Commencons par le debut et progressons etape par etape.
Fondements#
IA vs ML vs Deep Learning#
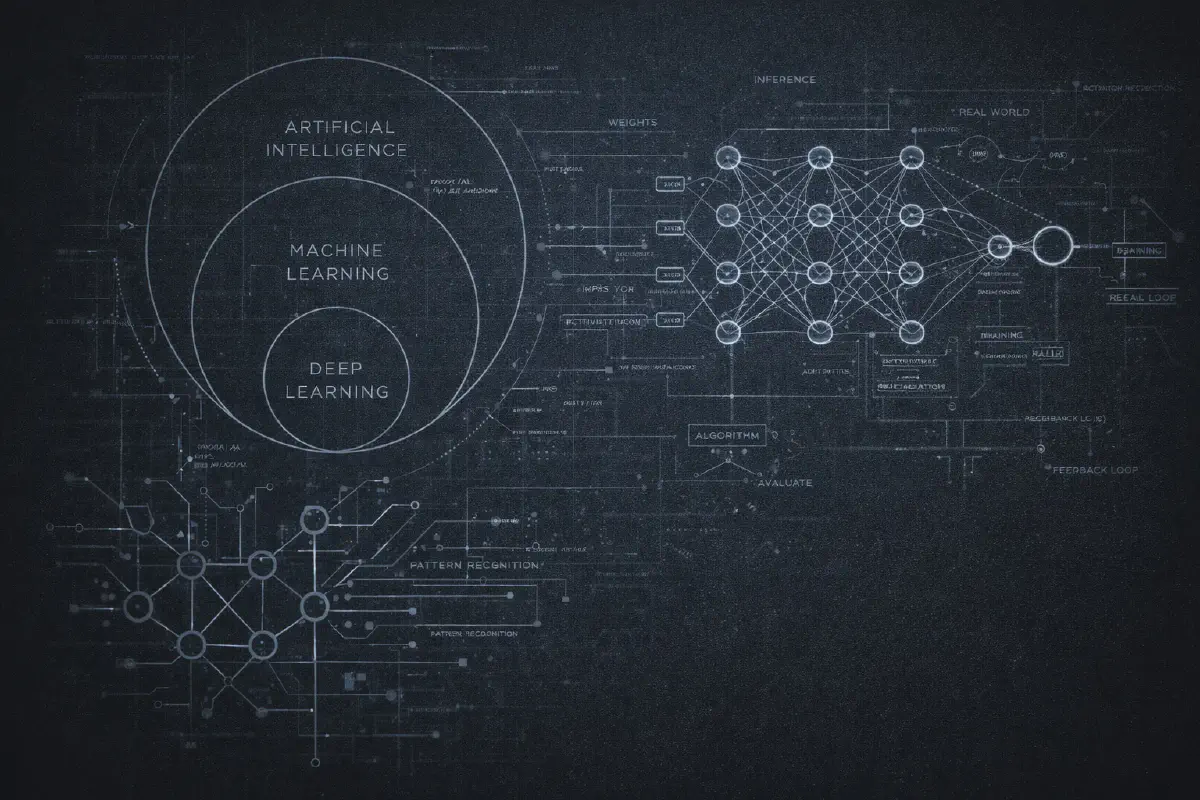
Vous avez probablement vu le diagramme : trois cercles concentriques avec l’IA a l’exterieur, le Machine Learning au milieu, et le Deep Learning au coeur. C’est devenu un cliche, mais c’est reellement utile pour comprendre comment ces termes sont lies.
L’Intelligence Artificielle est le terme le plus large. Cela signifie simplement “faire faire aux ordinateurs des choses qui necessiteraient de l’intelligence si des humains les faisaient”. C’est tout. Un programme d’echecs des annees 1970 ? De l’IA. Votre filtre anti-spam ? De l’IA. Une simple regle if-else qui decide d’afficher ou non une popup ? Techniquement, de l’IA. Le terme est si large qu’il est presque insignifiant en soi.
Le Machine Learning est un sous-ensemble de l’IA ou, au lieu de programmer des regles explicites, vous donnez a l’ordinateur des exemples et le laissez decouvrir les patterns. Au lieu d’ecrire “si l’email contient ‘prince nigerien’, marquer comme spam”, vous lui montrez 10 000 emails etiquetes “spam” ou “non spam” et laissez l’algorithme apprendre ce qui rend le spam… spammeux.
Le Deep Learning est un sous-ensemble du machine learning qui utilise des reseaux de neurones avec de nombreuses couches (d’ou le terme “deep”, profond). C’est la que les choses sont devenues interessantes dans les annees 2010. Le deep learning a permis des avancees majeures en reconnaissance d’images, reconnaissance vocale, et finalement les modeles de langage qui nous obsedent aujourd’hui.
Reseaux Neuronaux#
Voici une analogie imparfaite mais utile : un reseau de neurones est comme une feuille de calcul tres compliquee avec des millions de nombres ajustables.
Les donnees entrent d’un cote. Elles sont multipliees par ces nombres, additionnees, passees a travers des fonctions mathematiques, et finissent par produire une sortie de l’autre cote. La partie “apprentissage” consiste a ajuster tous ces nombres jusqu’a ce que les sorties correspondent a ce que vous voulez.
