Jour 16. Et si l’adversaire IA apprenait vraiment de ses defaites contre vous ?
Pas un algorithme minimax qui joue parfaitement des le depart. Pas un joueur aleatoire. Quelque chose qui commence bete, observe ce qui marche, et finit par comprendre comment vous battre. C’est le Q-learning. Et c’est ce que je voulais integrer au jeu le plus simple possible.
Le Prompt#
“Construis un jeu de tic-tac-toe avec une IA Q-learning qui apprend de chaque partie, sauvegarde son cerveau dans le localStorage, et affiche des stats en temps reel”
Comment c’a ete construit#
Watchfire a decoupe le projet en 4 taches :
- Scaffolding du projet Next.js avec le plateau de jeu de base et la mise en page
- IA Q-learning avec une strategie epsilon-greedy et persistence localStorage pour la Q-table
- Tableau de bord des stats, visualisation du cerveau de l’IA, et un mode entrainement pour le jeu en masse contre elle-meme
- Modes de difficulte, mise en surbrillance des coups gagnants, effets sonores, et finitions
La premiere tache m’a donne un tic-tac-toe jouable. Rien de special. La deuxieme tache, c’est la que ca devient interessant, parce que maintenant l’IA mettait vraiment a jour les valeurs etat-action apres chaque partie. Gagnez une partie contre elle, et elle s’ajuste. Battez-la de la meme maniere deux fois, et elle commence a bloquer ce coup. La Q-table grandit a chaque match.
Les taches 3 et 4 ont transforme l’experience d’apprentissage en quelque chose qu’on peut vraiment regarder evoluer. La visualisation du cerveau montre les Q-values pour chaque case, le tableau de bord suit les taux de victoire/defaite/match nul au fil du temps, et le mode entrainement permet de lancer des milliers de parties contre elle-meme pour accelerer l’education de l’IA.
