “nachdenkt.” Fuer einfache Aufgaben ist das Verschwendung. Fuer schwierige Probleme lohnt es sich.
Wann Reasoning-Modelle verwenden:
- Komplexe Mathematik- oder Logikprobleme
- Mehrstufige Programmierherausforderungen
- Aufgaben, die sorgfaeltige Analyse erfordern
- Alles, wo Genauigkeit wichtiger ist als Geschwindigkeit
Wann Standard-LLMs besser sind:
- Einfache Fragen und Antworten
- Kreatives Schreiben
- Echtzeitanwendungen
- Kostensensitive Anwendungsfaelle
KI-Verbraucherprodukte#
Bevor wir tiefer in technische Details eintauchen, lass uns die Produkte kartieren, die du wahrscheinlich schon benutzt hast:
ChatGPT (OpenAI) - Das Produkt, das die Mainstream-KI-Welle gestartet hat. Zugang zu GPT-4, o1, DALL-E fuer Bilder und verschiedene Plugins. Der Benchmark, mit dem alle anderen verglichen werden.
Claude (Anthropic) - Bekannt fuer starkes Schreiben, lange Kontextfenster und nuanciertes Schlussfolgern. Claude.ai ist die Verbraucheroberflaeche; die API betreibt viele Anwendungen.
Gemini (Google) - Tief integriert in Googles Oekosystem. Zugang ueber gemini.google.com und zunehmend eingebettet in Search, Docs, Gmail und Android.
Copilot (Microsoft) - Microsofts KI-Schicht ueber ihre Produkte. Anders als GitHub Copilot (Programmierung) - dies ist der Verbraucherassistent in Windows, Edge und Microsoft 365.
Perplexity - KI-native Suchmaschine. Beantwortet Fragen mit Zitaten und Quellen. Ein Blick darauf, was Suche werden koennte.
Weitere, die man kennen sollte: Grok (xAI, integriert in X/Twitter), Pi (Inflection), Le Chat (Mistral), DeepSeek Chat und viele regionale/spezialisierte Alternativen.
Modelle lokal ausfuehren#
Warum lokal ausfuehren?#
Cloud-Modelle laufen auf den Servern von jemand anderem. Du sendest Anfragen uebers Internet und zahlst pro Nutzung. OpenAI, Anthropic, Google - das ist ihr Geschaeft.
Lokale Modelle laufen auf deiner eigenen Hardware. Dein Laptop, deine Server, dein Rechenzentrum. Daten verlassen nie deine Kontrolle.
Warum lokal ausfuehren?
- Datenschutz: Sensible Daten bleiben vor Ort
- Kosten: Keine API-Gebuehren (aber Hardware ist nicht kostenlos)
- Latenz: Keine Netzwerk-Roundtrips
- Verfuegbarkeit: Funktioniert offline, keine Rate-Limits
- Kontrolle: Keine Nutzungsbedingungen, keine Inhaltsfilter, die du nicht gewaehlt hast
Die Luecke zwischen lokal und Cloud ist dramatisch geschrumpft. Fuer viele praktische Anwendungen sind lokale Modelle gut genug - besonders fuer Programmierung, Schreiben und Analyseaufgaben.
Der Kompromiss: Frontier-Faehigkeiten erfordern immer noch die Cloud. Wenn du die absolut beste Leistung bei schwierigen Reasoning-Aufgaben brauchst, sind GPT-4, Claude oder Gemini nur in der Cloud verfuegbar. Aber diese Luecke wird mit jeder Veroeffentlichung kleiner.
Ollama#
Ollama ist zum De-facto-Standard fuer das lokale Ausfuehren von Modellen geworden. Es macht, was frueher ein komplexer Prozess war, trivial einfach.
# Installiere und fuehre ein Modell mit zwei Befehlen aus
ollama pull llama3.2
ollama run llama3.2Das war’s. Du chattest mit einem faehigen LLM, das vollstaendig auf deinem Rechner laeuft.
Ollama uebernimmt die Komplexitaet: Modelle herunterladen, Speicher verwalten, fuer deine Hardware optimieren und sowohl eine CLI als auch eine lokale API bereitstellen. Es unterstuetzt Dutzende von Modellen - Llama, Mistral, Qwen, Phi, CodeLlama und viele mehr.