Si vous voulez aller plus loin : le reseau est organise en couches. Chaque couche contient des “neurones” (en realite juste des fonctions mathematiques). Chaque neurone prend des entrees, les multiplie par des poids, les additionne, et passe le resultat a travers une fonction d’activation. La magie se produit parce que lorsque vous empilez de nombreuses couches ensemble, le reseau peut apprendre des patterns incroyablement complexes - des choses qu’aucun humain ne pourrait programmer a la main.
Le terme “neural” vient d’une analogie approximative avec les neurones biologiques du cerveau. Ne prenez pas cela trop litteralement. Ces systemes ne fonctionnent pas du tout comme de vrais cerveaux. La metaphore etait utile pour les chercheurs originaux des annees 1940 mais est devenue quelque peu trompeuse.
Training vs Inference#
Chaque systeme d’IA a deux phases distinctes, et les confondre cause d’innombrables malentendus.
L’entrainement est la partie couteuse. C’est quand vous montrez au modele des millions (ou des milliards) d’exemples et ajustez tous ces nombres internes jusqu’a ce que le modele devienne bon dans sa tache. L’entrainement de GPT-4 aurait coute plus de 100 millions de dollars en calcul seul. L’entrainement se fait une fois (ou periodiquement quand vous voulez mettre a jour le modele).
L’inference est la partie peu couteuse - relativement parlant. C’est quand vous utilisez reellement le modele entraine. Vous lui donnez une entree, il produit une sortie. Chaque fois que vous discutez avec ChatGPT, vous faites de l’inference. Les nombres du modele sont geles ; il effectue juste des calculs.
Pensez-y comme l’education vs le travail. L’entrainement, ce sont des annees d’ecole et d’etude. L’inference, c’est aller au travail et utiliser ce que vous avez appris. L’investissement se fait en amont ; le retour vient pendant l’utilisation.
Comprendre les LLMs#
Ce qui rend les LLMs speciaux#
Les Large Language Models sont un type specifique de modele de deep learning entraine pour predire du texte. C’est l’idee centrale : au coeur, les LLMs essaient juste de predire le mot (ou token) suivant dans une sequence.
“Le chat s’est assis sur le ___” → “tapis” (probablement)
Mais voici ce qui est fou : quand vous entrainez cet objectif simple sur des milliers de milliards de mots d’internet, de livres, de code et d’articles scientifiques, quelque chose de remarquable se produit. Le modele n’apprend pas que la grammaire. Il apprend des faits, des patterns de raisonnement, des conventions de codage, et meme quelque chose qui ressemble au bon sens.
C’est ce qu’on appelle le comportement emergent - des capacites qui n’ont pas ete explicitement entrainees mais qui ont emerge de l’echelle de l’entrainement. Personne n’a programme GPT-4 pour ecrire de la poesie ou resoudre des problemes mathematiques. Ces capacites ont emerge de l’objectif de predire le token suivant vraiment, vraiment bien.
Transformers et Attention#
L’architecture qui a rendu les LLMs modernes possibles s’appelle le Transformer, introduit dans un article de 2017 au titre celebre “Attention Is All You Need” (L’attention est tout ce dont vous avez besoin).
L’innovation cle est le mecanisme d’attention. Les modeles precedents traitaient le texte sequentiellement - mot par mot, de gauche a droite. L’attention permet au modele de regarder tous les mots simultanement et d’apprendre quels mots sont pertinents les uns par rapport aux autres.
Exemple simple : “L’animal n’a pas traverse la rue parce qu’il etait trop fatigue.”
A quoi se refere “il” ? A l’animal. Mais comment le modele le sait-il ? Le mecanisme d’attention apprend que “il” devrait porter fortement son attention sur “animal” et faiblement sur “rue”. Cette capacite a capturer les dependances a longue portee est ce qui rend les Transformers si puissants pour le langage.
Tokens et fenetres de contexte#
Les LLMs ne voient pas vraiment les mots - ils voient des tokens. Un token est un morceau de texte, typiquement un mot ou une partie de mot. “Comprendre” pourrait etre un seul token, tandis que “com” + “prend” + “re” pourraient etre trois tokens selon le tokenizer du modele.
Pourquoi est-ce important ? Parce que les modeles ont des fenetres de contexte limitees - le nombre maximum de tokens qu’ils peuvent traiter en une fois. GPT-3 original avait une fenetre de 4K tokens. GPT-4 Turbo l’a etendue a 128K. Claude peut gerer 200K. Certains modeles plus recents annoncent des millions.
Pensez a la fenetre de contexte comme la memoire de travail du modele. Tout ce que vous voulez que le modele considere - votre question, les documents que vous partagez, l’historique de conversation - doit tenir dans cette fenetre.
| Modele | Fenetre de contexte | Equivalent approximatif |
|---|---|---|
| GPT-3 (2020) | 4K tokens | ~3 000 mots |
| GPT-4 Turbo | 128K tokens | ~100 000 mots |
| Claude 3.5 | 200K tokens | ~150 000 mots |
| Gemini 1.5 Pro | 1M+ tokens | ~750 000 mots |
Prompt Engineering#
Un prompt est simplement le texte que vous envoyez a un LLM. Votre question, vos instructions, tout contexte que vous fournissez - tout cela fait partie du prompt.
