Día 16. ¿Y si el oponente IA realmente aprendiera de perder contra ti?
No un algoritmo minimax que juega perfectamente desde el principio. No un jugador aleatorio. Algo que empieza torpe, observa qué funciona y gradualmente descubre cómo ganarte. Eso es Q-learning. Y eso es lo que quise integrar en el juego más simple posible.
El Prompt#
“Construye un juego de tres en raya con una IA de Q-learning que aprenda de cada partida, persista su cerebro en localStorage y muestre estadísticas en tiempo real”
Cómo Se Construyó#
Watchfire dividió esto en 4 tareas:
- Estructura base del proyecto Next.js con el tablero de juego y el layout básico
- IA de Q-learning con estrategia epsilon-greedy y persistencia de la Q-table en localStorage
- Dashboard de estadísticas, visualización del cerebro de la IA y modo de entrenamiento para partidas masivas contra sí misma
- Modos de dificultad, resaltado de jugadas ganadoras, efectos de sonido y pulido final
La primera tarea me dio un tres en raya jugable. Nada especial. La segunda tarea es donde las cosas se pusieron interesantes, porque ahora la IA estaba realmente actualizando valores de estado-acción después de cada partida. Gana una partida contra ella y se ajusta. Gánale de la misma manera dos veces y empieza a bloquear esa jugada. La Q-table crece con cada partida.