Hauptmerkmale:
- Einfache CLI-Schnittstelle
- OpenAI-kompatible API (einfach in bestehenden Code einzutauschen)
- Modellbibliothek mit Ein-Befehl-Downloads
- Funktioniert auf Mac, Linux und Windows
- GPU-Beschleunigung, wenn verfuegbar
Fuer Entwickler bedeutet Ollamas lokale API, dass du gegen lokale Modelle entwickeln und fuer die Produktion zu Cloud-APIs wechseln kannst - oder umgekehrt - mit minimalen Code-Aenderungen.
Hardware-Ueberlegungen#
Modelle lokal auszufuehren erfordert Hardware. Hier ist, was wichtig ist:
GPU vs CPU: GPUs beschleunigen Inferenz dramatisch. Ein Modell, das auf der CPU 30 Sekunden pro Antwort braucht, koennte auf der GPU 2 Sekunden brauchen. Apple Silicon Macs verwischen diese Grenze - ihr Unified Memory und Neural Engine machen sie ueberraschend faehig fuer lokale Inferenz.
Speicher (VRAM/RAM): Das ist normalerweise der limitierende Faktor. Modelle muessen in den Speicher passen. Ein 7B-Parameter-Modell braucht ungefaehr 4-8GB. Ein 70B-Modell braucht 35-70GB. Quantisierung (unten besprochen) reduziert diese Anforderungen.
Quantisierung: Reduzierung der Praezision von Modellgewichten von 32-Bit auf 16-Bit, 8-Bit oder sogar 4-Bit. Das verkleinert Speicheranforderungen und beschleunigt Inferenz mit minimalem Qualitaetsverlust. Die meisten lokalen Modelle werden in quantisierten Formaten (GGUF, GPTQ, AWQ) verteilt.
Praktische Orientierung:
- Mac mit 16GB+ RAM: Kann 7B-13B Modelle bequem ausfuehren
- Mac mit 32GB+ RAM: Kann 30B+ Modelle ausfuehren
- PC mit RTX 3090/4090 (24GB VRAM): Kann die meisten Modelle bis 70B (quantisiert) ausfuehren
- Keine GPU: Funktioniert trotzdem, nur langsamer. In Ordnung fuer Entwicklung und Experimente.
Anpassung & Wissen#
Fine-Tuning vs RAG#
Du hast ein Basis-LLM. Du willst es fuer deinen spezifischen Anwendungsfall besser machen. Zwei Hauptansaetze:
Fine-Tuning#
Nimm ein bestehendes Modell und trainiere es auf deinen eigenen Daten weiter. Die Gewichte des Modells aendern sich tatsaechlich. Nach dem Fine-Tuning “weiss” das Modell deine Informationen nativ.
Vorteile: Schnelle Inferenz, tiefe Integration von Wissen, kann neue Stile oder Verhaltensweisen lernen. Nachteile: Teuer, erfordert ML-Expertise, Wissen kann veralten, Risiko des katastrophalen Vergessens (Modell wird bei anderen Aufgaben schlechter).
RAG (Retrieval-Augmented Generation)#
Behalte das Modell wie es ist. Wenn eine Frage kommt, durchsuche zuerst deine Wissensbasis nach relevanten Dokumenten, dann fuege diese Dokumente zusammen mit der Frage in den Prompt ein.
Vorteile: Guenstiger, Wissen bleibt aktuell, kein Training erforderlich, einfach zu pruefen (du kannst sehen, was abgerufen wurde). Nachteile: Langsamer (zweistufiger Prozess), begrenzt durch das Kontextfenster, Abrufqualitaet ist sehr wichtig.
Embeddings & Vektor-DBs#
Das ist die Technologie, die RAG funktionieren laesst - und sie ist wirklich clever.
Ein Embedding ist eine Moeglichkeit, Text (oder Bilder oder alles andere) als Liste von Zahlen darzustellen - ein Vektor. Die Magie: Aehnliche Dinge haben aehnliche Vektoren. “Hund” und “Welpe” haben Vektoren, die nah beieinander liegen. “Hund” und “Demokratie” sind weit auseinander.
