Tag 16. Was wäre, wenn der KI-Gegner tatsächlich aus seinen Niederlagen gegen dich lernen würde?
Kein Minimax-Algorithmus, der von Anfang an perfekt spielt. Kein zufälliger Spieler. Etwas, das dumm anfängt, beobachtet was funktioniert und nach und nach herausfindet, wie es dich schlagen kann. Das ist Q-Learning. Und das wollte ich in das einfachste Spiel überhaupt einbauen.
Der Prompt#
“Baue ein Tic-Tac-Toe-Spiel mit einer Q-Learning-KI, die aus jedem Spiel lernt, ihr Gehirn im localStorage speichert und Echtzeit-Statistiken anzeigt”
Wie Es Gebaut Wurde#
Watchfire hat das in 4 Aufgaben aufgeteilt:
- Grundgerüst des Next.js-Projekts mit dem Spielbrett und dem grundlegenden Layout
- Q-Learning-KI mit Epsilon-Greedy-Strategie und localStorage-Persistenz für die Q-Table
- Statistik-Dashboard, Visualisierung des KI-Gehirns und ein Trainingsmodus für massenhaftes Selbstspiel
- Schwierigkeitsgrade, Hervorhebung von Gewinnzügen, Soundeffekte und finaler Feinschliff
Die erste Aufgabe gab mir ein spielbares Tic-Tac-Toe. Nichts Besonderes. Die zweite Aufgabe wurde dann interessant, weil die KI jetzt tatsächlich Zustands-Aktions-Werte nach jedem Spiel aktualisierte. Gewinn ein Spiel gegen sie und sie passt sich an. Besiege sie zweimal auf die gleiche Weise und sie fängt an, diesen Zug zu blockieren. Die Q-Table wächst mit jeder Partie.
