Comencemos desde el principio y avancemos paso a paso.
Fundamentos#
IA vs ML vs Deep Learning#
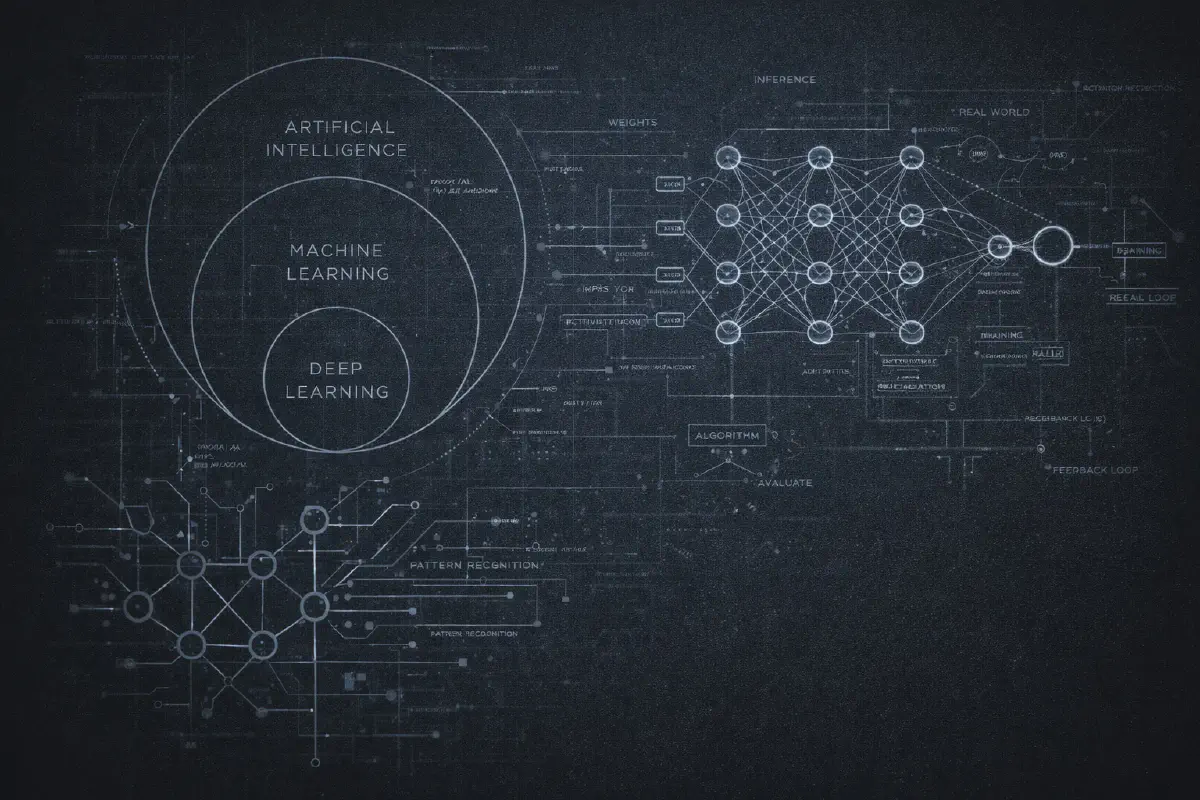
Probablemente hayas visto el diagrama: tres circulos concentricos con IA en el exterior, Machine Learning en el medio y Deep Learning en el centro. Se ha convertido en un cliche, pero es genuinamente util para entender como se relacionan estos terminos.
Inteligencia Artificial es el termino mas amplio. Simplemente significa “hacer que las computadoras hagan cosas que requeririan inteligencia si los humanos las hicieran.” Eso es todo. Un programa de ajedrez de los anos 70? IA. Tu filtro de spam? IA. Una simple regla if-else que decide si mostrarte un popup? Tecnicamente, IA. El termino es tan amplio que es casi insignificante por si solo.
Machine Learning es un subconjunto de IA donde en lugar de programar reglas explicitas, le das ejemplos a la computadora y la dejas descubrir los patrones. En lugar de escribir “si el email contiene ‘principe nigeriano’, marcar como spam,” le muestras 10,000 emails etiquetados como “spam” o “no spam” y dejas que el algoritmo aprenda que hace que el spam sea… spam.
Deep Learning es un subconjunto de machine learning que usa redes neuronales con muchas capas (de ahi “profundo”). Aqui es donde las cosas se pusieron interesantes en la decada de 2010. El deep learning permitio avances en reconocimiento de imagenes, reconocimiento de voz, y eventualmente los modelos de lenguaje con los que todos estamos obsesionados ahora.
Redes Neuronales#
Aqui hay una analogia que es imperfecta pero util: una red neuronal es como una hoja de calculo muy complicada con millones de numeros ajustables.
Los datos entran por un lado. Se multiplican por estos numeros, se suman, pasan por algunas funciones matematicas, y eventualmente producen una salida del otro lado. La parte del “aprendizaje” es ajustar todos esos numeros hasta que las salidas coincidan con lo que quieres.
