Partiamo dall’inizio e procediamo passo dopo passo.
Fondamenti#
AI vs ML vs Deep Learning#
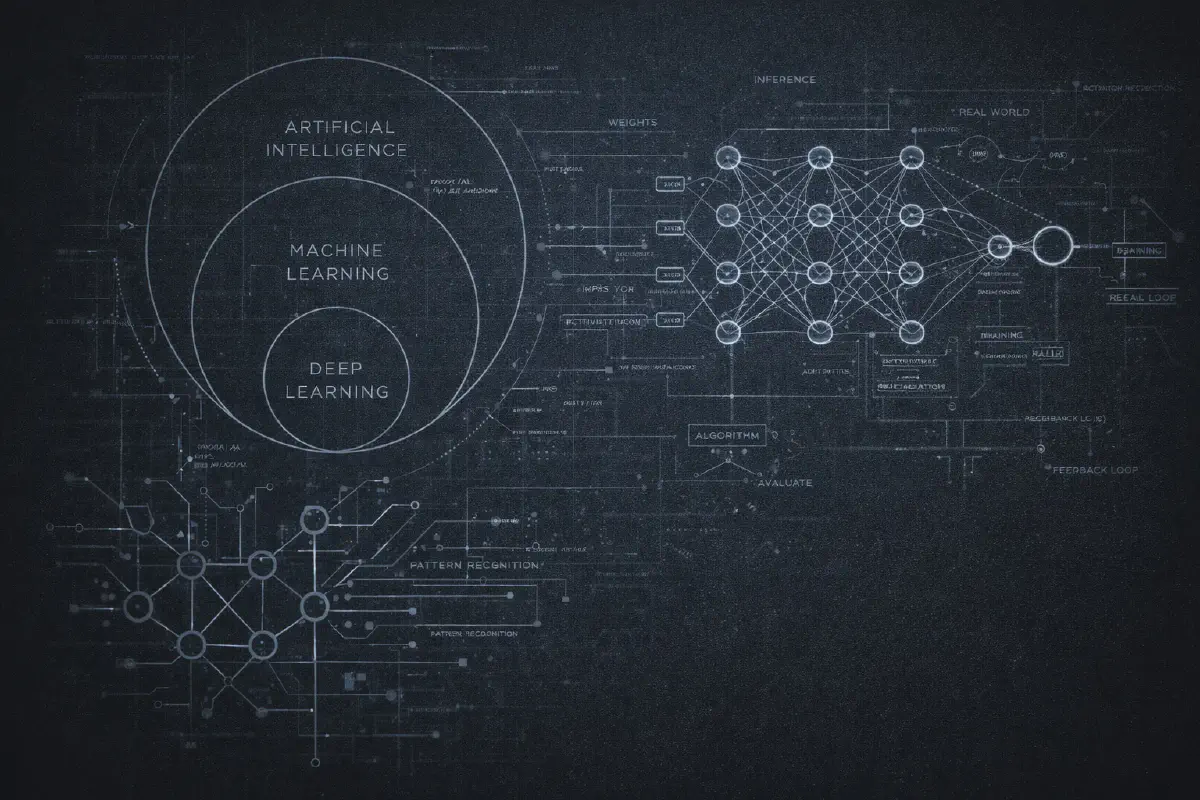
Probabilmente hai visto il diagramma: tre cerchi concentrici con AI all’esterno, Machine Learning al centro e Deep Learning al nucleo. E’ diventato un cliche’, ma e’ genuinamente utile per capire come questi termini si relazionano.
Artificial Intelligence e’ il termine piu’ ampio. Significa semplicemente “far fare ai computer cose che richiederebbero intelligenza se le facessero gli umani.” Tutto qui. Un programma di scacchi degli anni ‘70? AI. Il tuo filtro antispam? AI. Una semplice regola if-else che decide se mostrarti un popup? Tecnicamente, AI. Il termine e’ cosi’ ampio che e’ quasi privo di significato da solo.
Machine Learning e’ un sottoinsieme dell’AI dove invece di programmare regole esplicite, dai al computer degli esempi e lo lasci capire i pattern. Invece di scrivere “se l’email contiene ‘principe nigeriano’, segna come spam,” mostri 10.000 email etichettate “spam” o “non spam” e lasci che l’algoritmo impari cosa rende lo spam… spam.