Du erstellst Embeddings mit Embedding-Modellen (anders als LLMs, obwohl einige LLMs Embedding-Faehigkeiten haben). OpenAI, Cohere, Voyage und viele andere bieten Embedding-APIs an. Open-Source-Optionen wie BGE und E5 funktionieren auch grossartig.
Eine Vektordatenbank ist eine Datenbank, die fuer das Speichern und Durchsuchen dieser Vektoren optimiert ist. Wenn du fragst “Was ist unsere Rueckgaberichtlinie?”, macht das System:
- Konvertiert deine Frage in einen Vektor
- Durchsucht die Vektordatenbank nach aehnlichen Vektoren
- Gibt die Dokumente zurueck, die diese Vektoren repraesentieren
- Fuettert diese Dokumente zusammen mit deiner Frage in das LLM
Beliebte Vektordatenbanken sind Pinecone, Weaviate, Chroma, Qdrant und Milvus. Postgres mit pgvector funktioniert ueberraschend gut fuer viele Anwendungsfaelle.
Evaluation#
Benchmarks#
Woher weisst du, ob ein Modell “besser” ist als ein anderes? Benchmarks versuchen, das zu beantworten, indem sie Modelle bei standardisierten Aufgaben testen.
Gaengige Benchmarks:
- MMLU (Massive Multitask Language Understanding): Multiple-Choice-Fragen ueber 57 Faecher. Testet Allgemeinwissen.
- HumanEval: Programmierprobleme. Testet Programmierfaehigkeiten.
- GSM8K: Mathematische Textaufgaben auf Grundschulniveau. Testet mathematisches Schlussfolgern.
- HellaSwag: Gesunder-Menschenverstand-Schlussfolgern ueber alltaegliche Situationen.
- TruthfulQA: Testet, ob Modelle wahrheitsgerechte Antworten geben vs. ueberzeugend klingenden Unsinn.
Das Problem mit Benchmarks: Sie sind manipulierbar. Modelle koennen speziell trainiert werden, um bei beliebten Benchmarks gut abzuschneiden, ohne sich tatsaechlich bei realen Aufgaben zu verbessern. Ein Modell, das 90% bei MMLU erzielt, koennte immer noch bei deinem spezifischen Anwendungsfall versagen.
Evals#
Evals (Evaluierungen) sind Tests, die du fuer deinen spezifischen Anwendungsfall erstellst. Anders als Benchmarks messen Evals, was fuer deine Anwendung tatsaechlich wichtig ist.
Baust du einen Kundenservice-Bot? Deine Evals koennten testen:
- Beantwortet er Fragen aus deiner FAQ korrekt?
- Eskaliert er angemessen an Menschen, wenn noetig?
- Bleibt er on-brand und folgt deinen Ton-Richtlinien?
- Weigert er sich, Versprechen zu machen, die das Unternehmen nicht halten kann?
Warum Evals wichtig sind:
- Regressionserkennung: Wenn du Prompts aenderst oder Modelle wechselst, fangen Evals Probleme auf, bevor Benutzer es tun.
- Vergleich: Objektiv verschiedene Modelle, Prompts oder Ansaetze fuer deinen Anwendungsfall vergleichen.
- Iteration: Du kannst nicht verbessern, was du nicht messen kannst. Evals machen Verbesserung systematisch.
Gute Evals bauen:
- Beginne mit echten Benutzeranfragen und erwarteten Antworten
- Schliesse Randfaelle und gegnerische Beispiele ein
- Teste sowohl, was das Modell tun soll ALS AUCH was es nicht tun soll
- Automatisiere, damit du Evals bei jeder Aenderung ausfuehren kannst
LLM als Richter#
Hier ist eine clevere Technik: Verwende ein LLM, um die Ausgaben eines anderen LLM zu bewerten.
Anstatt Hunderte von Antworten manuell zu ueberpruefen, kannst du ein Modell als Richter einsetzen:
Du bewertest die Qualitaet der Antwort eines KI-Assistenten.