Si quieres profundizar: la red esta organizada en capas. Cada capa contiene “neuronas” (realmente solo funciones matematicas). Cada neurona toma entradas, las multiplica por pesos, las suma, y pasa el resultado a traves de una funcion de activacion. La magia ocurre porque cuando apilas muchas capas juntas, la red puede aprender patrones increiblemente complejos - cosas que ningun humano podria programar a mano.
El termino “neuronal” viene de una analogia vaga con las neuronas biologicas del cerebro. No tomes esto demasiado literalmente. Estos sistemas no funcionan nada como cerebros reales. La metafora fue util para los investigadores originales en los anos 40 pero se ha vuelto algo enganosa.
Training vs Inference#
Todo sistema de IA tiene dos fases distintas, y confundirlas causa infinitos malentendidos.
Entrenamiento es la parte costosa. Aqui es cuando le muestras al modelo millones (o miles de millones) de ejemplos y ajustas todos esos numeros internos hasta que el modelo se vuelve bueno en su tarea. Entrenar GPT-4 supuestamente costo mas de $100 millones solo en computo. El entrenamiento ocurre una vez (o periodicamente cuando quieres actualizar el modelo).
Inferencia es la parte barata - relativamente hablando. Aqui es cuando realmente usas el modelo entrenado. Le das una entrada, produce una salida. Cada vez que chateas con ChatGPT, estas haciendo inferencia. Los numeros del modelo estan congelados; solo esta ejecutando calculos.
Piensalo como educacion vs. trabajo. El entrenamiento son anos de escuela y estudio. La inferencia es presentarte a trabajar y usar lo que aprendiste. La inversion ocurre por adelantado; el retorno viene durante el uso.
Entendiendo los LLMs#
Que Hace Especiales a los LLMs#
Los Large Language Models son un tipo especifico de modelo de deep learning entrenado para predecir texto. Esa es la idea central: en su nucleo, los LLMs solo estan tratando de predecir la siguiente palabra (o token) en una secuencia.
“El gato se sento en la ___” → “alfombra” (probablemente)
Pero aqui esta lo increible: cuando entrenas este simple objetivo en billones de palabras de internet, libros, codigo y articulos cientificos, algo notable ocurre. El modelo no solo aprende gramatica. Aprende hechos, patrones de razonamiento, convenciones de codigo, e incluso algo que parece sentido comun.
Esto se llama comportamiento emergente - capacidades que no fueron entrenadas explicitamente pero surgieron de la escala del entrenamiento. Nadie programo a GPT-4 para escribir poesia o resolver problemas matematicos. Esas habilidades emergieron del objetivo de predecir el siguiente token realmente, realmente bien.
Transformers y Atencion#
La arquitectura que hizo posibles los LLMs modernos se llama Transformer, introducida en un articulo de 2017 famosamente titulado “Attention Is All You Need.”
La innovacion clave es el mecanismo de atencion. Los modelos anteriores procesaban texto secuencialmente - palabra por palabra, de izquierda a derecha. La atencion permite al modelo mirar todas las palabras simultaneamente y aprender cuales palabras son relevantes entre si.
Ejemplo simple: “El animal no cruzo la calle porque estaba muy cansado.”
A que se refiere “estaba”? Al animal. Pero como lo sabe el modelo? El mecanismo de atencion aprende que “estaba” debe atender fuertemente a “animal” y debilmente a “calle.” Esta habilidad de capturar dependencias de largo alcance es lo que hace a los Transformers tan poderosos para el lenguaje.
Tokens y Ventanas de Contexto#
Los LLMs realmente no ven palabras - ven tokens. Un token es un fragmento de texto, tipicamente una palabra o parte de una palabra. “Entendiendo” podria ser un token, mientras que “en” + “tend” + “iendo” podrian ser tres tokens dependiendo del tokenizador del modelo.
Por que importa esto? Porque los modelos tienen ventanas de contexto limitadas - el numero maximo de tokens que pueden procesar a la vez. El GPT-3 original tenia un contexto de 4K tokens. GPT-4 Turbo expandio a 128K. Claude puede manejar 200K. Algunos modelos mas nuevos afirman millones.
Piensa en la ventana de contexto como la memoria de trabajo del modelo. Todo lo que quieres que el modelo considere - tu pregunta, cualquier documento que compartas, el historial de conversacion - necesita caber en esta ventana.
| Modelo | Ventana de Contexto | Equivalente Aproximado |
|---|---|---|
| GPT-3 (2020) | 4K tokens | ~3,000 palabras |
| GPT-4 Turbo | 128K tokens | ~100,000 palabras |
| Claude 3.5 | 200K tokens | ~150,000 palabras |
| Gemini 1.5 Pro | 1M+ tokens | ~750,000 palabras |
Prompt Engineering#
Un prompt es simplemente el texto que envias a un LLM. Tu pregunta, tus instrucciones, cualquier contexto que proporciones - todo eso es parte del prompt.
Ingenieria de prompts es el arte (y cada vez mas, ciencia) de escribir prompts que obtienen mejores resultados. Suena tonto - “ingenieria” de tus preguntas? - pero genuinamente importa.