Deep Learning e’ un sottoinsieme del machine learning che usa reti neurali con molti strati (da qui “deep”, profondo). E’ qui che le cose sono diventate interessanti negli anni 2010. Il deep learning ha permesso progressi nel riconoscimento di immagini, nel riconoscimento vocale, e infine nei modelli linguistici di cui siamo tutti ossessionati ora.
Reti Neurali#
Ecco un’analogia imperfetta ma utile: una rete neurale e’ come un foglio di calcolo molto complicato con milioni di numeri regolabili.
I dati entrano da un lato. Vengono moltiplicati per questi numeri, sommati, passati attraverso alcune funzioni matematiche, e alla fine producono un output dall’altro lato. La parte dell’“apprendimento” consiste nel regolare tutti quei numeri finche’ gli output corrispondono a quello che vuoi.
Se vuoi andare piu’ in profondita’: la rete e’ organizzata in strati. Ogni strato contiene “neuroni” (in realta’ solo funzioni matematiche). Ogni neurone prende input, li moltiplica per pesi, li somma e passa il risultato attraverso una funzione di attivazione. La magia accade perche’ quando impili molti strati insieme, la rete puo’ imparare pattern incredibilmente complessi - cose che nessun umano potrebbe programmare a mano.
Il termine “neurale” viene da un’analogia approssimativa con i neuroni biologici nel cervello. Non prenderla troppo alla lettera. Questi sistemi non funzionano affatto come i cervelli reali. La metafora era utile per i ricercatori originali negli anni ‘40 ma e’ diventata in qualche modo fuorviante.
Training vs Inference#
Ogni sistema AI ha due fasi distinte, e confonderle causa infinite incomprensioni.
Training e’ la parte costosa. E’ quando mostri al modello milioni (o miliardi) di esempi e regoli tutti quei numeri interni finche’ il modello diventa bravo nel suo compito. Addestrare GPT-4 avrebbe costato oltre 100 milioni di dollari solo in calcolo computazionale. Il training avviene una volta (o periodicamente quando vuoi aggiornare il modello).
Inference e’ la parte economica - relativamente parlando. E’ quando effettivamente usi il modello addestrato. Gli dai un input, produce un output. Ogni volta che chatti con ChatGPT, stai facendo inference. I numeri del modello sono congelati; sta solo eseguendo calcoli.
Pensala come istruzione vs. lavoro. Il training sono anni di scuola e studio. L’inference e’ presentarsi al lavoro e usare quello che hai imparato. L’investimento avviene in anticipo; il ritorno viene durante l’uso.
Capire gli LLM#
Cosa Rende Speciali gli LLM#
I Large Language Model sono un tipo specifico di modello di deep learning addestrato per predire testo. Questa e’ l’intuizione centrale: al loro cuore, gli LLM stanno solo cercando di predire la prossima parola (o token) in una sequenza.
“Il gatto si sedette sul ___” -> “divano” (probabilmente)
Ma ecco cosa e’ incredibile: quando addestri questo semplice obiettivo su trilioni di parole da internet, libri, codice e articoli scientifici, succede qualcosa di notevole. Il modello non impara solo la grammatica. Impara fatti, pattern di ragionamento, convenzioni di programmazione, e persino qualcosa che assomiglia al buon senso.
Questo si chiama comportamento emergente - capacita’ che non sono state esplicitamente addestrate ma sono emerse dalla scala dell’addestramento. Nessuno ha programmato GPT-4 per scrivere poesie o risolvere problemi matematici. Quelle capacita’ sono emerse dall’obiettivo di predire il prossimo token davvero, davvero bene.
Transformer e Attention#
L’architettura che ha reso possibili gli LLM moderni si chiama Transformer, introdotta in un paper del 2017 intitolato in modo celebre “Attention Is All You Need.”
L’innovazione chiave e’ il meccanismo di attention. I modelli precedenti processavano il testo sequenzialmente - parola per parola, da sinistra a destra. L’attention permette al modello di guardare tutte le parole simultaneamente e imparare quali parole sono rilevanti l’una per l’altra.
Esempio semplice: “L’animale non ha attraversato la strada perche’ era troppo stanco.”
A cosa si riferisce “era”? All’animale. Ma come fa il modello a saperlo? Il meccanismo di attention impara che “era” dovrebbe prestare forte attenzione ad “animale” e debole attenzione a “strada.” Questa capacita’ di catturare dipendenze a lungo raggio e’ cio’ che rende i Transformer cosi’ potenti per il linguaggio.