Benutzerfrage: {question}
Assistentenantwort: {response}
Bewerte die Antwort nach:
1. Genauigkeit (1-5): Sind die Informationen korrekt?
2. Hilfsbereitschaft (1-5): Hilft sie dem Benutzer tatsaechlich?
3. Klarheit (1-5): Ist sie leicht zu verstehen?
Erklaere deine Argumentation, dann gib Punkte.Warum das funktioniert:
- Skaliert auf Tausende von Bewertungen
- Konsistenter als menschliche Pruefer (weniger Ermuedung)
- Kann nuancierte Qualitaeten bewerten, die schwer programmatisch zu testen sind
- Guenstiger und schneller als menschliche Bewertung
Einschraenkungen:
- Das Richter-Modell hat seine eigenen Verzerrungen und Einschraenkungen
- Kann Fehler uebersehen, die es selbst machen wuerde
- Kaempft mit domaenenspezifischer Genauigkeit ohne Verankerung
- Kein Ersatz fuer menschliche Bewertung insgesamt - eher eine Ergaenzung
Agenten & Automatisierung#
Was sind Agenten?#
Der Begriff “Agent” wird oft herumgeworfen. Hier ist eine Arbeitsdefinition: Ein Agent ist ein LLM, das Aktionen in der Welt ausfuehren kann, nicht nur Text generieren.
Ein Chatbot beantwortet deine Fragen. Ein Agent koennte deine Fragen beantworten und eine Restaurantreservierung machen, eine E-Mail senden, eine Datenbank abfragen oder Code schreiben und ausfuehren, um ein Problem zu loesen.
Was macht etwas zu einem Agenten vs. nur einem LLM?
- Ziele: Agenten arbeiten auf Ziele hin, nicht nur auf Prompts reagieren.
- Aktionen: Agenten koennen Dinge tun, nicht nur Dinge sagen.
- Autonomie: Agenten treffen Entscheidungen darueber, wie sie Ziele erreichen.
- Schleifen: Agenten laufen oft in Schleifen - beobachten, denken, handeln, wiederholen.
Das einfachste Agenten-Muster: Gib einem LLM Zugang zu Werkzeugen und lass es entscheiden, welche Werkzeuge es benutzt. “Finde Fluege von London nach Tokio naechste Woche, pruefe meinen Kalender und buche die guenstigste Option, die mit meinem Zeitplan funktioniert.” Der Agent zerlegt das, ruft Flug-APIs auf, ruft Kalender-APIs auf und fuehrt die Buchung aus.
Agenten vs Workflows#
Eine wichtige Unterscheidung, die oft verschwimmt:
Workflows sind deterministisch. Du definierst die Schritte: zuerst mach A, dann mach B, dann wenn X mach C sonst mach D. Das LLM koennte einzelne Schritte antreiben, aber die Orchestrierung ist codiert.
1. Entitaeten aus E-Mail extrahieren (LLM)
2. Kunden in Datenbank nachschlagen (Code)
3. Antwortentwurf generieren (LLM)
4. Zur menschlichen Ueberpruefung senden (Code)Agenten sind autonom. Du gibst ihnen ein Ziel und Werkzeuge, und sie finden die Schritte heraus. Das LLM entscheidet, was als naechstes zu tun ist, basierend auf dem aktuellen Zustand.
Ziel: "Loesung dieser Kundenbeschwerde"
Werkzeuge: [email, database, refund_system, escalation]
→ Agent entscheidet, was zu tun ist, in welcher ReihenfolgeWann Workflows verwenden:
- Vorhersagbare, gut verstandene Prozesse
- Wenn du Zuverlaessigkeit und Pruefbarkeit brauchst
- Regulierte Umgebungen
- Hochvolumige, wenig komplexe Aufgaben
Wann Agenten verwenden:
- Neuartige oder variable Aufgaben
- Wenn die Schritte nicht im Voraus bekannt sind
- Komplexes Schlussfolgern erforderlich
- Wenn Flexibilitaet wichtiger ist als Vorhersagbarkeit
Die Kostengleichung: Workflows sind deutlich guenstiger. Du zahlst fuer eine feste Anzahl von LLM-Aufrufen pro Durchlauf - vorhersagbar, optimierbar, pruefbar. Agenten sind teuer, weil sie denken. Jeder Entscheidungspunkt - “welches Werkzeug soll ich benutzen?”, “hat das funktioniert?”, “was kommt als naechstes?” - ist ein LLM-Aufruf. Ein Workflow, der 3 LLM-Aufrufe macht, koennte zu einem Agenten werden, der 15-30 Aufrufe macht, um das gleiche Problem zu loesen, weil der Agent darueber nachdenkt, wie er es loest, anstatt nur vordefinierte Schritte auszufuehren. Fuer gut verstandene Aufgaben im grossen Massstab gewinnen Workflows bei den Kosten. Fuer komplexe, variable Probleme, bei denen du die Schritte nicht vordefinieren kannst, sind Agenten die Praemie wert.