Las tareas 3 y 4 lo transformaron de un experimento de aprendizaje en algo que puedes ver evolucionar. La visualización del cerebro muestra los Q-values para cada celda, el dashboard de estadísticas rastrea las tasas de victoria/derrota/empate a lo largo del tiempo, y el modo de entrenamiento te permite ejecutar miles de partidas de auto-juego para acelerar la educación de la IA.
Lo Que Obtuve#
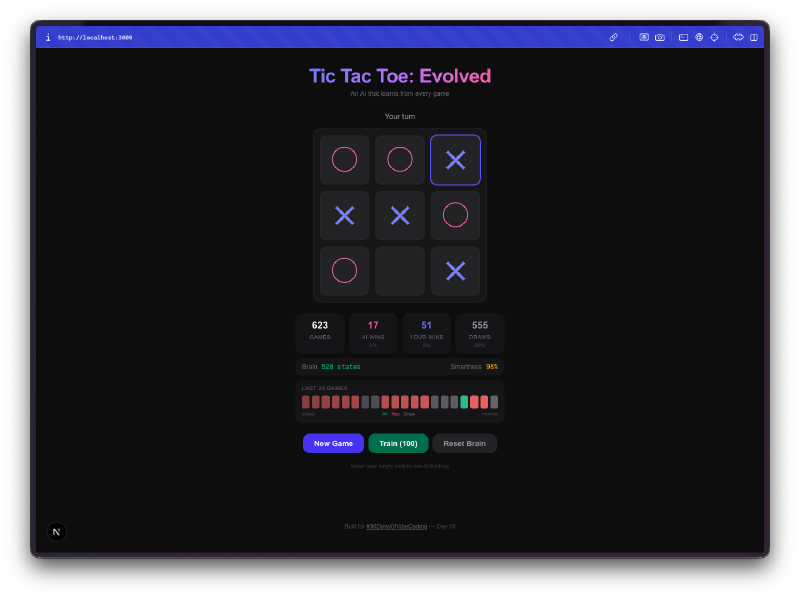
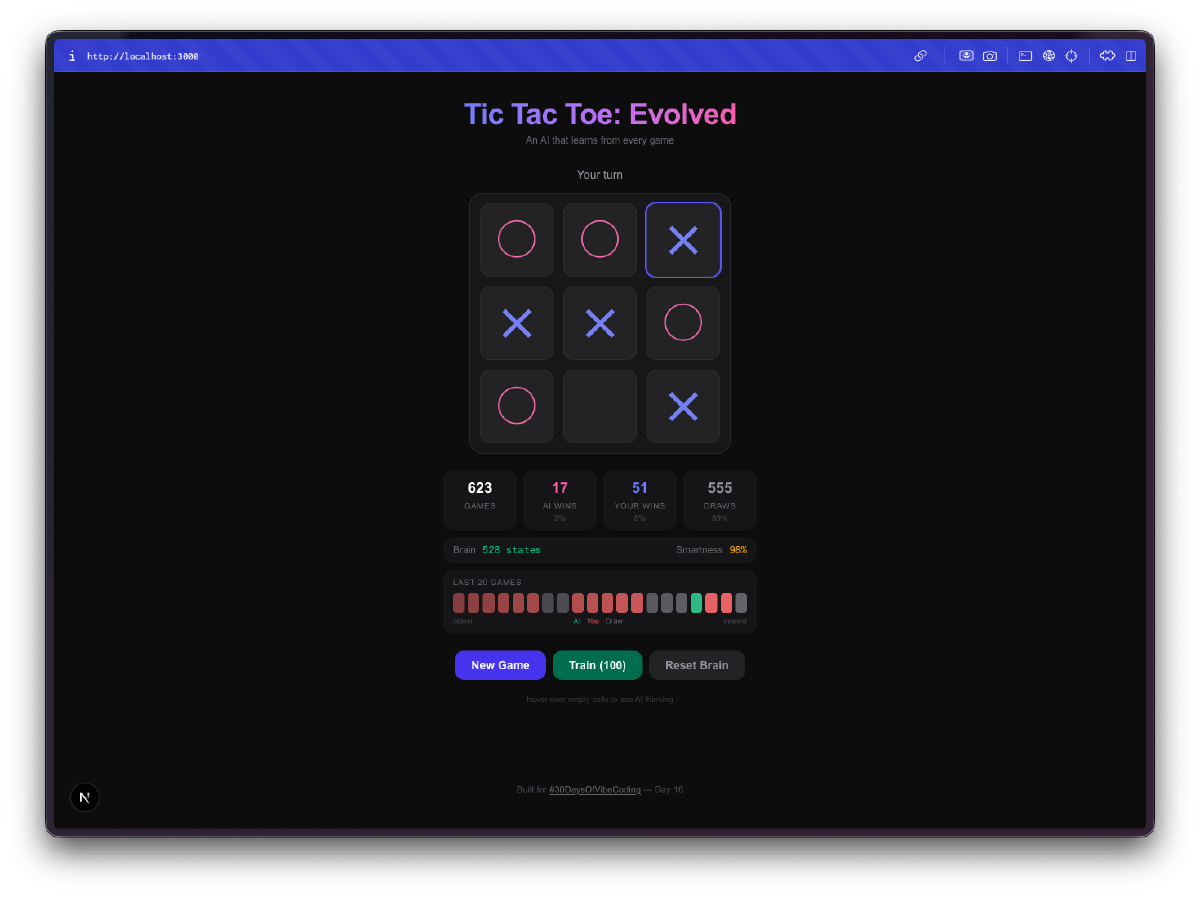
La IA empieza siendo terrible. En tus primeras partidas, juega casi aleatoriamente. Elige casillas sin estrategia, cae en las mismas trampas, pierde de formas obvias. Ese es precisamente el punto. Está explorando el espacio del juego, probando movimientos que no ha probado antes, construyendo su Q-table desde cero.
Luego deja de ser terrible. En algún momento entre 50 y 100 partidas, notas que bloquea tus jugadas ganadoras. Después de unos cientos de partidas, empata consistentemente. Entrénala con unos miles de partidas de auto-juego y buena suerte intentando ganar. La progresión de incompetente a competente es genuinamente divertida de observar.
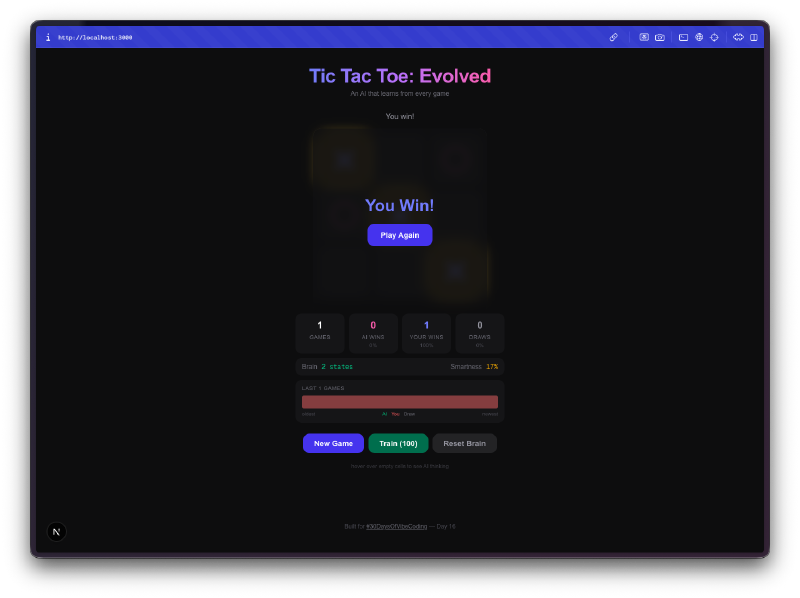
La visualización del cerebro es la mejor parte. Puedes pasar el ratón sobre las celdas y ver los Q-values que la IA ha aprendido para cada posición. Valores positivos altos significan que la IA cree que esa jugada lleva a una victoria. Valores negativos significan que ha aprendido a evitar esa casilla en el estado actual. Estás literalmente mirando la comprensión que la IA tiene del juego, y puedes ver esos números cambiar a medida que juega más.