Token e Context Window#
Gli LLM in realta’ non vedono parole - vedono token. Un token e’ un pezzo di testo, tipicamente una parola o parte di una parola. “Comprensione” potrebbe essere un token, mentre “com” + “prension” + “e” potrebbero essere tre token a seconda del tokenizer del modello.
Perche’ e’ importante? Perche’ i modelli hanno context window limitate - il numero massimo di token che possono processare in una volta. I primi GPT-3 avevano un contesto di 4K token. GPT-4 Turbo e’ arrivato a 128K. Claude puo’ gestire 200K. Alcuni modelli piu’ recenti dichiarano milioni.
Pensa alla context window come alla memoria di lavoro del modello. Tutto quello che vuoi che il modello consideri - la tua domanda, qualsiasi documento che stai condividendo, la cronologia della conversazione - deve entrare in questa finestra.
| Modello | Context Window | Equivalente Approssimativo |
|---|---|---|
| GPT-3 (2020) | 4K token | ~3.000 parole |
| GPT-4 Turbo | 128K token | ~100.000 parole |
| Claude 3.5 | 200K token | ~150.000 parole |
| Gemini 1.5 Pro | 1M+ token | ~750.000 parole |
Prompt Engineering#
Un prompt e’ semplicemente il testo che invii a un LLM. La tua domanda, le tue istruzioni, qualsiasi contesto fornisci - tutto questo fa parte del prompt.
Prompt engineering e’ l’arte (e sempre piu’, scienza) di scrivere prompt che ottengono risultati migliori. Sembra sciocco - “ingegnerizzare” le tue domande? - ma conta davvero.
Alcune tecniche che funzionano:
- Sii specifico. “Scrivi una poesia” vs. “Scrivi un sonetto di 14 versi sul cambiamento climatico nello stile di Shakespeare” - il secondo ottiene risultati drammaticamente migliori.
- Mostra esempi. Dai al modello alcuni esempi di quello che vuoi prima di chiedere l’output effettivo. Questo si chiama “few-shot prompting.”
- Pensa passo dopo passo. Aggiungere “Ragioniamo passo dopo passo” prima di un problema complesso migliora l’accuratezza. Questo si chiama “chain-of-thought” prompting.
- Assegna un ruolo. “Sei un esperto commercialista” focalizza le risposte del modello.
Temperature & Parametri#
Quando usi un’API LLM, puoi regolare diversi parametri che influenzano l’output. Il piu’ importante e’ la temperature.
La temperature controlla la casualita’. A temperature 0, il modello sceglie sempre il token successivo piu’ probabile - deterministico, prevedibile, a volte noioso. A temperature 1 o superiore, e’ piu’ disposto a scegliere token meno probabili - piu’ creativo, piu’ vario, a volte insensato.
- Temperature 0: “La capitale della Francia e’ Parigi.”
- Temperature 1: “La capitale della Francia e’ Parigi, quella magnifica citta’ delle luci dove rivoluzione e romanticismo danzano attraverso strade acciottolate…”
Altri parametri comuni:
- Top-p (nucleus sampling): Un altro modo per controllare la casualita’ limitando quali token vengono considerati.
- Max tokens: Quanto puo’ essere lunga la risposta.
- Stop sequences: Dice al modello quando smettere di generare.
- Frequency/presence penalty: Riduce la ripetizione.
Allucinazioni#
Gli LLM inventano cose. Affermano falsita’ con completa sicurezza. Citano paper che non esistono. Inventano statistiche. Questo si chiama allucinazione, e non e’ un bug che verra’ risolto - e’ una conseguenza di come funzionano questi modelli.
Ricorda: gli LLM sono addestrati per predire testo plausibile, non testo vero. Se chiedi di un argomento dove il modello ha dati di training limitati, generera’ qualcosa che sembra giusto. Il modello non ha un verificatore di fatti interno, nessuna connessione alla verita’ di base, nessun modo per dire “non lo so.”
Perche’ succede?
- Obiettivo di training: Predire il prossimo token, non verificare la verita’.
- Distribuzione di probabilita’: Il modello campiona dalle possibilita’. Anche se la risposta vera e’ piu’ probabile, il campionamento potrebbe scegliere qualcos’altro.
- Nessuna consapevolezza del limite di conoscenza: Il modello non sa in modo affidabile i confini della sua conoscenza.