Algunas tecnicas que funcionan:
- Se especifico. “Escribe un poema” vs. “Escribe un soneto de 14 lineas sobre el cambio climatico en el estilo de Shakespeare” - el segundo obtiene resultados dramaticamente mejores.
- Muestra ejemplos. Dale al modelo algunos ejemplos de lo que quieres antes de pedir la salida real. Esto se llama “few-shot prompting.”
- Piensa paso a paso. Agregar “Pensemos esto paso a paso” antes de un problema complejo mejora la precision. Esto se llama prompting de “cadena de pensamiento.”
- Asigna un rol. “Eres un contador fiscal experto” enfoca las respuestas del modelo.
Temperatura y Parametros#
Cuando usas una API de LLM, puedes ajustar varios parametros que afectan la salida. El mas importante es la temperatura.
La temperatura controla la aleatoriedad. En temperatura 0, el modelo siempre elige el token mas probable - deterministico, predecible, a veces aburrido. En temperatura 1 o superior, esta mas dispuesto a elegir tokens menos probables - mas creativo, mas variado, a veces sin sentido.
- Temperatura 0: “La capital de Francia es Paris.”
- Temperatura 1: “La capital de Francia es Paris, esa magnifica ciudad de las luces donde la revolucion y el romance bailan por calles empedradas…”
Otros parametros comunes:
- Top-p (muestreo de nucleo): Otra forma de controlar la aleatoriedad limitando que tokens se consideran.
- Max tokens: Que tan larga puede ser la respuesta.
- Secuencias de parada: Dile al modelo cuando dejar de generar.
- Penalizacion de frecuencia/presencia: Reduce la repeticion.
Alucinaciones#
Los LLMs inventan cosas. Afirman falsedades con completa confianza. Citan articulos que no existen. Inventan estadisticas. Esto se llama alucinacion, y no es un bug que se arreglara - es una consecuencia de como funcionan estos modelos.
Recuerda: los LLMs estan entrenados para predecir texto plausible, no texto verdadero. Si preguntas sobre un tema donde el modelo tiene datos de entrenamiento limitados, generara algo que suena correcto. El modelo no tiene verificador de hechos interno, no tiene conexion con la verdad de base, no tiene forma de decir “no lo se.”
Por que sucede esto?
- Objetivo de entrenamiento: Predecir el siguiente token, no verificar la verdad.
- Distribucion de probabilidad: El modelo muestrea de posibilidades. Incluso si la respuesta verdadera es la mas probable, el muestreo podria elegir otra cosa.
- Sin conciencia de corte de conocimiento: El modelo no sabe de manera confiable los limites de su conocimiento.
Estrategias para reducir alucinaciones:
- Usa RAG para fundamentar las respuestas en documentos reales
- Pide al modelo que cite fuentes y verificalas
- Baja la temperatura para tareas factuales
- Usa salidas estructuradas que restrinjan la respuesta
- Implementa capas de verificacion de hechos
El Panorama de Modelos#
Open vs Closed Models#
Closed source: Puedes usar el modelo via API pero no puedes ver los pesos, modificar la arquitectura, o ejecutarlo tu mismo. GPT-4 de OpenAI, Claude de Anthropic, Gemini de Google.
Open source/open weights: Los pesos estan disponibles publicamente. Puedes descargarlos, ejecutarlos localmente, ajustarlos, modificarlos. Llama de Meta, Mistral, Qwen de Alibaba, DeepSeek, y muchos otros.
La distincion es importante pero tiene matices:
- “Open weights” significa que puedes descargar y ejecutar el modelo
- “Open source” tradicionalmente significa que el codigo de entrenamiento y los datos tambien estan disponibles (raro para modelos grandes)
- Las licencias varian - algunos modelos abiertos tienen restricciones comerciales
Por que Meta libera Llama gratis? Razones estrategicas: comoditizar el complemento, construir ecosistema, atraer talento, establecer estandares. La vision cinica: no pueden competir con OpenAI en ingresos de API, asi que compiten haciendo la capa del modelo gratis y obteniendo ganancias en otros lugares.
Modelos Multimodales#
Los primeros LLMs solo entendian texto. Los modelos multimodales entienden multiples tipos de datos - texto, imagenes, audio, video.
GPT-4V puede mirar una foto y describirla. Claude puede analizar graficos y diagramas. Gemini puede ver videos. Esto no es solo novedad - abre casos de uso completamente nuevos:
- Captura de pantalla de un bug y pide ayuda para depurar
- Sube un diagrama dibujado a mano y obtiene codigo
- Analiza imagenes medicas
- Procesa video para moderacion de contenido
- Interfaces de voz sin speech-to-text separado
Las arquitecturas varian. Algunos modelos son entrenados nativamente multimodales. Otros conectan modelos separados de vision y lenguaje. La distincion importa para el rendimiento pero no para la mayoria de los usuarios.
Modelos de Razonamiento#
Los LLMs estandar generan respuestas token por token sin “pensamiento” explicito. Los modelos de razonamiento toman un enfoque diferente - gastan computo extra pensando en los problemas antes de responder.