Le prompt engineering est l’art (et de plus en plus, la science) d’ecrire des prompts qui obtiennent de meilleurs resultats. Ca semble ridicule - “ingenierie” de vos questions ? - mais ca compte vraiment.
Quelques techniques qui fonctionnent :
- Soyez specifique. “Ecris un poeme” vs. “Ecris un sonnet de 14 vers sur le changement climatique dans le style de Shakespeare” - le second obtient des resultats nettement meilleurs.
- Montrez des exemples. Donnez au modele quelques exemples de ce que vous voulez avant de demander la sortie reelle. C’est appele le “few-shot prompting”.
- Pensez etape par etape. Ajouter “Reflechissons a cela etape par etape” avant un probleme complexe ameliore la precision. C’est appele le prompting “chain-of-thought” (chaine de pensee).
- Assignez un role. “Vous etes un expert comptable fiscaliste” concentre les reponses du modele.
Temperature & Parametres#
Quand vous utilisez une API LLM, vous pouvez ajuster plusieurs parametres qui affectent la sortie. Le plus important est la temperature.
La temperature controle l’aleatoire. A temperature 0, le modele choisit toujours le token suivant le plus probable - deterministe, previsible, parfois ennuyeux. A temperature 1 ou plus, il est plus enclin a choisir des tokens moins probables - plus creatif, plus varie, parfois incoherent.
- Temperature 0 : “La capitale de la France est Paris.”
- Temperature 1 : “La capitale de la France est Paris, cette magnifique ville lumiere ou la revolution et la romance dansent a travers les rues pavees…”
Autres parametres courants :
- Top-p (nucleus sampling) : Une autre facon de controler l’aleatoire en limitant quels tokens sont consideres.
- Max tokens : Quelle longueur la reponse peut avoir.
- Sequences d’arret : Indiquent au modele quand arreter de generer.
- Penalite de frequence/presence : Reduisent la repetition.
Hallucinations#
Les LLMs inventent des choses. Ils enoncent des faussetes avec une confiance totale. Ils citent des articles qui n’existent pas. Ils inventent des statistiques. C’est appele hallucination, et ce n’est pas un bug qui sera corrige - c’est une consequence du fonctionnement de ces modeles.
Rappelez-vous : les LLMs sont entraines pour predire du texte plausible, pas du texte vrai. Si vous posez des questions sur un sujet ou le modele a des donnees d’entrainement limitees, il generera quelque chose qui semble correct. Le modele n’a pas de verificateur de faits interne, pas de connexion a la verite terrain, pas de moyen de dire “je ne sais pas”.
Pourquoi cela arrive-t-il ?
- Objectif d’entrainement : Predire le token suivant, pas verifier la verite.
- Distribution de probabilite : Le modele echantillonne parmi les possibilites. Meme si la vraie reponse est la plus probable, l’echantillonnage peut choisir autre chose.
- Pas de conscience de la limite de connaissances : Le modele ne connait pas de maniere fiable les limites de ses connaissances.
Strategies pour reduire les hallucinations :
- Utiliser RAG pour ancrer les reponses dans des documents reels
- Demander au modele de citer ses sources et les verifier
- Baisser la temperature pour les taches factuelles
- Utiliser des sorties structurees qui contraignent la reponse
- Implementer des couches de verification des faits
Le paysage des modeles#
Modeles Open vs Closed#
Closed source : Vous pouvez utiliser le modele via API mais ne pouvez pas voir les poids, modifier l’architecture, ou l’executer vous-meme. GPT-4 d’OpenAI, Claude d’Anthropic, Gemini de Google.
Open source/open weights : Les poids sont publiquement disponibles. Vous pouvez les telecharger, les executer localement, les fine-tuner, les modifier. Llama de Meta, Mistral, Qwen d’Alibaba, DeepSeek, et bien d’autres.
La distinction est importante mais nuancee :
- “Open weights” signifie que vous pouvez telecharger et executer le modele
- “Open source” signifie traditionnellement que le code d’entrainement et les donnees sont aussi disponibles (rare pour les grands modeles)
- Les licences varient - certains modeles ouverts ont des restrictions commerciales
Pourquoi Meta publie-t-il Llama gratuitement ? Raisons strategiques : commoditiser le complement, construire un ecosysteme, attirer les talents, etablir des standards. La vue cynique : ils ne peuvent pas concurrencer OpenAI sur les revenus API, donc ils concurrencent en rendant la couche modele gratuite et en profitant ailleurs.
Modeles multimodaux#
Les premiers LLMs ne comprenaient que le texte. Les modeles multimodaux comprennent plusieurs types de donnees - texte, images, audio, video.
GPT-4V peut regarder une photo et la decrire. Claude peut analyser des graphiques et diagrammes. Gemini peut regarder des videos. Ce n’est pas juste de la nouveaute - cela ouvre des cas d’usage entierement nouveaux :
- Faire une capture d’ecran d’un bug et demander de l’aide pour le debugger
- Telecharger un diagramme manuscrit et obtenir du code
- Analyser des images medicales
- Traiter des videos pour la moderation de contenu
- Interfaces vocales sans reconnaissance vocale separee
Les architectures varient. Certains modeles sont entraines nativement multimodaux. D’autres connectent des modeles de vision et de langage separes. La distinction compte pour la performance mais pas pour la plupart des utilisateurs.