Strategie per ridurre le allucinazioni:
- Usa RAG per ancorare le risposte a documenti reali
- Chiedi al modello di citare fonti e verificale
- Abbassa la temperature per compiti fattuali
- Usa output strutturati che vincolano la risposta
- Implementa livelli di verifica dei fatti
Il Panorama dei Modelli#
Open vs Closed Models#
Closed source: Puoi usare il modello via API ma non puoi vedere i pesi, modificare l’architettura, o farlo girare tu stesso. GPT-4 di OpenAI, Claude di Anthropic, Gemini di Google.
Open source/open weights: I pesi sono pubblicamente disponibili. Puoi scaricarli, farli girare localmente, fare fine-tuning, modificarli. Llama di Meta, Mistral, Qwen di Alibaba, DeepSeek, e molti altri.
La distinzione e’ importante ma sfumata:
- “Open weights” significa che puoi scaricare e far girare il modello
- “Open source” tradizionalmente significa che anche il codice di training e i dati sono disponibili (raro per modelli grandi)
- Le licenze variano - alcuni modelli open hanno restrizioni commerciali
Perche’ Meta rilascia Llama gratis? Ragioni strategiche: commoditizzare il complemento, costruire ecosistema, attrarre talenti, stabilire standard. La visione cinica: non possono competere con OpenAI sui ricavi delle API, quindi competono rendendo gratuito il livello del modello e profittando altrove.
Modelli Multimodali#
I primi LLM capivano solo testo. I modelli multimodali comprendono piu’ tipi di dati - testo, immagini, audio, video.
GPT-4V puo’ guardare una foto e descriverla. Claude puo’ analizzare grafici e diagrammi. Gemini puo’ guardare video. Questa non e’ solo una novita’ - apre casi d’uso completamente nuovi:
- Fai uno screenshot di un bug e chiedi aiuto per il debug
- Carica un diagramma disegnato a mano e ottieni codice
- Analizza immagini mediche
- Processa video per moderazione dei contenuti
- Interfacce vocali senza speech-to-text separato
Le architetture variano. Alcuni modelli sono addestrati nativamente multimodali. Altri collegano modelli separati di visione e linguaggio. La distinzione conta per le prestazioni ma non per la maggior parte degli utenti.
Modelli di Ragionamento#
Gli LLM standard generano risposte token per token senza “pensiero” esplicito. I modelli di ragionamento adottano un approccio diverso - spendono calcolo extra pensando ai problemi prima di rispondere.
I modelli o1 e o3 di OpenAI hanno aperto la strada a questo approccio. Invece di rispondere immediatamente, questi modelli generano catene di ragionamento interne (a volte nascoste agli utenti), considerano approcci multipli, e controllano il loro lavoro prima di produrre una risposta finale.
I risultati sono notevoli: i modelli di ragionamento superano drammaticamente gli LLM standard in matematica, programmazione, scienza e problemi di logica. o3 ha raggiunto punteggi su certi benchmark che si pensava fossero lontani anni.
Il compromesso: i modelli di ragionamento sono piu’ lenti e costosi. Una domanda semplice a cui GPT-4 risponde istantaneamente potrebbe richiedere a o1 diversi secondi (e 10 volte il costo) mentre “pensa.” Per compiti semplici, e’ uno spreco. Per problemi difficili, ne vale la pena.
Quando usare modelli di ragionamento:
- Problemi complessi di matematica o logica
- Sfide di programmazione multi-step
- Compiti che richiedono analisi attenta
- Qualsiasi cosa dove l’accuratezza conta piu’ della velocita’
Quando gli LLM standard sono migliori:
- Q&A semplice
- Scrittura creativa
- Applicazioni real-time
- Casi d’uso sensibili ai costi
Prodotti AI per Consumatori#
Prima di addentrarci nei dettagli tecnici, mappiamo i prodotti che probabilmente hai gia’ usato:
ChatGPT (OpenAI) - Il prodotto che ha iniziato l’ondata mainstream dell’AI. Accesso a GPT-4, o1, DALL-E per immagini, e vari plugin. Il benchmark a cui tutti gli altri vengono comparati.
Claude (Anthropic) - Conosciuto per scrittura forte, context window lunghe, e ragionamento sfumato. Claude.ai e’ l’interfaccia consumer; l’API alimenta molte applicazioni.
Gemini (Google) - Profondamente integrato con l’ecosistema Google. Accesso via gemini.google.com e sempre piu’ incorporato in Search, Docs, Gmail, e Android.