Los modelos o1 y o3 de OpenAI fueron pioneros en este enfoque. En lugar de responder inmediatamente, estos modelos generan cadenas de razonamiento internas (a veces ocultas de los usuarios), consideran multiples enfoques, y verifican su trabajo antes de producir una respuesta final.
Los resultados son impresionantes: los modelos de razonamiento superan dramaticamente a los LLMs estandar en matematicas, programacion, ciencia y problemas de logica. o3 logro puntuaciones en ciertos benchmarks que se pensaba estaban a anos de distancia.
La desventaja: los modelos de razonamiento son mas lentos y mas caros. Una pregunta simple que GPT-4 responde instantaneamente podria tomarle a o1 varios segundos (y 10x el costo) mientras “piensa.” Para tareas simples, eso es desperdicio. Para problemas dificiles, vale la pena.
Cuando usar modelos de razonamiento:
- Problemas complejos de matematicas o logica
- Desafios de programacion de multiples pasos
- Tareas que requieren analisis cuidadoso
- Cualquier cosa donde la precision importa mas que la velocidad
Cuando los LLMs estandar son mejores:
- Preguntas y respuestas simples
- Escritura creativa
- Aplicaciones en tiempo real
- Casos de uso sensibles al costo
Productos de IA para Consumidores#
Antes de profundizar en detalles tecnicos, mapeemos los productos que probablemente ya has usado:
ChatGPT (OpenAI) - El producto que inicio la ola mainstream de IA. Acceso a GPT-4, o1, DALL-E para imagenes, y varios plugins. El punto de referencia contra el que todos los demas se comparan.
Claude (Anthropic) - Conocido por escritura solida, ventanas de contexto largas, y razonamiento matizado. Claude.ai es la interfaz de consumidor; la API impulsa muchas aplicaciones.
Gemini (Google) - Profundamente integrado con el ecosistema de Google. Acceso via gemini.google.com e cada vez mas integrado en Search, Docs, Gmail y Android.
Copilot (Microsoft) - La capa de IA de Microsoft en todos sus productos. Diferente de GitHub Copilot (programacion) - este es el asistente de consumidor en Windows, Edge y Microsoft 365.
Perplexity - Motor de busqueda nativo de IA. Responde preguntas con citas y fuentes. Un vistazo de lo que la busqueda podria convertirse.
Otros que vale la pena conocer: Grok (xAI, integrado en X/Twitter), Pi (Inflection), Le Chat (Mistral), DeepSeek Chat, y muchas alternativas regionales/especializadas.
Ejecutando Modelos Localmente#
Por Que Ejecutar Localmente?#
Los modelos en la nube se ejecutan en los servidores de otra persona. Envias solicitudes por internet y pagas por uso. OpenAI, Anthropic, Google - este es su negocio.
Los modelos locales se ejecutan en tu propio hardware. Tu laptop, tus servidores, tu centro de datos. Los datos nunca salen de tu control.
Por que ejecutar localmente?
- Privacidad: Los datos sensibles permanecen en las instalaciones
- Costo: Sin tarifas de API (pero el hardware no es gratis)
- Latencia: Sin viaje de ida y vuelta por red
- Disponibilidad: Funciona sin conexion, sin limites de tasa
- Control: Sin terminos de servicio, sin filtros de contenido que no elegiste
La brecha entre local y nube se ha reducido dramaticamente. Para muchas aplicaciones practicas, los modelos locales son suficientemente buenos - especialmente para tareas de programacion, escritura y analisis.
La desventaja: las capacidades de frontera todavia requieren la nube. Si necesitas el mejor rendimiento absoluto en tareas de razonamiento dificil, GPT-4, Claude o Gemini son solo en la nube. Pero esa brecha se reduce con cada lanzamiento.
Ollama#
Ollama se ha convertido en el estandar de facto para ejecutar modelos localmente. Hace trivialmente facil lo que solia ser un proceso complejo.
# Instala y ejecuta un modelo en dos comandos
ollama pull llama3.2
ollama run llama3.2Eso es todo. Estas chateando con un LLM capaz ejecutandose completamente en tu maquina.
Ollama maneja la complejidad: descargar modelos, gestionar memoria, optimizar para tu hardware, y proporcionar tanto una CLI como una API local. Soporta docenas de modelos - Llama, Mistral, Qwen, Phi, CodeLlama, y muchos mas.
Caracteristicas clave:
- Interfaz CLI simple
- API compatible con OpenAI (facil de intercambiar en codigo existente)
- Biblioteca de modelos con descargas de un comando
- Funciona en Mac, Linux y Windows
- Aceleracion GPU cuando esta disponible
Para desarrolladores, la API local de Ollama significa que puedes desarrollar contra modelos locales y cambiar a APIs en la nube para produccion - o viceversa - con cambios minimos de codigo.
Consideraciones de Hardware#
Ejecutar modelos localmente requiere hardware. Esto es lo que importa:
GPU vs CPU: Las GPUs aceleran dramaticamente la inferencia. Un modelo que toma 30 segundos por respuesta en CPU podria tomar 2 segundos en GPU. Las Macs con Apple Silicon difuminan esta linea - su memoria unificada y Neural Engine las hacen sorprendentemente capaces para inferencia local.