Modeles de raisonnement#
Les LLMs standards generent des reponses token par token sans “reflexion” explicite. Les modeles de raisonnement adoptent une approche differente - ils depensent du calcul supplementaire pour reflechir aux problemes avant de repondre.
Les modeles o1 et o3 d’OpenAI ont ete pionniers de cette approche. Au lieu de repondre immediatement, ces modeles generent des chaines de raisonnement internes (parfois cachees aux utilisateurs), considerent plusieurs approches, et verifient leur travail avant de produire une reponse finale.
Les resultats sont frappants : les modeles de raisonnement surpassent dramatiquement les LLMs standards sur les mathematiques, le codage, la science et les problemes de logique. o3 a atteint des scores sur certains benchmarks qui etaient penses etre a des annees de distance.
Le compromis : les modeles de raisonnement sont plus lents et plus chers. Une question simple que GPT-4 repond instantanement pourrait prendre a o1 plusieurs secondes (et 10x le cout) pendant qu’il “reflechit”. Pour des taches simples, c’est du gaspillage. Pour des problemes difficiles, ca en vaut la peine.
Quand utiliser les modeles de raisonnement :
- Problemes mathematiques ou logiques complexes
- Defis de codage multi-etapes
- Taches necessitant une analyse soigneuse
- Tout ce ou la precision compte plus que la vitesse
Quand les LLMs standards sont meilleurs :
- Questions-reponses simples
- Ecriture creative
- Applications en temps reel
- Cas d’usage sensibles aux couts
Produits IA grand public#
Avant de plonger plus profondement dans les details techniques, cartographions les produits que vous avez probablement deja utilises :
ChatGPT (OpenAI) - Le produit qui a lance la vague IA grand public. Acces a GPT-4, o1, DALL-E pour les images, et divers plugins. Le benchmark auquel tout le monde est compare.
Claude (Anthropic) - Connu pour une ecriture forte, de grandes fenetres de contexte, et un raisonnement nuance. Claude.ai est l’interface grand public ; l’API alimente de nombreuses applications.
Gemini (Google) - Profondement integre avec l’ecosysteme Google. Acces via gemini.google.com et de plus en plus integre dans Search, Docs, Gmail et Android.
Copilot (Microsoft) - La couche IA de Microsoft a travers leurs produits. Different de GitHub Copilot (codage) - c’est l’assistant grand public dans Windows, Edge et Microsoft 365.
Perplexity - Moteur de recherche natif IA. Repond aux questions avec citations et sources. Un apercu de ce que la recherche pourrait devenir.
Autres a connaitre : Grok (xAI, integre dans X/Twitter), Pi (Inflection), Le Chat (Mistral), DeepSeek Chat, et de nombreuses alternatives regionales/specialisees.
Executer des modeles localement#
Pourquoi executer localement ?#
Les modeles cloud tournent sur les serveurs de quelqu’un d’autre. Vous envoyez des requetes via internet et payez a l’utilisation. OpenAI, Anthropic, Google - c’est leur business.
Les modeles locaux tournent sur votre propre materiel. Votre laptop, vos serveurs, votre data center. Les donnees ne quittent jamais votre controle.
Pourquoi executer localement ?
- Confidentialite : Les donnees sensibles restent sur site
- Cout : Pas de frais API (mais le materiel n’est pas gratuit)
- Latence : Pas d’aller-retour reseau
- Disponibilite : Fonctionne hors ligne, pas de limites de taux
- Controle : Pas de conditions d’utilisation, pas de filtres de contenu que vous n’avez pas choisis
L’ecart entre local et cloud s’est reduit dramatiquement. Pour de nombreuses applications pratiques, les modeles locaux sont suffisamment bons - surtout pour le codage, l’ecriture et les taches d’analyse.
Le compromis : les capacites de pointe necessitent encore le cloud. Si vous avez besoin de la meilleure performance absolue sur des taches de raisonnement difficiles, GPT-4, Claude ou Gemini ne sont disponibles que dans le cloud. Mais cet ecart se reduit a chaque nouvelle version.
Ollama#
Ollama est devenu le standard de facto pour executer des modeles localement. Il rend ce qui etait un processus complexe trivialement facile.
# Installer et executer un modele en deux commandes
ollama pull llama3.2
ollama run llama3.2C’est tout. Vous discutez avec un LLM capable qui tourne entierement sur votre machine.
Ollama gere la complexite : telecharger les modeles, gerer la memoire, optimiser pour votre materiel, et fournir a la fois une CLI et une API locale. Il supporte des dizaines de modeles - Llama, Mistral, Qwen, Phi, CodeLlama, et bien d’autres.
Fonctionnalites cles :
- Interface CLI simple
- API compatible OpenAI (facile a integrer dans le code existant)
- Bibliotheque de modeles avec telechargements en une commande
- Fonctionne sur Mac, Linux et Windows
- Acceleration GPU quand disponible
Pour les developpeurs, l’API locale d’Ollama signifie que vous pouvez developper contre des modeles locaux et passer aux API cloud pour la production - ou vice versa - avec des changements de code minimaux.
Considerations materielles#
Executer des modeles localement necessite du materiel. Voici ce qui compte :
GPU vs CPU : Les GPU accelerent dramatiquement l’inference. Un modele qui prend 30 secondes par reponse sur CPU pourrait prendre 2 secondes sur GPU. Les Mac Apple Silicon brouillent cette ligne - leur memoire unifiee et Neural Engine les rendent etonnamment capables pour l’inference locale.