Tool Use & Function Calling#
Damit Agenten Aktionen ausfuehren koennen, brauchen sie Tools - Funktionen, die sie aufrufen koennen. Diese Faehigkeit wird normalerweise Function Calling oder Tool Use genannt.
So funktioniert es:
- Du definierst Tools mit Namen, Beschreibungen und Parametern (normalerweise als JSON-Schemas)
- Du fuegst diese Definitionen in deinen Prompt/API-Aufruf ein
- Das Modell kann waehlen, ein Tool zu “aufrufen”, anstatt Text zu generieren
- Dein Code fuehrt die Funktion aus und gibt Ergebnisse an das Modell zurueck
- Das Modell verwendet diese Ergebnisse, um fortzufahren
Beispiel Tool-Definition:
{
"name": "get_weather",
"description": "Get current weather for a city",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "City name"},
"units": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["city"]
}
}Wenn du fragst “Wie ist das Wetter in Tokio?”, halluziniert das Modell nicht - es ruft get_weather(city="Tokyo") auf, bekommt echte Daten und antwortet mit Fakten.
Jeder grosse Modellanbieter unterstuetzt jetzt Function Calling: OpenAI, Anthropic, Google und andere. Die Syntax variiert leicht, aber das Konzept ist dasselbe.
MCP-Protokoll#
Model Context Protocol (MCP) ist ein offener Standard zum Verbinden von KI-Modellen mit Tools und Datenquellen. Stell es dir vor wie USB-C fuer KI - ein universeller Stecker, der bedeutet, dass du nicht fuer jedes Geraet ein anderes Kabel brauchst.
Vor MCP war jede Integration individuell. Willst du, dass deine KI auf GitHub zugreift? Schreib eine GitHub-Integration. Salesforce? Noch eine Integration. Deine interne Datenbank? Noch eine weitere. Das skaliert nicht.
MCP definiert einen Standardweg fuer KI-Clients (wie Claude, ChatGPT oder dein eigener Agent), Tools von MCP-Servern zu entdecken und zu nutzen. Ein MCP-Server koennte bereitstellen:
- Tools: Funktionen, die die KI aufrufen kann
- Resources: Daten, die die KI lesen kann
- Prompts: Vorlagen fuer gaengige Aufgaben
Die Implikationen sind bedeutend:
- Baue einmal einen MCP-Server, jede kompatible KI kann ihn nutzen
- Tools werden portabel und wiederverwendbar
- Sicherheit und Berechtigungen koennen standardisiert werden
- Das Oekosystem potenziert sich - mehr Server bedeuten faehigere Agenten
Fuer mehr zu MCP habe ich einen tieferen Einblick geschrieben: MCP Server: Der USB-C-Moment fuer KI-Agenten.
Agentische Muster#
Mit der Reifung von Agenten sind gaengige Muster entstanden:
ReAct (Reason + Act): Der Agent wechselt zwischen Schlussfolgern (“Ich muss die Bestellhistorie des Benutzers finden”) und Handeln (die Bestell-API aufrufen). Dieser explizite Schlussfolgerungsschritt verbessert die Zuverlaessigkeit.
Planung: Vor dem Handeln erstellt der Agent einen Plan: “Um das zu loesen, muss ich 1) die Bestellung nachschlagen, 2) den Bestand pruefen, 3) die Rueckerstattung verarbeiten, 4) eine Bestaetigung senden.” Plaene koennen vor der Ausfuehrung validiert werden.
Reflexion: Nach Abschluss einer Aufgabe (oder Scheitern) ueberdenkt der Agent, was passiert ist: “Die Rueckerstattung ist fehlgeschlagen, weil die Bestellung zu alt war. Ich haette zuerst die Rueckgaberichtlinie ueberpruefen sollen.” Das ermoeglicht Lernen und Selbstkorrektur.
Tool-Auswahl: Wenn ein Agent viele Tools hat, wird die Auswahl des richtigen nicht-trivial. Techniken beinhalten Tool-Beschreibungen, Few-Shot-Beispiele und hierarchische Tool-Organisation.