Die Aufgaben 3 und 4 verwandelten das Ganze von einem Lernexperiment in etwas, bei dem man die Evolution tatsächlich beobachten kann. Die Gehirn-Visualisierung zeigt Q-Values für jede Zelle, das Statistik-Dashboard verfolgt Gewinn-/Verlust-/Unentschieden-Raten über die Zeit, und der Trainingsmodus erlaubt es, tausende Selbstspiel-Partien laufen zu lassen, um die Ausbildung der KI vorzuspulen.
Was Ich Bekommen Habe#
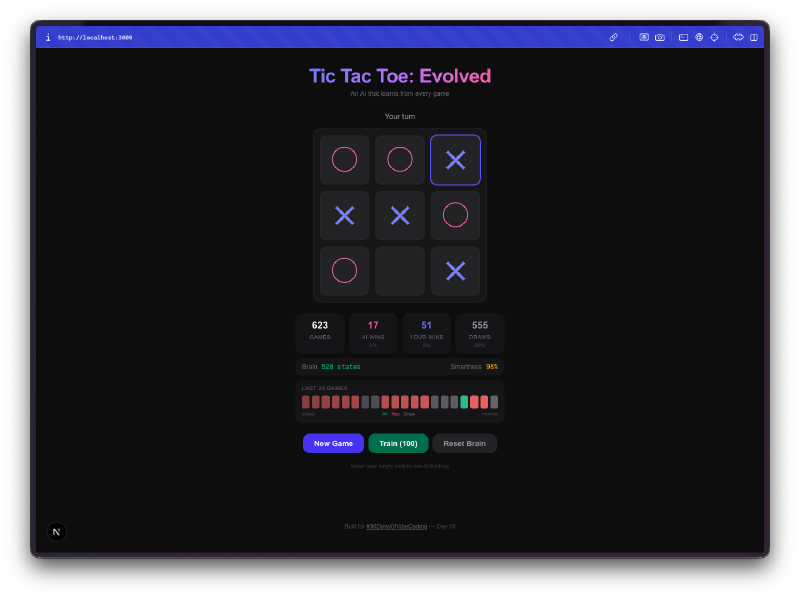
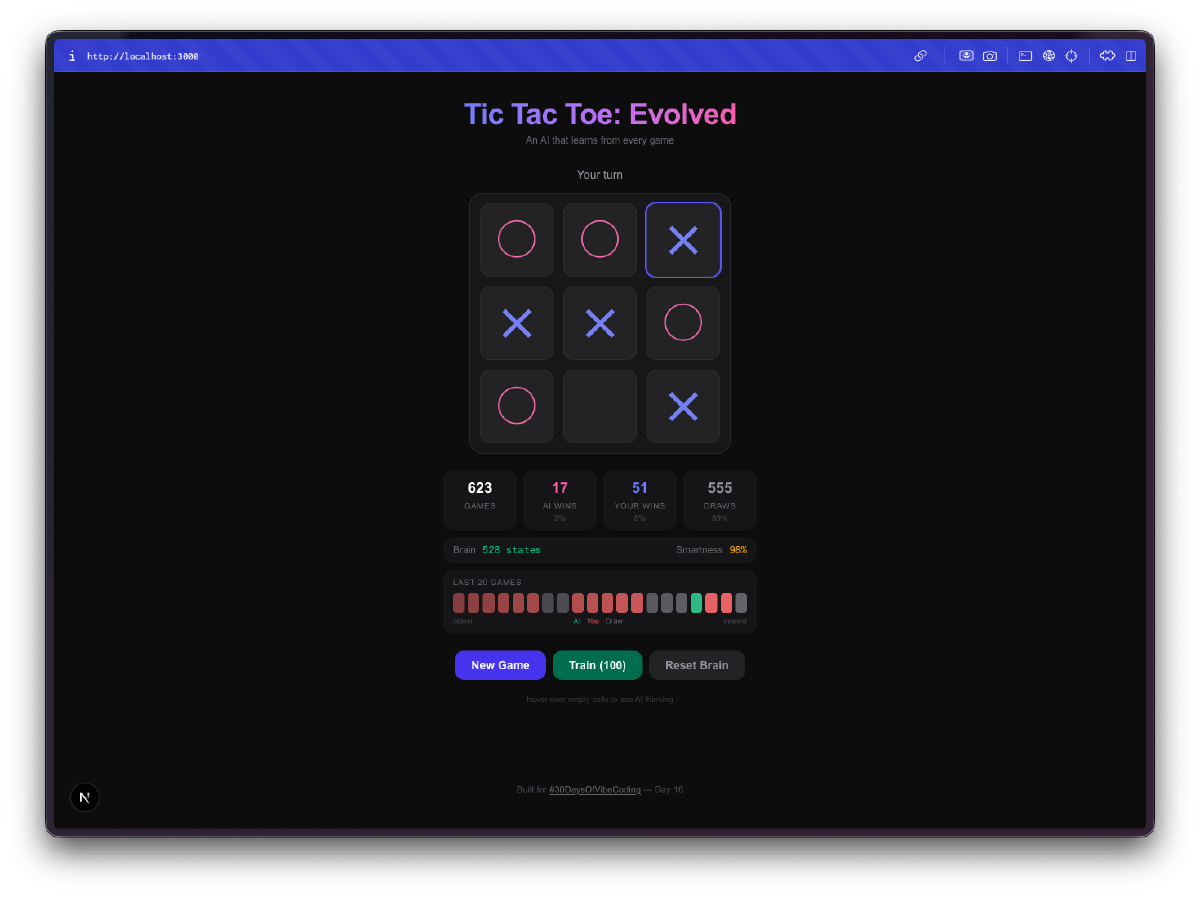
Die KI startet furchtbar. In deinen ersten Spielen spielt sie fast zufällig. Sie wählt Felder ohne Strategie, tappt in dieselben Fallen, verliert auf offensichtliche Weise. Das ist genau der Punkt. Sie erkundet den Spielraum, probiert Züge aus, die sie noch nie probiert hat, und baut ihre Q-Table von Grund auf auf.
Dann hört sie auf, furchtbar zu sein. Irgendwo zwischen 50 und 100 Spielen merkst du, dass sie deine Gewinnzüge blockiert. Nach ein paar hundert Spielen erreicht sie konsistent Unentschieden. Trainiere sie mit ein paar tausend Selbstspiel-Partien und viel Glück beim Versuch zu gewinnen. Der Fortschritt von ahnungslos zu kompetent macht echt Spaß zu beobachten.
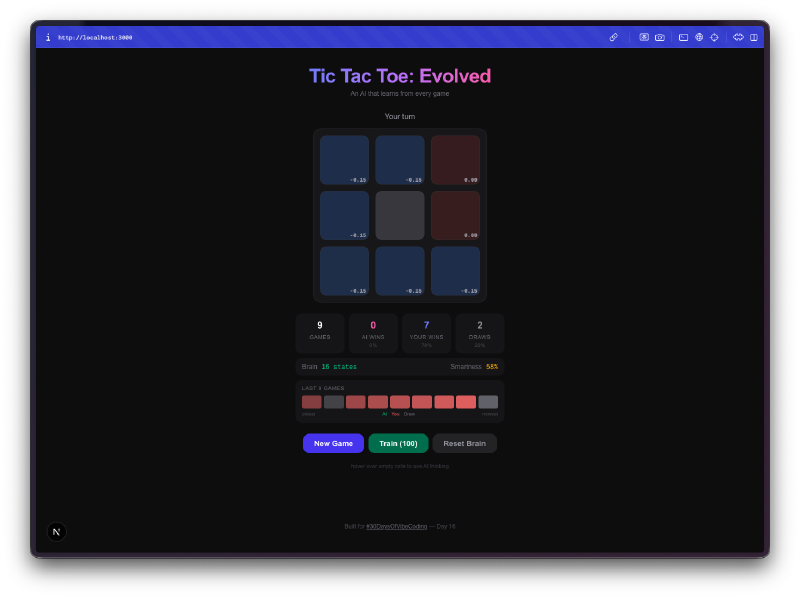
Die Gehirn-Visualisierung ist das Beste daran. Du kannst mit der Maus über die Zellen fahren und die Q-Values sehen, die die KI für jede Position gelernt hat. Hohe positive Werte bedeuten, dass die KI denkt, dieser Zug führt zum Sieg. Negative Werte bedeuten, dass sie gelernt hat, dieses Feld im aktuellen Zustand zu meiden. Du schaust buchstäblich auf das Verständnis der KI vom Spiel, und du kannst beobachten, wie sich diese Zahlen verschieben, je mehr sie spielt.