Copilot (Microsoft) - Il layer AI di Microsoft attraverso i loro prodotti. Diverso da GitHub Copilot (programmazione) - questo e’ l’assistente consumer in Windows, Edge, e Microsoft 365.
Perplexity - Motore di ricerca AI-native. Risponde alle domande con citazioni e fonti. Uno sguardo a cosa potrebbe diventare la ricerca.
Altri da conoscere: Grok (xAI, integrato in X/Twitter), Pi (Inflection), Le Chat (Mistral), DeepSeek Chat, e molte alternative regionali/specializzate.
Eseguire Modelli Localmente#
Perche’ Eseguire Localmente?#
Modelli cloud girano sui server di qualcun altro. Invii richieste via internet e paghi per uso. OpenAI, Anthropic, Google - questo e’ il loro business.
Modelli locali girano sul tuo hardware. Il tuo laptop, i tuoi server, il tuo data center. I dati non escono mai dal tuo controllo.
Perche’ eseguire localmente?
- Privacy: I dati sensibili restano on-premise
- Costo: Nessuna fee API (ma l’hardware non e’ gratis)
- Latenza: Nessun round trip di rete
- Disponibilita’: Funziona offline, nessun rate limit
- Controllo: Nessun termine di servizio, nessun filtro sui contenuti che non hai scelto tu
Il divario tra locale e cloud si e’ ridotto drasticamente. Per molte applicazioni pratiche, i modelli locali sono abbastanza buoni - specialmente per programmazione, scrittura e compiti di analisi.
Il compromesso: le capacita’ di frontiera richiedono ancora il cloud. Se hai bisogno delle prestazioni assolute migliori su compiti di ragionamento difficili, GPT-4, Claude, o Gemini sono solo cloud. Ma quel divario si riduce ad ogni release.
Ollama#
Ollama e’ diventato lo standard de facto per eseguire modelli localmente. Rende quello che era un processo complesso banalmente facile.
# Installa ed esegui un modello in due comandi
ollama pull llama3.2
ollama run llama3.2Tutto qui. Stai chattando con un LLM capace che gira interamente sulla tua macchina.
Ollama gestisce la complessita’: scaricare modelli, gestire la memoria, ottimizzare per il tuo hardware, e fornire sia una CLI che un’API locale. Supporta decine di modelli - Llama, Mistral, Qwen, Phi, CodeLlama, e molti altri.
Caratteristiche chiave:
- Interfaccia CLI semplice
- API compatibile con OpenAI (facile da scambiare nel codice esistente)
- Libreria modelli con download a un comando
- Funziona su Mac, Linux, e Windows
- Accelerazione GPU quando disponibile
Per gli sviluppatori, l’API locale di Ollama significa che puoi sviluppare contro modelli locali e passare ad API cloud per la produzione - o viceversa - con modifiche minime al codice.
Considerazioni Hardware#
Eseguire modelli localmente richiede hardware. Ecco cosa conta:
GPU vs CPU: Le GPU accelerano drammaticamente l’inference. Un modello che impiega 30 secondi per risposta su CPU potrebbe impiegare 2 secondi su GPU. I Mac con Apple Silicon sfumano questa linea - la loro memoria unificata e Neural Engine li rendono sorprendentemente capaci per inference locale.
Memoria (VRAM/RAM): Questo e’ di solito il fattore limitante. I modelli devono stare in memoria. Un modello da 7B parametri ha bisogno di circa 4-8GB. Un modello da 70B ha bisogno di 35-70GB. La quantizzazione (discussa sotto) riduce questi requisiti.
Quantizzazione: Ridurre la precisione dei pesi del modello da 32-bit a 16-bit, 8-bit, o persino 4-bit. Questo riduce i requisiti di memoria e accelera l’inference con perdita di qualita’ minima. La maggior parte dei modelli locali sono distribuiti in formati quantizzati (GGUF, GPTQ, AWQ).
Guida pratica:
- Mac con 16GB+ RAM: Puo’ eseguire modelli 7B-13B comodamente
- Mac con 32GB+ RAM: Puo’ eseguire modelli 30B+
- PC con RTX 3090/4090 (24GB VRAM): Puo’ eseguire la maggior parte dei modelli fino a 70B (quantizzati)
- Senza GPU: Funziona comunque, solo piu’ lento. Va bene per sviluppo e sperimentazione.