Ce que j’ai obtenu#
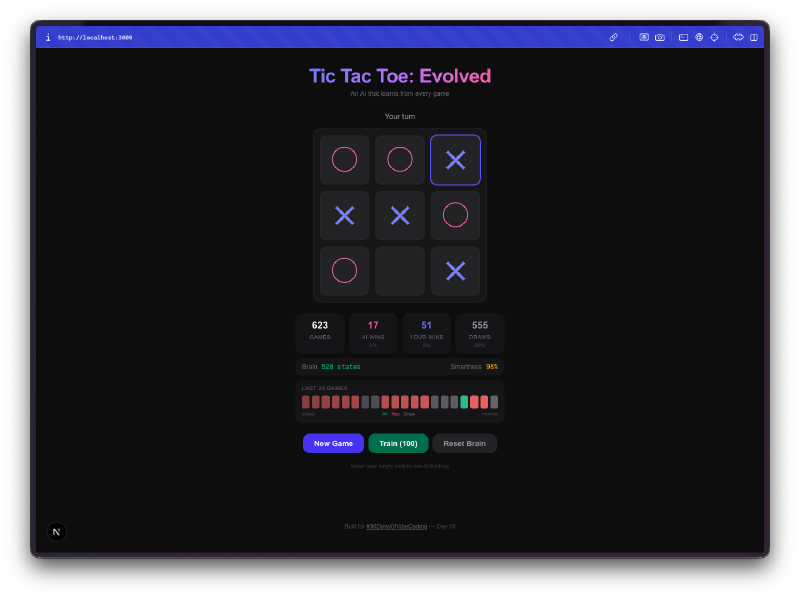
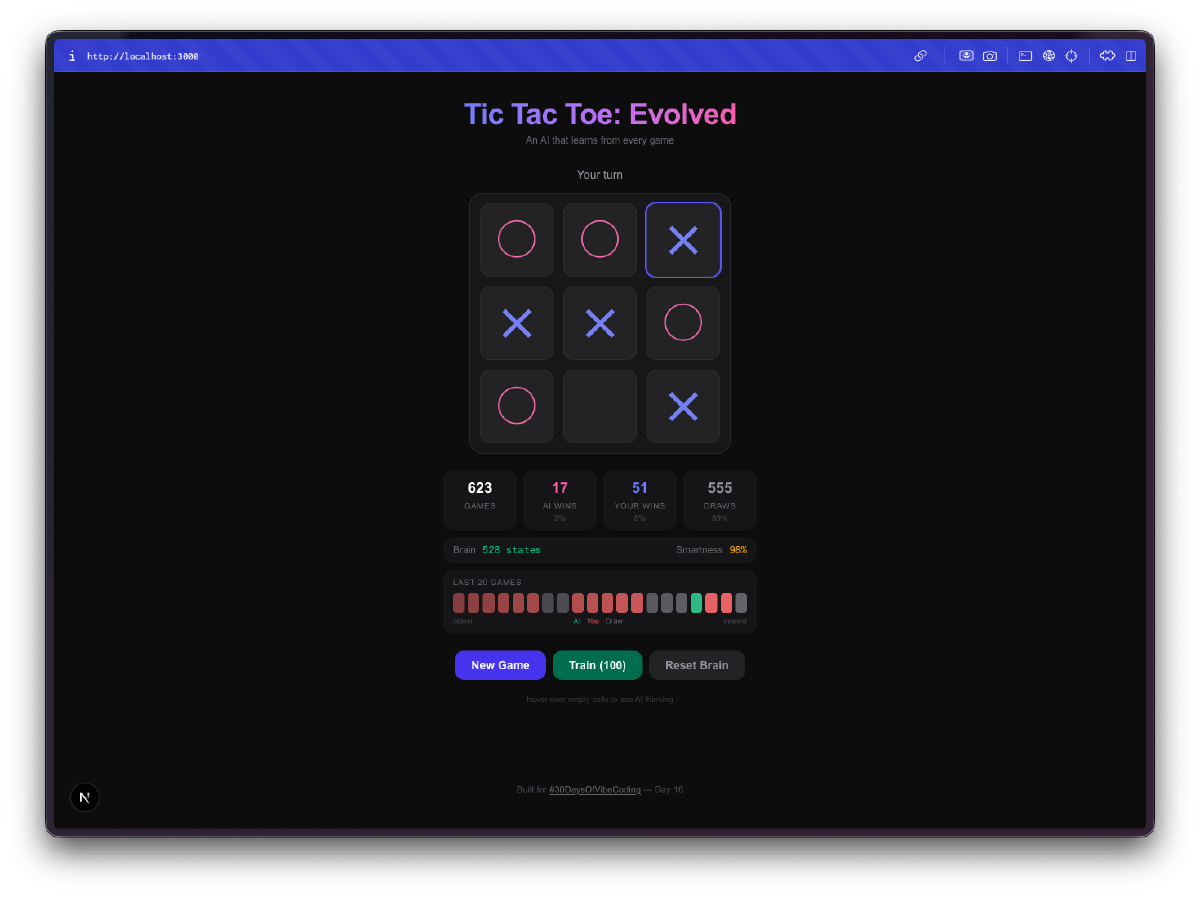
L’IA commence lamentablement. Vos premieres parties, elle joue presque au hasard. Elle choisit des cases sans strategie, tombe dans les memes pieges, perd de maniere evidente. C’est tout l’interet. Elle explore l’espace du jeu, essaie des coups qu’elle n’a jamais tentes, construit sa Q-table a partir de zero.
Puis elle arrete d’etre nulle. Quelque part entre 50 et 100 parties, vous remarquez qu’elle bloque vos coups gagnants. Apres quelques centaines de parties, elle fait match nul regulierement. Entrainez-la avec quelques milliers de parties contre elle-meme et bonne chance pour gagner. La progression de clueless a competente est vraiment fun a observer.
La visualisation du cerveau, c’est le meilleur. Vous pouvez survoler les cases et voir les Q-values que l’IA a apprises pour chaque position. Des valeurs positives elevees signifient que l’IA pense que ce coup mene a une victoire. Des valeurs negatives signifient qu’elle a appris a eviter cette case dans l’etat actuel. Vous regardez litteralement la comprehension du jeu par l’IA, et vous pouvez voir ces chiffres changer au fur et a mesure qu’elle joue.
L’entrainement en masse, c’est addictif. Il y a un mode entrainement ou vous pouvez lancer 100, 1 000 ou 10 000 parties contre elle-meme. L’IA joue contre elle-meme, apprenant des deux cotes. Vous pouvez voir la taille de la Q-table grandir en temps reel a mesure qu’elle decouvre de nouveaux etats du plateau. Apres 10 000 parties, le cerveau a vu des milliers de positions uniques et a un avis bien tranche sur chacune d’entre elles.