Massentraining macht süchtig. Es gibt einen Trainingsmodus, in dem du 100, 1.000 oder 10.000 Selbstspiel-Partien laufen lassen kannst. Die KI spielt gegen sich selbst und lernt von beiden Seiten. Du kannst die Größe der Q-Table in Echtzeit wachsen sehen, während sie neue Brettzustände entdeckt. Nach 10.000 Spielen hat das Gehirn tausende einzigartige Positionen gesehen und hat zu jeder eine klare Meinung.
Alles bleibt gespeichert. Schließ den Tab, komm morgen wieder, und die KI erinnert sich an alles, was sie gelernt hat. Die Q-Table, die Spielstatistiken, die Siegesserien-Historie. Alles ist im localStorage gespeichert. Dein KI-Gegner hat ein permanentes Gedächtnis, was bedeutet, dass sie umso besser wird, je mehr du über Tage und Wochen gegen sie spielst.
Die Schwierigkeitsgrade ändern die Explorationsrate. Der einfache Modus hält das Epsilon (Zufälligkeit) hoch, damit die KI mehr Fehler macht. Der schwere Modus senkt das Epsilon, sodass sie fast immer den Zug wählt, den sie für den besten hält. So kannst du steuern, wie sehr sich die KI auf das Gelernte verlässt versus Neues auszuprobieren.
Die kleinen Details machen den Unterschied. Gewinnlinien werden hervorgehoben. Soundeffekte spielen bei Zügen, Siegen, Niederlagen und Unentschieden. Es gibt eine Übersicht der letzten Spiele, die deine letzten 20 Ergebnisse als visuellen Serien-Tracker anzeigt. Das Ganze fühlt sich wie ein richtiges Spiel an, nicht nur wie eine Tech-Demo.
Die Zahlen#
- 4 Watchfire-Aufgaben vom Grundgerüst bis zum Feinschliff
- Die Q-Table wächst auf tausende Einträge nach Massentraining
- 3 Schwierigkeitsgrade zur Steuerung des Explorations-/Exploitations-Tradeoffs
- Volle localStorage-Persistenz für das KI-Gehirn und alle Statistiken
- 0 hardcodierte Strategie in der KI. Alles was sie weiß, hat sie gelernt
Probier Es Aus#
Spiel ein paar Runden und schau der KI beim Besserwerden zu. Oder drück den Trainings-Button und lass sie sich selbst beibringen.
Fazit von Tag 16#
Tic-Tac-Toe ist ein gelöstes Spiel. Jeder perfekte Spieler kann jedes Mal ein Unentschieden erzwingen. Genau das macht es zu einem großartigen Spielplatz für Reinforcement Learning. Das Spiel ist einfach genug, dass die KI den gesamten Zustandsraum in einer vernünftigen Anzahl von Spielen erkunden kann, und du kannst tatsächlich sehen, wie sie zum optimalen Spiel konvergiert.
Was mir an diesem Projekt gefällt, ist dass es Machine Learning greifbar macht. Du liest nicht über Q-Learning in einem Lehrbuch oder schaust dir Trainings-Loss-Kurven in einem Jupyter Notebook an. Du spielst gegen eine KI, die sichtbar schlauer wird. Du kannst ihre Q-Values sehen, ihr Gehirn beim Wachsen beobachten und den Unterschied spüren zwischen einem Spiel gegen sie bei Partie 10 versus Partie 10.000.
Die Tatsache, dass alles im Browser läuft ohne Backend, ohne Python, ohne TensorFlow, nur TypeScript und localStorage, lässt es zugänglich wirken. Q-Learning ist einer der einfachsten Reinforcement-Learning-Algorithmen, aber ihn in Echtzeit bei einem Spiel zu sehen, das man bereits versteht, lässt das Konzept auf eine Weise klicken, die Theorie allein nie schafft.
Das ist Tag 16 von 30 Days of Vibe Coding. Folge mir, während ich 30 Projekte in 30 Tagen mit KI-unterstützter Programmierung veröffentliche.