Memoria (VRAM/RAM): Este es usualmente el factor limitante. Los modelos necesitan caber en memoria. Un modelo de 7B parametros necesita aproximadamente 4-8GB. Un modelo de 70B necesita 35-70GB. La cuantizacion (discutida abajo) reduce estos requisitos.
Cuantizacion: Reducir la precision de los pesos del modelo de 32-bit a 16-bit, 8-bit, o incluso 4-bit. Esto reduce los requisitos de memoria y acelera la inferencia con perdida minima de calidad. La mayoria de los modelos locales se distribuyen en formatos cuantizados (GGUF, GPTQ, AWQ).
Guia practica:
- Mac con 16GB+ RAM: Puede ejecutar modelos de 7B-13B comodamente
- Mac con 32GB+ RAM: Puede ejecutar modelos de 30B+
- PC con RTX 3090/4090 (24GB VRAM): Puede ejecutar la mayoria de los modelos hasta 70B (cuantizados)
- Sin GPU: Todavia funciona, solo mas lento. Bien para desarrollo y experimentacion.
Personalizacion y Conocimiento#
Fine-Tuning vs RAG#
Tienes un LLM base. Quieres hacerlo mejor para tu caso de uso especifico. Dos enfoques principales:
Fine-Tuning#
Toma un modelo existente y continua entrenandolo con tus propios datos. Los pesos del modelo realmente cambian. Despues del fine-tuning, el modelo “sabe” tu informacion nativamente.
Pros: Inferencia rapida, integracion profunda del conocimiento, puede aprender nuevos estilos o comportamientos. Contras: Costoso, requiere experiencia en ML, el conocimiento puede volverse obsoleto, riesgo de olvido catastrofico (el modelo empeora en otras tareas).
RAG (Retrieval-Augmented Generation)#
Mantiene el modelo como esta. Cuando llega una pregunta, primero busca en tu base de conocimientos documentos relevantes, luego incluye esos documentos en el prompt junto con la pregunta.
Pros: Mas barato, el conocimiento se mantiene actualizado, no requiere entrenamiento, facil de auditar (puedes ver lo que se recupero). Contras: Mas lento (proceso de dos pasos), limitado por la ventana de contexto, la calidad de la recuperacion importa mucho.
Embeddings y Vector DBs#
Esta es la tecnologia que hace funcionar RAG - y es genuinamente ingeniosa.
Un embedding es una forma de representar texto (o imagenes, o cualquier cosa) como una lista de numeros - un vector. La magia: cosas similares tienen vectores similares. “Perro” y “cachorro” tienen vectores que estan cerca. “Perro” y “democracia” estan lejos.
Creas embeddings usando modelos de embedding (diferentes de los LLMs, aunque algunos LLMs tienen capacidades de embedding). OpenAI, Cohere, Voyage, y muchos otros ofrecen APIs de embedding. Opciones open source como BGE y E5 funcionan muy bien tambien.
Una base de datos vectorial es una base de datos optimizada para almacenar y buscar estos vectores. Cuando preguntas “Cual es nuestra politica de reembolsos?”, el sistema:
- Convierte tu pregunta a un vector
- Busca en la base de datos vectorial por vectores similares
- Devuelve los documentos que esos vectores representan
- Alimenta esos documentos al LLM con tu pregunta
Bases de datos vectoriales populares incluyen Pinecone, Weaviate, Chroma, Qdrant, y Milvus. Postgres con pgvector funciona sorprendentemente bien para muchos casos de uso.
Evaluacion#
Benchmarks#
Como sabes si un modelo es “mejor” que otro? Los benchmarks intentan responder esto probando modelos en tareas estandarizadas.
Benchmarks comunes:
- MMLU (Massive Multitask Language Understanding): Preguntas de opcion multiple en 57 materias. Prueba conocimiento general.
- HumanEval: Problemas de programacion. Prueba habilidad de programacion.
- GSM8K: Problemas de matematicas de nivel escolar. Prueba razonamiento matematico.
- HellaSwag: Razonamiento de sentido comun sobre situaciones cotidianas.
- TruthfulQA: Prueba si los modelos dan respuestas verdaderas vs. tonterias que suenan convincentes.
El problema con los benchmarks: Son manipulables. Los modelos pueden entrenarse especificamente para ir bien en benchmarks populares sin realmente mejorar en tareas reales. Un modelo que obtiene 90% en MMLU todavia podria fallar en tu caso de uso especifico.
Evals#
Evals (evaluaciones) son pruebas que creas para tu caso de uso especifico. A diferencia de los benchmarks, los evals miden lo que realmente importa para tu aplicacion.
Construyendo un bot de servicio al cliente? Tus evals podrian probar:
- Responde correctamente preguntas de tu FAQ?
- Escala apropiadamente a humanos cuando es necesario?
- Se mantiene en la marca y sigue tus guias de tono?
- Se niega a hacer promesas que la empresa no puede cumplir?