Memoire (VRAM/RAM) : C’est generalement le facteur limitant. Les modeles doivent tenir en memoire. Un modele de 7B parametres necessite environ 4-8 Go. Un modele de 70B necessite 35-70 Go. La quantification (discutee ci-dessous) reduit ces exigences.
Quantification : Reduire la precision des poids du modele de 32 bits a 16 bits, 8 bits, ou meme 4 bits. Cela reduit les besoins en memoire et accelere l’inference avec une perte de qualite minimale. La plupart des modeles locaux sont distribues dans des formats quantifies (GGUF, GPTQ, AWQ).
Guide pratique :
- Mac avec 16 Go+ RAM : Peut executer confortablement des modeles 7B-13B
- Mac avec 32 Go+ RAM : Peut executer des modeles 30B+
- PC avec RTX 3090/4090 (24 Go VRAM) : Peut executer la plupart des modeles jusqu’a 70B (quantifies)
- Pas de GPU : Fonctionne quand meme, juste plus lentement. Bien pour le developpement et l’experimentation.
Personnalisation et connaissances#
Fine-Tuning vs RAG#
Vous avez un LLM de base. Vous voulez le rendre meilleur pour votre cas d’usage specifique. Deux approches principales :
Fine-Tuning#
Prendre un modele existant et continuer a l’entrainer sur vos propres donnees. Les poids du modele changent reellement. Apres le fine-tuning, le modele “connait” vos informations nativement.
Avantages : Inference rapide, integration profonde des connaissances, peut apprendre de nouveaux styles ou comportements. Inconvenients : Couteux, necessite une expertise ML, les connaissances peuvent devenir obsoletes, risque d’oubli catastrophique (le modele devient moins bon sur d’autres taches).
RAG (Retrieval-Augmented Generation)#
Gardez le modele tel quel. Quand une question arrive, cherchez d’abord dans votre base de connaissances les documents pertinents, puis incluez ces documents dans le prompt avec la question.
Avantages : Moins cher, les connaissances restent a jour, pas d’entrainement requis, facile a auditer (vous pouvez voir ce qui a ete recupere). Inconvenients : Plus lent (processus en deux etapes), limite par la fenetre de contexte, la qualite de la recuperation compte beaucoup.
Embeddings & Vector DBs#
C’est la technologie qui fait fonctionner RAG - et c’est vraiment ingenieux.
Un embedding est une facon de representer du texte (ou des images, ou n’importe quoi) comme une liste de nombres - un vecteur. La magie : les choses similaires ont des vecteurs similaires. “Chien” et “chiot” ont des vecteurs proches. “Chien” et “democratie” sont eloignes.
Vous creez des embeddings en utilisant des modeles d’embedding (differents des LLMs, bien que certains LLMs aient des capacites d’embedding). OpenAI, Cohere, Voyage, et bien d’autres offrent des API d’embedding. Les options open source comme BGE et E5 fonctionnent tres bien aussi.
Une base de donnees vectorielle est une base de donnees optimisee pour stocker et rechercher ces vecteurs. Quand vous demandez “Quelle est notre politique de remboursement ?”, le systeme :
- Convertit votre question en vecteur
- Recherche dans la base de donnees vectorielle les vecteurs similaires
- Retourne les documents que ces vecteurs representent
- Nourrit ces documents dans le LLM avec votre question
Les bases de donnees vectorielles populaires incluent Pinecone, Weaviate, Chroma, Qdrant et Milvus. Postgres avec pgvector fonctionne etonnamment bien pour de nombreux cas d’usage.
Evaluation#
Benchmarks#
Comment savoir si un modele est “meilleur” qu’un autre ? Les benchmarks tentent de repondre a cette question en testant les modeles sur des taches standardisees.
Benchmarks courants :
- MMLU (Massive Multitask Language Understanding) : Questions a choix multiples sur 57 sujets. Teste les connaissances generales.
- HumanEval : Problemes de codage. Teste les capacites de programmation.
- GSM8K : Problemes de mathematiques de niveau primaire. Teste le raisonnement mathematique.
- HellaSwag : Raisonnement de bon sens sur des situations quotidiennes.
- TruthfulQA : Teste si les modeles donnent des reponses veridiques vs. des absurdites convaincantes.
Le probleme avec les benchmarks : Ils sont jouables. Les modeles peuvent etre entraines specifiquement pour bien performer sur les benchmarks populaires sans reellement s’ameliorer sur les vraies taches. Un modele qui score 90% sur MMLU pourrait quand meme echouer sur votre cas d’usage specifique.
Evals#
Les evals (evaluations) sont des tests que vous creez pour votre cas d’usage specifique. Contrairement aux benchmarks, les evals mesurent ce qui compte vraiment pour votre application.
Vous construisez un bot de service client ? Vos evals pourraient tester :
- Repond-il correctement aux questions de votre FAQ ?
- Escalade-t-il de maniere appropriee vers des humains quand necessaire ?
- Reste-t-il fidele a la marque et suit-il vos directives de ton ?
- Refuse-t-il de faire des promesses que l’entreprise ne peut pas tenir ?