Human-in-the-Loop: Fuer risikoreiche Aktionen koennen Agenten pausieren und menschliche Genehmigung anfordern, bevor sie fortfahren. Gute Agenten wissen, wenn sie unsicher sind.
Skills#
Skills sind wiederverwendbare, spezialisierte Prompts, die erweitern, was ein Agent tun kann. Stell sie dir als “Expertenmodi” vor, die du in einen Agenten einstecken kannst - ein Skill fuer Code-Reviews, ein Skill fuer Dokumentation schreiben, ein Skill fuer die Analyse von Sicherheitsluecken.
Anders als Tools (die Funktionen sind, die Dinge tun) sind Skills Anweisungen, die formen, wie der Agent denkt und antwortet. Ein Tool ruft eine API auf. Ein Skill sagt dem Agenten “wenn nach X gefragt wird, gehe so vor, beruecksichtige diese Faktoren und formatiere deine Antwort so.”
Warum Skills wichtig sind:
- Spezialisierung ohne Fine-Tuning: Du bekommst Expertenverhalten, ohne ein neues Modell zu trainieren.
- Kombinierbarkeit: Mische und kombiniere Skills fuer verschiedene Aufgaben.
- Teilbarkeit: Ein gut erstellter Skill kann teamuebergreifend, projektuebergreifend oder sogar oeffentlich geteilt werden.
- Kontexteffizienz: Anstatt deine Anforderungen jedes Mal zu erklaeren, kodiere sie einmal in einem Skill.
Wo Skills leben:
Skills koennen an verschiedenen Stellen in den Kontext des Agenten eingefuegt werden:
- System-Prompt: Der haeufigste Ansatz. Skills werden Teil der Basisanweisungen des Agenten, immer aktiv.
- User-Message-Praefix: Dynamisch den Benutzeranfragen vorangestellt. Nuetzlich fuer aufgabenspezifische Skills.
- Tool-Beschreibungen: Skills koennen in Tool-Definitionen eingebettet werden und leiten, wie der Agent bestimmte Tools verwendet.
- MCP-Prompts: MCP-Server koennen Skills als “Prompts” bereitstellen - wiederverwendbare Vorlagen, die Clients entdecken und aufrufen koennen.
Wie Skills den Kontext beeinflussen:
Jeder Skill verbraucht Token aus deinem Kontextfenster. Das erzeugt Kompromisse:
- Mehr Skills = faehigerer Agent, aber weniger Platz fuer Gespraechsverlauf
- Detaillierte Skills = besseres Verhalten, aber hoehere Token-Kosten pro Anfrage
- Immer-aktive Skills vs. On-Demand-Skills = Zuverlaessigkeit vs. Effizienz
Intelligente Agent-Frameworks verwalten dies, indem sie Skills dynamisch laden - relevante Skills basierend auf der Aufgabe aktivieren und andere deaktivieren.
Beispiel-Skill-Struktur:
## Code-Review-Skill
Beim Ueberpruefen von Code solltest du:
1. Nach Sicherheitsluecken suchen (Injection, XSS, Auth-Probleme)
2. Leistungsprobleme identifizieren
3. Lesbarkeit und Wartbarkeit bewerten
4. Spezifische Verbesserungen mit Code-Beispielen vorschlagen
Formatiere dein Review als:
- Zusammenfassung (1-2 Saetze)
- Kritische Probleme (falls vorhanden)
- Vorschlaege (Aufzaehlungsliste)
- GesamtbewertungCoding-Agenten#
Warum sie wichtig sind#
Coding-Agenten repraesentieren eine der greifbarsten Anwendungen von KI - sie schreiben tatsaechlich Code, und der Code funktioniert tatsaechlich. Das ist nicht theoretisch; Entwickler liefern Features schneller wegen dieser Tools.
Die Auswirkung ist sofort und messbar: weniger Zeit fuer Boilerplate, schnelleres Debugging, einfachere Erkundung unbekannter Codebasen. Fuer viele Entwickler sind Coding-Agenten so unverzichtbar geworden wie ihre IDE.