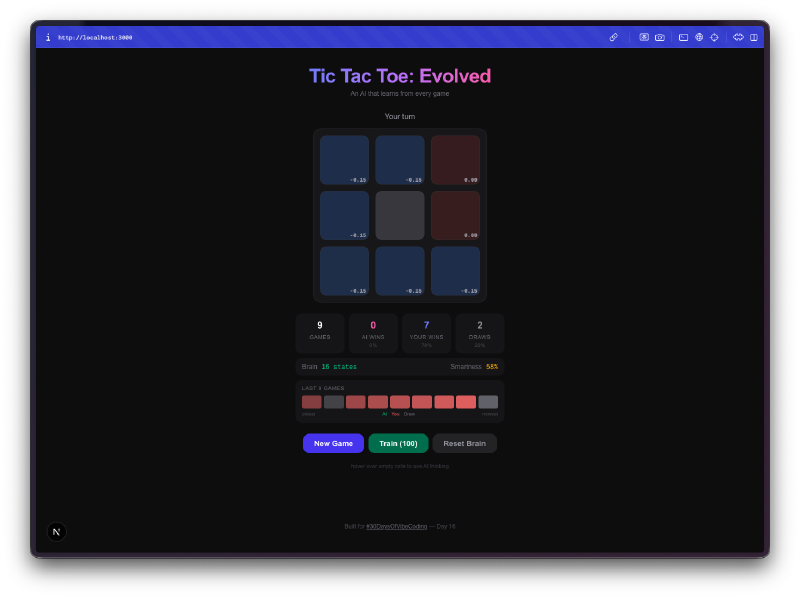
Tout persiste. Fermez l’onglet, revenez demain, et l’IA se souvient de tout ce qu’elle a appris. La Q-table, les stats de jeu, l’historique des series de victoires. Tout est sauvegarde dans le localStorage. Votre adversaire IA a une memoire permanente, ce qui veut dire que plus vous jouez contre elle au fil des jours et des semaines, meilleure elle devient.
Les modes de difficulte changent le taux d’exploration. Le mode facile garde l’epsilon (l’aleatoire) eleve pour que l’IA fasse plus d’erreurs. Le mode difficile baisse l’epsilon pour qu’elle choisisse presque toujours le coup qu’elle pense etre le meilleur. Ca vous permet de controler a quel point l’IA s’appuie sur ce qu’elle a appris versus essayer de nouvelles choses.
Les petits details comptent. Les lignes gagnantes sont mises en surbrillance. Des effets sonores accompagnent les coups, victoires, defaites et matchs nuls. Il y a un historique des parties recentes montrant vos 20 derniers resultats sous forme de suivi visuel de series. Le tout donne l’impression d’un vrai jeu, pas juste une demo technique.
Les Chiffres#
- 4 taches Watchfire du scaffolding aux finitions
- La Q-table grandit jusqu’a des milliers d’entrees apres l’entrainement en masse
- 3 modes de difficulte controlant le compromis exploration/exploitation
- Persistence complete en localStorage pour le cerveau de l’IA et toutes les stats
- 0 strategie codee en dur dans l’IA. Tout ce qu’elle sait, elle l’a appris
Essayez-le#
Jouer a Tic-Tac-Toe : Evolution
Jouez quelques parties et regardez l’IA s’ameliorer. Ou appuyez sur le bouton d’entrainement et laissez-la apprendre toute seule.
Verdict du Jour 16#
Le tic-tac-toe est un jeu resolu. N’importe quel joueur parfait peut forcer un match nul a chaque fois. C’est exactement ce qui en fait un terrain de jeu ideal pour l’apprentissage par renforcement. Le jeu est assez simple pour que l’IA puisse explorer l’ensemble de l’espace d’etats en un nombre raisonnable de parties, et on peut vraiment la voir converger vers un jeu optimal.
Ce que j’aime dans ce projet, c’est qu’il rend le machine learning tangible. Vous ne lisez pas sur le Q-learning dans un manuel ou ne regardez pas des courbes de perte dans un notebook Jupyter. Vous jouez contre une IA qui devient visiblement plus intelligente. Vous pouvez voir ses Q-values, regarder son cerveau grandir, et sentir la difference entre jouer contre elle a la partie 10 versus la partie 10 000.
Le fait que tout tourne dans le navigateur sans backend, sans Python, sans TensorFlow, juste du TypeScript et du localStorage, rend le tout accessible. Le Q-learning est l’un des algorithmes d’apprentissage par renforcement les plus simples, mais le voir fonctionner en temps reel sur un jeu que vous comprenez deja fait que le concept devient clair d’une maniere que la theorie seule ne permet jamais.
C’est le jour 16 de 30 Days of Vibe Coding. Suivez l’aventure alors que je livre 30 projets en 30 jours en utilisant le coding assiste par IA.