Pourquoi les evals comptent :
- Detection de regression : Quand vous changez les prompts ou changez de modele, les evals attrapent les problemes avant les utilisateurs.
- Comparaison : Comparer objectivement differents modeles, prompts ou approches pour votre cas d’usage.
- Iteration : Vous ne pouvez pas ameliorer ce que vous ne pouvez pas mesurer. Les evals rendent l’amelioration systematique.
Construire de bons evals :
- Commencez avec de vraies requetes utilisateurs et reponses attendues
- Incluez des cas limites et des exemples adverses
- Testez a la fois ce que le modele devrait faire ET ce qu’il ne devrait pas
- Automatisez pour pouvoir executer les evals a chaque changement
LLM comme juge#
Voici une technique astucieuse : utiliser un LLM pour evaluer les sorties d’un autre LLM.
Au lieu de revoir manuellement des centaines de reponses, vous pouvez prompter un modele pour agir comme juge :
Vous evaluez la qualite de la reponse d'un assistant IA.
Question de l'utilisateur : {question}
Reponse de l'assistant : {response}
Notez la reponse sur :
1. Exactitude (1-5) : Les informations sont-elles correctes ?
2. Utilite (1-5) : Cela aide-t-il vraiment l'utilisateur ?
3. Clarte (1-5) : Est-ce facile a comprendre ?
Expliquez votre raisonnement, puis fournissez les scores.Pourquoi ca fonctionne :
- Passe a l’echelle de milliers d’evaluations
- Plus coherent que les evaluateurs humains (moins de fatigue)
- Peut evaluer des qualites nuancees difficiles a tester programmatiquement
- Moins cher et plus rapide que l’evaluation humaine
Limitations :
- Le modele juge a ses propres biais et limitations
- Peut manquer des erreurs qu’il ferait lui-meme
- A du mal avec l’exactitude specifique au domaine sans ancrage
- Pas un remplacement complet de l’evaluation humaine - plutot un complement
Agents et automatisation#
Que sont les agents ?#
Le terme “agent” est utilise a toutes les sauces. Voici une definition de travail : un agent est un LLM qui peut prendre des actions dans le monde, pas seulement generer du texte.
Un chatbot repond a vos questions. Un agent pourrait repondre a vos questions et reserver une table de restaurant, envoyer un email, interroger une base de donnees, ou ecrire et executer du code pour resoudre un probleme.
Qu’est-ce qui fait qu’une chose est un agent vs. juste un LLM ?
- Objectifs : Les agents travaillent vers des objectifs, pas seulement repondre aux prompts.
- Actions : Les agents peuvent faire des choses, pas seulement dire des choses.
- Autonomie : Les agents prennent des decisions sur comment atteindre les objectifs.
- Boucles : Les agents tournent souvent en boucles - observer, reflechir, agir, repeter.
Le pattern d’agent le plus simple : donner a un LLM acces a des outils et le laisser decider lesquels utiliser. “Trouve des vols de Londres a Tokyo la semaine prochaine, verifie mon calendrier, et reserve l’option la moins chere qui fonctionne avec mon emploi du temps.” L’agent decompose cela, appelle les API de vols, appelle les API de calendrier, et execute la reservation.
Agents vs workflows#
Une distinction importante qui est souvent floue :
Les workflows sont deterministes. Vous definissez les etapes : d’abord faire A, puis faire B, puis si X faire C sinon faire D. Le LLM peut alimenter des etapes individuelles, mais l’orchestration est codee.
1. Extraire les entites de l'email (LLM)
2. Chercher le client dans la base de donnees (code)
3. Generer un brouillon de reponse (LLM)
4. Envoyer pour revue humaine (code)Les agents sont autonomes. Vous leur donnez un objectif et des outils, et ils determinent les etapes. Le LLM decide quoi faire ensuite base sur l’etat actuel.
Objectif : "Resoudre cette plainte client"
Outils : [email, base_de_donnees, systeme_remboursement, escalade]
→ L'agent decide quoi faire, dans quel ordreQuand utiliser les workflows :
- Processus previsibles et bien compris
- Quand vous avez besoin de fiabilite et d’auditabilite
- Environnements reglementes
- Taches a haut volume et faible complexite
Quand utiliser les agents :
- Taches nouvelles ou variables
- Quand les etapes ne sont pas connues a l’avance
- Raisonnement complexe requis
- Quand la flexibilite compte plus que la previsibilite
L’equation des couts : Les workflows sont significativement moins chers. Vous payez pour un nombre fixe d’appels LLM par execution - previsible, optimisable, auditable. Les agents sont chers parce qu’ils reflechissent. Chaque point de decision - “quel outil devrais-je utiliser ?”, “est-ce que ca a marche ?”, “quelle est la suite ?” - est un appel LLM. Un workflow qui fait 3 appels LLM pourrait devenir un agent qui fait 15-30 appels pour resoudre le meme probleme, parce que l’agent raisonne sur comment le resoudre, pas juste executer des etapes predefinies. Pour des taches bien comprises a l’echelle, les workflows gagnent sur le cout. Pour des problemes complexes et variables ou vous ne pouvez pas predefinir les etapes, les agents valent la prime.
Tool Use & Function Calling#
Pour que les agents prennent des actions, ils ont besoin d’outils - des fonctions qu’ils peuvent appeler. Cette capacite est generalement appelee function calling ou tool use.