Por que importan los evals:
- Deteccion de regresiones: Cuando cambias prompts o cambias modelos, los evals detectan problemas antes que los usuarios.
- Comparacion: Compara objetivamente diferentes modelos, prompts o enfoques para tu caso de uso.
- Iteracion: No puedes mejorar lo que no puedes medir. Los evals hacen la mejora sistematica.
Construyendo buenos evals:
- Comienza con consultas de usuarios reales y respuestas esperadas
- Incluye casos limite y ejemplos adversarios
- Prueba tanto lo que el modelo deberia hacer COMO lo que no deberia
- Automatiza para poder ejecutar evals en cada cambio
LLM como Juez#
Aqui hay una tecnica ingeniosa: usa un LLM para evaluar las salidas de otro LLM.
En lugar de revisar manualmente cientos de respuestas, puedes dar instrucciones a un modelo para actuar como juez:
Estas evaluando la calidad de la respuesta de un asistente de IA.
Pregunta del usuario: {question}
Respuesta del asistente: {response}
Califica la respuesta en:
1. Precision (1-5): Es correcta la informacion?
2. Utilidad (1-5): Realmente ayuda al usuario?
3. Claridad (1-5): Es facil de entender?
Explica tu razonamiento, luego proporciona puntuaciones.Por que funciona esto:
- Escala a miles de evaluaciones
- Mas consistente que revisores humanos (menos fatiga)
- Puede evaluar cualidades matizadas que son dificiles de probar programaticamente
- Mas barato y rapido que la evaluacion humana
Limitaciones:
- El modelo juez tiene sus propios sesgos y limitaciones
- Puede perder errores que el mismo cometeria
- Tiene dificultades con precision especifica del dominio sin fundamentacion
- No es un reemplazo completo para la evaluacion humana - mas bien un complemento
Agentes y Automatizacion#
Que Son los Agentes?#
El termino “agente” se usa mucho. Aqui hay una definicion funcional: un agente es un LLM que puede tomar acciones en el mundo, no solo generar texto.
Un chatbot responde tus preguntas. Un agente podria responder tus preguntas y reservar un restaurante, enviar un email, consultar una base de datos, o escribir y ejecutar codigo para resolver un problema.
Que hace que algo sea un agente vs. solo un LLM?
- Objetivos: Los agentes trabajan hacia metas, no solo responden a prompts.
- Acciones: Los agentes pueden hacer cosas, no solo decir cosas.
- Autonomia: Los agentes toman decisiones sobre como lograr objetivos.
- Bucles: Los agentes frecuentemente corren en bucles - observar, pensar, actuar, repetir.
El patron de agente mas simple: dar a un LLM acceso a herramientas y dejarlo decidir cuales herramientas usar. “Encuentra vuelos de Londres a Tokyo la proxima semana, revisa mi calendario, y reserva la opcion mas barata que funcione con mi horario.” El agente descompone esto, llama APIs de vuelos, llama APIs de calendario, y ejecuta la reserva.
Agentes vs Flujos de Trabajo#
Una distincion importante que frecuentemente se difumina:
Los flujos de trabajo son deterministicos. Tu defines los pasos: primero haz A, luego haz B, luego si X haz C sino haz D. El LLM podria impulsar pasos individuales, pero la orquestacion esta programada.
1. Extraer entidades del email (LLM)
2. Buscar cliente en base de datos (codigo)
3. Generar borrador de respuesta (LLM)
4. Enviar para revision humana (codigo)Los agentes son autonomos. Les das un objetivo y herramientas, y ellos descubren los pasos. El LLM decide que hacer a continuacion basado en el estado actual.
Objetivo: "Resolver esta queja de cliente"
Herramientas: [email, base_de_datos, sistema_de_reembolsos, escalamiento]
→ El agente decide que hacer, en que ordenCuando usar flujos de trabajo:
- Procesos predecibles, bien entendidos
- Cuando necesitas confiabilidad y auditabilidad
- Entornos regulados
- Tareas de alto volumen, baja complejidad
Cuando usar agentes:
- Tareas novedosas o variables
- Cuando los pasos no se conocen de antemano
- Se requiere razonamiento complejo
- Cuando la flexibilidad importa mas que la predecibilidad
La ecuacion de costos: Los flujos de trabajo son significativamente mas baratos. Estas pagando por un numero fijo de llamadas LLM por ejecucion - predecible, optimizable, auditable. Los agentes son caros porque piensan. Cada punto de decision - “que herramienta deberia usar?”, “funciono eso?”, “que sigue?” - es una llamada LLM. Un flujo de trabajo que hace 3 llamadas LLM podria convertirse en un agente que hace 15-30 llamadas para resolver el mismo problema, porque el agente esta razonando sobre como resolverlo, no solo ejecutando pasos predefinidos. Para tareas bien entendidas a escala, los flujos de trabajo ganan en costo. Para problemas complejos y variables donde no puedes predefinir los pasos, los agentes valen la prima.
Tool Use y Function Calling#
Para que los agentes tomen acciones, necesitan herramientas - funciones que pueden llamar. Esta capacidad usualmente se llama function calling o uso de herramientas.