Die Landschaft#
Claude Code - Anthropics Terminal-basierter Coding-Agent. Lebt in deiner CLI, versteht deine gesamte Codebasis, kann Dateien lesen, Code schreiben, Befehle ausfuehren und auf Feedback iterieren. Entworfen fuer Entwickler, die im Terminal leben.
Cursor - Eine KI-native IDE, von Grund auf um KI-Assistenz herum gebaut. Nicht nur Autovervollstaendigung - du kannst mit deiner Codebasis chatten, ganze Features generieren und die KI grosse Aenderungen ueber Dateien hinweg machen lassen. Das Naechste, was es zu Pair-Programming mit einer KI gibt.
GitHub Copilot - Das Original und am weitesten verbreitet. Begann als Autovervollstaendigung, entwickelte sich zu Chat, beinhaltet jetzt Copilot Workspace fuer groessere Aufgaben. Tiefe GitHub-Integration.
Windsurf - Codeiums KI-IDE, positioniert sich als Alternative zu Cursor. Starke Betonung auf Geschwindigkeit und Verstaendnis grosser Codebasen.
Cody (Sourcegraph) - Fokussiert auf Codebasis-Verstaendnis. Besonders stark fuer grosse, komplexe Codebasen, wo Kontext kritisch ist.
Continue - Open-Source-Coding-Assistent, der mit jeder IDE funktioniert. Bring dein eigenes Modell mit (lokal oder Cloud). Gut fuer Teams, die Kontrolle ueber ihr KI-Setup wollen.
OpenCode - Open-Source-Alternative zu Claude Code. Terminal-basiert, modell-agnostisch, Community-getriebene Entwicklung.
Aider - Ein weiterer exzellenter Open-Source-Terminal-Coding-Agent. Bekannt fuer seine Git-Integration und Faehigkeit, koherent mit mehreren Dateien zu arbeiten.
Naechste Schritte#
Du hast es durch die Grundlagen geschafft. Was kommt als naechstes?
Dinge bauen#
- Fang einfach an. Nutze eine API (OpenAI, Anthropic, etc.) und baue einen einfachen Chatbot oder ein RAG-System. Ueberdenke den Stack anfangs nicht.
- Probiere lokale Modelle. Installiere Ollama und fuehre Llama oder Qwen auf deinem Laptop aus. Es ist ueberraschend einfach.
- Erkunde Agenten. Schau dir Frameworks wie LangChain, LlamaIndex oder CrewAI zum Bauen von Agentensystemen an.
- Lerne MCP. Die offizielle Dokumentation ist solide.
- Baue Evals frueh. Was auch immer du baust, erstelle Evals vom ersten Tag an. Du wirst dir spaeter danken.
Das Feld verstehen#
- Folge der Forschung. ArXiv-Paper, Google Scholar-Alerts zu Themen, die dich interessieren.
- Lies den Hype kritisch. Die meisten “Durchbrueche” sind inkrementell. Achte auf reproduzierbare Ergebnisse und echte Benchmarks.
- Experimentiere selbst. Intuition darueber, was funktioniert, kommt aus praktischer Erfahrung, nicht aus Lesen.
Ressourcen#
- Hugging Face - Modelle, Datensaetze und eine unglaubliche Community
- Papers With Code - Forschungspapiere mit Implementierungen
- Ollama - Kinderleichtes lokales Modelllaufen
- LangChain / LlamaIndex - Beliebte Frameworks zum Bauen mit LLMs
- Model Context Protocol - Die MCP-Spezifikation und SDKs
- Chatbot Arena - Vergleiche Modelle Kopf an Kopf mit menschlicher Abstimmung
KI im Jahr 2026 ist gleichzeitig ueberbewertet und unterbewertet. Die Technologie ist wirklich transformativ - aber sie ist auch wirklich begrenzt. LLMs erfinden Dinge. Agenten sind instabil. Kosten sind hoch. Fortschritt ist schnell, aber ungleichmaessig.
Der beste Ansatz ist pragmatisch: Verstehe die Grundlagen, experimentiere mit echten Problemen, bleibe skeptisch gegenueber grossen Behauptungen und baue Dinge. Die Menschen, die in dieser Aera gedeihen werden, sind nicht die, die jedes Akronym aufsagen koennen - es sind die, die Produkte liefern koennen, die tatsaechlich funktionieren.
Jetzt geh und bau etwas.