Voici comment ca fonctionne :
- Vous definissez les outils avec des noms, descriptions et parametres (generalement comme schemas JSON)
- Vous incluez ces definitions dans votre prompt/appel API
- Le modele peut choisir d’“appeler” un outil au lieu de generer du texte
- Votre code execute la fonction et retourne les resultats au modele
- Le modele utilise ces resultats pour continuer
Exemple de definition d’outil :
{
"name": "get_weather",
"description": "Get current weather for a city",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "City name"},
"units": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["city"]
}
}Quand vous demandez “Quel temps fait-il a Tokyo ?”, le modele n’hallucine pas - il appelle get_weather(city="Tokyo"), obtient des donnees reelles, et repond avec des faits.
Tous les principaux fournisseurs de modeles supportent maintenant le function calling : OpenAI, Anthropic, Google, et d’autres. La syntaxe varie legerement mais le concept est le meme.
Protocole MCP#
Model Context Protocol (MCP) est un standard ouvert pour connecter les modeles d’IA aux outils et sources de donnees. Pensez-y comme l’USB-C pour l’IA - un connecteur universel qui signifie que vous n’avez pas besoin d’un cable different pour chaque appareil.
Avant MCP, chaque integration etait personnalisee. Vous voulez que votre IA accede a GitHub ? Ecrire une integration GitHub. Salesforce ? Une autre integration. Votre base de donnees interne ? Encore une autre. Ca ne passe pas a l’echelle.
MCP definit une facon standard pour les clients IA (comme Claude, ChatGPT, ou votre agent personnalise) de decouvrir et utiliser des outils depuis les serveurs MCP. Un serveur MCP peut exposer :
- Outils : Fonctions que l’IA peut appeler
- Ressources : Donnees que l’IA peut lire
- Prompts : Templates pour les taches courantes
Les implications sont significatives :
- Construisez un serveur MCP une fois, chaque IA compatible peut l’utiliser
- Les outils deviennent portables et reutilisables
- La securite et les permissions peuvent etre standardisees
- L’ecosysteme se compose - plus de serveurs signifie des agents plus capables
Pour en savoir plus sur MCP, j’ai ecrit un article plus approfondi : MCP Servers: The USB-C Moment for AI Agents.
Patterns agentiques#
Avec la maturation des agents, des patterns communs ont emerge :
ReAct (Reason + Act) : L’agent alterne entre raisonnement (“J’ai besoin de trouver l’historique de commandes de l’utilisateur”) et action (appeler l’API de commandes). Cette etape de raisonnement explicite ameliore la fiabilite.
Planning : Avant d’agir, l’agent cree un plan : “Pour resoudre cela, je devrai 1) chercher la commande, 2) verifier l’inventaire, 3) traiter le remboursement, 4) envoyer la confirmation.” Les plans peuvent etre valides avant execution.
Reflexion : Apres avoir complete une tache (ou echoue), l’agent revoit ce qui s’est passe : “Le remboursement a echoue parce que la commande etait trop ancienne. J’aurais du verifier la politique de remboursement d’abord.” Cela permet l’apprentissage et l’auto-correction.
Selection d’outils : Quand un agent a beaucoup d’outils, choisir le bon devient non-trivial. Les techniques incluent les descriptions d’outils, les exemples few-shot, et l’organisation hierarchique des outils.
Humain dans la boucle : Pour les actions a haut risque, les agents peuvent pauser et demander l’approbation humaine avant de continuer. Les bons agents savent quand ils sont incertains.
Skills#
Les skills (competences) sont des prompts specialises et reutilisables qui etendent ce qu’un agent peut faire. Pensez-y comme des “modes expert” que vous pouvez brancher a un agent - un skill pour la revue de code, un skill pour la redaction de documentation, un skill pour l’analyse de vulnerabilites de securite.
Contrairement aux outils (qui sont des fonctions qui font des choses), les skills sont des instructions qui faconnent comment l’agent pense et repond. Un outil appelle une API. Un skill dit a l’agent “quand on te demande X, aborde-le de cette maniere, considere ces facteurs, et formate ta reponse comme ceci.”
Pourquoi les skills sont importants :
- Specialisation sans fine-tuning : Vous obtenez un comportement expert sans entrainer un nouveau modele.
- Composabilite : Mixez et combinez les skills pour differentes taches.
- Partageabilite : Un skill bien concu peut etre utilise a travers les equipes, les projets, ou meme partage publiquement.
- Efficacite du contexte : Au lieu d’expliquer vos exigences a chaque fois, encodez-les une fois dans un skill.
Ou vivent les skills :
Les skills peuvent etre injectes a differents points dans le contexte de l’agent :
- Prompt systeme : L’approche la plus courante. Les skills deviennent partie des instructions de base de l’agent, toujours actifs.
- Prefixe du message utilisateur : Preprend dynamiquement aux requetes utilisateur. Utile pour les skills specifiques a une tache.
- Descriptions d’outils : Les skills peuvent etre integres dans les definitions d’outils, guidant comment l’agent utilise des outils specifiques.
- Prompts MCP : Les serveurs MCP peuvent exposer des skills comme “prompts” - des templates reutilisables que les clients peuvent decouvrir et invoquer.