Asi es como funciona:
- Defines herramientas con nombres, descripciones y parametros (usualmente como schemas JSON)
- Incluyes estas definiciones en tu prompt/llamada API
- El modelo puede elegir “llamar” una herramienta en lugar de generar texto
- Tu codigo ejecuta la funcion y devuelve resultados al modelo
- El modelo usa esos resultados para continuar
Ejemplo de definicion de herramienta:
{
"name": "get_weather",
"description": "Get current weather for a city",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "City name"},
"units": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["city"]
}
}Cuando preguntas “Cual es el clima en Tokyo?”, el modelo no alucina - llama get_weather(city="Tokyo"), obtiene datos reales, y responde con hechos.
Todos los principales proveedores de modelos ahora soportan function calling: OpenAI, Anthropic, Google, y otros. La sintaxis varia ligeramente pero el concepto es el mismo.
Protocolo MCP#
Model Context Protocol (MCP) es un estandar abierto para conectar modelos de IA con herramientas y fuentes de datos. Piensalo como USB-C para IA - un conector universal que significa que no necesitas un cable diferente para cada dispositivo.
Antes de MCP, cada integracion era personalizada. Quieres que tu IA acceda a GitHub? Escribe una integracion de GitHub. Salesforce? Otra integracion. Tu base de datos interna? Otra mas. Esto no escala.
MCP define una forma estandar para que clientes de IA (como Claude, ChatGPT, o tu agente personalizado) descubran y usen herramientas de servidores MCP. Un servidor MCP podria exponer:
- Herramientas: Funciones que la IA puede llamar
- Recursos: Datos que la IA puede leer
- Prompts: Plantillas para tareas comunes
Las implicaciones son significativas:
- Construye un servidor MCP una vez, cada IA compatible puede usarlo
- Las herramientas se vuelven portables y reutilizables
- La seguridad y los permisos pueden estandarizarse
- El ecosistema se compone - mas servidores significa agentes mas capaces
Para mas sobre MCP, escribi un articulo mas profundo: MCP Servers: The USB-C Moment for AI Agents.
Patrones Agentivos#
A medida que los agentes han madurado, han emergido patrones comunes:
ReAct (Reason + Act): El agente alterna entre razonar (“Necesito encontrar el historial de pedidos del usuario”) y actuar (llamar a la API de pedidos). Este paso de razonamiento explicito mejora la confiabilidad.
Planificacion: Antes de actuar, el agente crea un plan: “Para resolver esto, necesitare 1) buscar el pedido, 2) verificar inventario, 3) procesar el reembolso, 4) enviar confirmacion.” Los planes pueden validarse antes de la ejecucion.
Reflexion: Despues de completar una tarea (o fallar), el agente revisa lo que paso: “El reembolso fallo porque el pedido era muy antiguo. Deberia haber verificado la politica de reembolsos primero.” Esto permite aprendizaje y autocorreccion.
Seleccion de herramientas: Cuando un agente tiene muchas herramientas, elegir la correcta se vuelve no trivial. Las tecnicas incluyen descripciones de herramientas, ejemplos few-shot, y organizacion jerarquica de herramientas.
Humano en el bucle: Para acciones de alto riesgo, los agentes pueden pausar y solicitar aprobacion humana antes de proceder. Los buenos agentes saben cuando tienen incertidumbre.
Skills#
Los Skills son prompts especializados y reutilizables que extienden lo que un agente puede hacer. Piensa en ellos como “modos expertos” que puedes conectar a un agente - un skill para revision de codigo, un skill para escribir documentacion, un skill para analizar vulnerabilidades de seguridad.
A diferencia de las herramientas (que son funciones que hacen cosas), los skills son instrucciones que moldean como el agente piensa y responde. Una herramienta llama una API. Un skill le dice al agente “cuando te pregunten sobre X, enfocalo de esta manera, considera estos factores, y formatea tu respuesta asi.”
Por que importan los skills:
- Especializacion sin fine-tuning: Obtienes comportamiento experto sin entrenar un nuevo modelo.
- Composabilidad: Mezcla y combina skills para diferentes tareas.
- Compartibilidad: Un skill bien elaborado puede usarse entre equipos, proyectos, o incluso compartirse publicamente.
- Eficiencia de contexto: En lugar de explicar tus requisitos cada vez, codificalos una vez en un skill.
Donde viven los skills:
Los skills pueden inyectarse en diferentes puntos del contexto del agente:
- System prompt: El enfoque mas comun. Los skills se vuelven parte de las instrucciones base del agente, siempre activos.
- Prefijo de mensaje de usuario: Agregado dinamicamente a las solicitudes del usuario. Util para skills especificos de tarea.
- Descripciones de herramientas: Los skills pueden incrustarse en definiciones de herramientas, guiando como el agente usa herramientas especificas.
- Prompts MCP: Los servidores MCP pueden exponer skills como “prompts” - plantillas reutilizables que los clientes pueden descubrir e invocar.