El entrenamiento masivo es adictivo. Hay un modo de entrenamiento donde puedes ejecutar 100, 1.000 o 10.000 partidas de auto-juego. La IA juega contra sí misma, aprendiendo de ambos lados. Puedes ver el tamaño de la Q-table crecer en tiempo real mientras descubre nuevos estados del tablero. Después de 10.000 partidas, el cerebro ha visto miles de posiciones únicas y tiene una opinión firme sobre cada una de ellas.
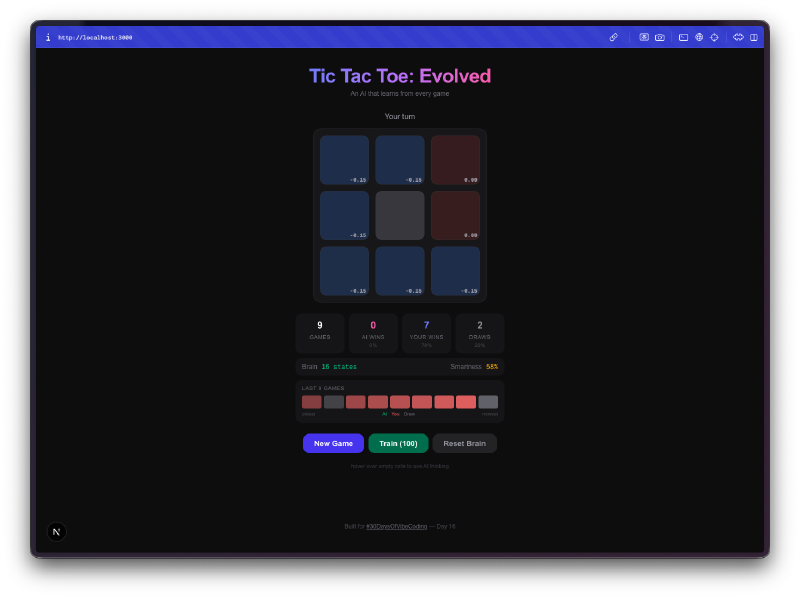
Todo persiste. Cierra la pestaña, vuelve mañana, y la IA recuerda todo lo que aprendió. La Q-table, las estadísticas de los juegos, el historial de rachas de victorias. Todo está guardado en localStorage. Tu oponente IA tiene memoria permanente, lo que significa que cuanto más juegues contra ella a lo largo de días y semanas, mejor se vuelve.
Los modos de dificultad cambian la tasa de exploración. El modo fácil mantiene el epsilon (aleatoriedad) alto para que la IA cometa más errores. El modo difícil reduce el epsilon para que casi siempre elija la jugada que cree mejor. Esto te permite controlar cuánto se basa la IA en lo que ha aprendido versus probar cosas nuevas.
Los pequeños detalles importan. Las líneas ganadoras se resaltan. Los efectos de sonido suenan en jugadas, victorias, derrotas y empates. Hay un historial de partidas recientes mostrando tus últimos 20 resultados como un tracker visual de rachas. Todo el conjunto se siente como un juego de verdad, no solo una demo técnica.
Los Números#
- 4 tareas en Watchfire desde la estructura base hasta el pulido
- La Q-table crece hasta miles de entradas después del entrenamiento masivo
- 3 modos de dificultad controlando el tradeoff exploración/explotación
- Persistencia total en localStorage para el cerebro de la IA y todas las estadísticas
- 0 estrategia hardcoded en la IA. Todo lo que sabe, lo aprendió
Pruébalo#
Juega unas cuantas rondas y observa cómo la IA mejora. O pulsa el botón de entrenamiento y déjala enseñarse a sí misma.
Veredicto del Día 16#
El tres en raya es un juego resuelto. Cualquier jugador perfecto puede forzar un empate siempre. Eso es exactamente lo que lo convierte en un gran campo de pruebas para el aprendizaje por refuerzo. El juego es lo suficientemente simple para que la IA pueda explorar todo el espacio de estados en un número razonable de partidas, y puedes realmente verla converger hacia el juego óptimo.
Lo que me gusta de este proyecto es que hace el machine learning tangible. No estás leyendo sobre Q-learning en un libro de texto ni viendo curvas de pérdida de entrenamiento en un Jupyter notebook. Estás jugando contra una IA que visiblemente se está volviendo más inteligente. Puedes ver sus Q-values, observar su cerebro crecer y sentir la diferencia entre jugar contra ella en la partida 10 versus la partida 10.000.
El hecho de que todo funcione en el navegador sin backend, sin Python, sin TensorFlow, solo TypeScript y localStorage, hace que se sienta accesible. El Q-learning es uno de los algoritmos de aprendizaje por refuerzo más simples, pero verlo funcionar en tiempo real en un juego que ya entiendes hace que el concepto haga clic de una manera que la teoría sola nunca consigue.
Este es el día 16 de 30 Days of Vibe Coding. Sígueme mientras lanzo 30 proyectos en 30 días usando programación asistida por IA.