Comment les skills influencent le contexte :
Chaque skill consomme des tokens de votre fenetre de contexte. Cela cree des compromis :
- Plus de skills = agent plus capable, mais moins de place pour l’historique de conversation
- Skills detailles = meilleur comportement, mais cout en tokens plus eleve par requete
- Skills toujours actifs vs. skills a la demande = fiabilite vs. efficacite
Les frameworks d’agents intelligents gerent cela en chargeant les skills dynamiquement - activant les skills pertinents en fonction de la tache et desactivant les autres.
Exemple de structure de skill :
## Skill de Revue de Code
Lors de la revue de code, vous devez :
1. Verifier les vulnerabilites de securite (injection, XSS, problemes d'auth)
2. Identifier les problemes de performance
3. Evaluer la lisibilite et la maintenabilite
4. Suggerer des ameliorations specifiques avec des exemples de code
Formatez votre revue comme :
- Resume (1-2 phrases)
- Problemes critiques (s'il y en a)
- Suggestions (liste a puces)
- Evaluation globaleAgents de codage#
Pourquoi ils comptent#
Les agents de codage representent l’une des applications les plus tangibles de l’IA - ils ecrivent vraiment du code, et le code fonctionne vraiment. Ce n’est pas theorique ; les developpeurs livrent des fonctionnalites plus vite grace a ces outils.
L’impact est immediat et mesurable : moins de temps sur le boilerplate, debugging plus rapide, exploration plus facile de codebases inconnues. Pour de nombreux developpeurs, les agents de codage sont devenus aussi essentiels que leur IDE.
Le paysage#
Claude Code - L’agent de codage base terminal d’Anthropic. Vit dans votre CLI, comprend toute votre codebase, peut lire des fichiers, ecrire du code, executer des commandes, et iterer sur le feedback. Concu pour les developpeurs qui vivent dans le terminal.
Cursor - Un IDE natif IA construit from scratch autour de l’assistance IA. Pas juste de l’autocompletion - vous pouvez discuter avec votre codebase, generer des fonctionnalites entieres, et faire faire a l’IA des changements balayant plusieurs fichiers. Ce qui se rapproche le plus du pair programming avec une IA.
GitHub Copilot - L’original et le plus largement deploye. A commence comme autocompletion, a evolue vers le chat, inclut maintenant Copilot Workspace pour des taches plus larges. Integration profonde avec GitHub.
Windsurf - L’IDE IA de Codeium, se positionnant comme alternative a Cursor. Fort accent sur la vitesse et la comprehension de grandes codebases.
Cody (Sourcegraph) - Se concentre sur la comprehension de codebase. Particulierement fort pour les grandes codebases complexes ou le contexte est critique.
Continue - Assistant de codage open-source qui fonctionne avec n’importe quel IDE. Apportez votre propre modele (local ou cloud). Bon pour les equipes qui veulent le controle sur leur setup IA.
OpenCode - Alternative open-source a Claude Code. Base terminal, agnostique au modele, developpement dirige par la communaute.
Aider - Un autre excellent agent de codage terminal open-source. Connu pour son integration git et sa capacite a travailler avec plusieurs fichiers de maniere coherente.
Prochaines Etapes#
Vous avez traverse les fondamentaux. Et maintenant ?
Construire des choses#
- Commencez simple. Utilisez une API (OpenAI, Anthropic, etc.) et construisez un chatbot basique ou un systeme RAG. Ne surchargez pas la stack au debut.
- Essayez les modeles locaux. Installez Ollama et executez Llama ou Qwen sur votre laptop. C’est etonnamment facile.
- Explorez les agents. Decouvrez des frameworks comme LangChain, LlamaIndex, ou CrewAI pour construire des systemes d’agents.
- Apprenez MCP. La documentation officielle est solide. Essayez d’executer quelques serveurs MCP localement.
- Construisez des evals tot. Quoi que vous construisiez, creez des evals des le premier jour. Vous vous remercierez plus tard.
Comprendre le domaine#
- Suivez la recherche. Articles ArXiv, alertes Google Scholar sur les sujets qui vous interessent.
- Lisez le hype de maniere critique. La plupart des “percees” sont incrementales. Cherchez des resultats reproductibles et de vrais benchmarks.
- Experimentez vous-meme. L’intuition sur ce qui fonctionne vient de l’experience pratique, pas de la lecture.
Ressources#
- Hugging Face - Modeles, datasets, et une communaute incroyable
- Papers With Code - Articles de recherche avec implementations
- Ollama - Execution de modeles locaux ultra simple
- LangChain / LlamaIndex - Frameworks populaires pour construire avec les LLMs
- Model Context Protocol - La specification MCP et les SDKs
- Chatbot Arena - Comparez les modeles en tete-a-tete avec vote humain
L’IA en 2026 est simultanement surevaluee et sous-evaluee. La technologie est reellement transformatrice - mais elle est aussi reellement limitee. Les LLMs inventent des choses. Les agents sont fragiles. Les couts sont eleves. Le progres est rapide mais inegal.
La meilleure approche est pragmatique : comprendre les fondamentaux, experimenter avec de vrais problemes, rester sceptique face aux grandes declarations, et construire des choses. Les personnes qui prospereront dans cette ere ne sont pas celles qui peuvent reciter chaque acronyme - ce sont celles qui peuvent livrer des produits qui fonctionnent vraiment.
Maintenant allez construire quelque chose.