Como los skills influyen en el contexto:
Cada skill consume tokens de tu ventana de contexto. Esto crea compromisos:
- Mas skills = agente mas capaz, pero menos espacio para historial de conversacion
- Skills detallados = mejor comportamiento, pero mayor costo de tokens por solicitud
- Skills siempre activos vs. skills bajo demanda = confiabilidad vs. eficiencia
Los frameworks de agentes inteligentes manejan esto cargando skills dinamicamente - activando skills relevantes basados en la tarea y desactivando otros.
Ejemplo de estructura de skill:
## Skill de Revision de Codigo
Al revisar codigo, debes:
1. Verificar vulnerabilidades de seguridad (inyeccion, XSS, problemas de autenticacion)
2. Identificar preocupaciones de rendimiento
3. Evaluar legibilidad y mantenibilidad
4. Sugerir mejoras especificas con ejemplos de codigo
Formatea tu revision como:
- Resumen (1-2 oraciones)
- Problemas criticos (si hay)
- Sugerencias (lista con vinetas)
- Evaluacion generalAgentes de Programacion#
Por Que Importan#
Los agentes de programacion representan una de las aplicaciones mas tangibles de IA - realmente escriben codigo, y el codigo realmente funciona. Esto no es teorico; los desarrolladores estan entregando funcionalidades mas rapido gracias a estas herramientas.
El impacto es inmediato y medible: menos tiempo en codigo repetitivo, depuracion mas rapida, exploracion mas facil de bases de codigo desconocidas. Para muchos desarrolladores, los agentes de programacion se han vuelto tan esenciales como su IDE.
El Panorama#
Claude Code - El agente de programacion basado en terminal de Anthropic. Vive en tu CLI, entiende toda tu base de codigo, puede leer archivos, escribir codigo, ejecutar comandos, e iterar sobre retroalimentacion. Disenado para desarrolladores que viven en la terminal.
Cursor - Un IDE nativo de IA construido desde cero alrededor de asistencia de IA. No solo autocompletado - puedes chatear con tu base de codigo, generar funcionalidades completas, y hacer que la IA haga cambios amplios en archivos. Lo mas cercano a programar en pareja con una IA.
GitHub Copilot - El original y mas ampliamente desplegado. Empezo como autocompletado, evoluciono a chat, ahora incluye Copilot Workspace para tareas mas grandes. Integracion profunda con GitHub.
Windsurf - El IDE de IA de Codeium, posicionandose como alternativa a Cursor. Fuerte enfasis en velocidad y comprension de bases de codigo grandes.
Cody (Sourcegraph) - Se enfoca en comprension de bases de codigo. Particularmente fuerte para bases de codigo grandes y complejas donde el contexto es critico.
Continue - Asistente de programacion open-source que funciona con cualquier IDE. Trae tu propio modelo (local o en la nube). Bueno para equipos que quieren control sobre su configuracion de IA.
OpenCode - Alternativa open-source a Claude Code. Basado en terminal, agnostico de modelo, desarrollo impulsado por la comunidad.
Aider - Otro excelente agente de programacion terminal open-source. Conocido por su integracion con git y capacidad de trabajar con multiples archivos coherentemente.
Proximos Pasos#
Has llegado hasta los fundamentos. Que sigue?
Construir Cosas:#
- Empieza simple. Usa una API (OpenAI, Anthropic, etc.) y construye un chatbot basico o sistema RAG. No pienses demasiado en el stack inicialmente.
- Prueba modelos locales. Instala Ollama y ejecuta Llama o Qwen en tu laptop. Es sorprendentemente facil.
- Explora agentes. Revisa frameworks como LangChain, LlamaIndex, o CrewAI para construir sistemas de agentes.
- Aprende MCP. La documentacion oficial es solida. Intenta ejecutar algunos servidores MCP localmente.
- Construye evals temprano. Lo que sea que construyas, crea evals desde el dia uno. Te lo agradeceras despues.
Entender el Campo:#
- Sigue la investigacion. Articulos de ArXiv, alertas de Google Scholar en temas que te interesan.
- Lee el hype criticamente. La mayoria de los “avances” son incrementales. Busca resultados reproducibles y benchmarks reales.
- Experimenta tu mismo. La intuicion sobre lo que funciona viene de experiencia practica, no de leer.
Recursos:#
- Hugging Face - Modelos, datasets, y una comunidad increible
- Papers With Code - Articulos de investigacion con implementaciones
- Ollama - Ejecucion de modelos locales extremadamente simple
- LangChain / LlamaIndex - Frameworks populares para construir con LLMs
- Model Context Protocol - La especificacion y SDKs de MCP
- Chatbot Arena - Compara modelos cara a cara con votacion humana
La IA en 2026 esta simultaneamente sobrevalorada y subvalorada. La tecnologia es genuinamente transformadora - pero tambien genuinamente limitada. Los LLMs inventan cosas. Los agentes son fragiles. Los costos son altos. El progreso es rapido pero desigual.
El mejor enfoque es pragmatico: entiende los fundamentos, experimenta con problemas reales, mantente esceptico de las grandes afirmaciones, y construye cosas. Las personas que prosperaran en esta era no son las que pueden recitar cada acronimo - son las que pueden entregar productos que realmente funcionan.
Ahora ve y construye algo.