Personalizzazione e Conoscenza#
Fine-Tuning vs RAG#
Hai un LLM di base. Vuoi renderlo migliore per il tuo caso d’uso specifico. Due approcci principali:
Fine-Tuning#
Prendi un modello esistente e continua ad addestrarlo sui tuoi dati. I pesi del modello cambiano effettivamente. Dopo il fine-tuning, il modello “conosce” le tue informazioni nativamente.
Pro: Inference veloce, integrazione profonda della conoscenza, puo’ imparare nuovi stili o comportamenti. Contro: Costoso, richiede competenze ML, la conoscenza puo’ diventare obsoleta, rischio di catastrophic forgetting (il modello peggiora in altri compiti).
RAG (Retrieval-Augmented Generation)#
Mantieni il modello com’e’. Quando arriva una domanda, prima cerca nel tuo knowledge base documenti rilevanti, poi includi quei documenti nel prompt insieme alla domanda.
Pro: Piu’ economico, la conoscenza resta aggiornata, nessun training richiesto, facile da verificare (puoi vedere cosa e’ stato recuperato). Contro: Piu’ lento (processo in due fasi), limitato dalla context window, la qualita’ del retrieval conta molto.
Embedding & Vector DB#
Questa e’ la tecnologia che fa funzionare RAG - ed e’ genuinamente ingegnosa.
Un embedding e’ un modo per rappresentare testo (o immagini, o qualsiasi cosa) come una lista di numeri - un vettore. La magia: cose simili hanno vettori simili. “Cane” e “cucciolo” hanno vettori vicini tra loro. “Cane” e “democrazia” sono lontani.
Crei embedding usando modelli di embedding (diversi dagli LLM, anche se alcuni LLM hanno capacita’ di embedding). OpenAI, Cohere, Voyage, e molti altri offrono API di embedding. Opzioni open source come BGE e E5 funzionano benissimo.
Un database vettoriale e’ un database ottimizzato per memorizzare e cercare questi vettori. Quando chiedi “Qual e’ la nostra politica di rimborso?”, il sistema:
- Converte la tua domanda in un vettore
- Cerca nel database vettoriale vettori simili
- Restituisce i documenti che quei vettori rappresentano
- Alimenta quei documenti nell’LLM con la tua domanda
Database vettoriali popolari includono Pinecone, Weaviate, Chroma, Qdrant, e Milvus. Postgres con pgvector funziona sorprendentemente bene per molti casi d’uso.
Valutazione#
Benchmark#
Come fai a sapere se un modello e’ “migliore” di un altro? I benchmark cercano di rispondere a questo testando i modelli su compiti standardizzati.
Benchmark comuni:
- MMLU (Massive Multitask Language Understanding): Domande a scelta multipla su 57 materie. Testa la conoscenza generale.
- HumanEval: Problemi di programmazione. Testa la capacita’ di coding.
- GSM8K: Problemi di matematica delle elementari. Testa il ragionamento matematico.
- HellaSwag: Ragionamento di buon senso su situazioni quotidiane.
- TruthfulQA: Testa se i modelli danno risposte veritiere vs. sciocchezze che suonano convincenti.
Il problema con i benchmark: Sono manipolabili. I modelli possono essere addestrati specificamente per fare bene su benchmark popolari senza effettivamente migliorare in compiti reali. Un modello che fa 90% su MMLU potrebbe comunque fallire nel tuo caso d’uso specifico.
Eval#
Eval (valutazioni) sono test che crei per il tuo caso d’uso specifico. A differenza dei benchmark, le eval misurano quello che conta effettivamente per la tua applicazione.
Stai costruendo un bot per il servizio clienti? Le tue eval potrebbero testare:
- Risponde correttamente alle domande dalle tue FAQ?
- Scala appropriatamente agli umani quando necessario?
- Resta in linea con il brand e segue le tue linee guida di tono?
- Si rifiuta di fare promesse che l’azienda non puo’ mantenere?
Perche’ le eval contano:
- Rilevamento regressioni: Quando cambi prompt o cambi modelli, le eval catturano problemi prima degli utenti.
- Confronto: Confronta oggettivamente diversi modelli, prompt, o approcci per il tuo caso d’uso.
- Iterazione: Non puoi migliorare quello che non puoi misurare. Le eval rendono il miglioramento sistematico.
Costruire buone eval:
- Parti da query utente reali e risposte attese
- Includi edge case e esempi avversari
- Testa sia quello che il modello dovrebbe fare CHE quello che non dovrebbe
- Automatizza cosi’ puoi eseguire le eval ad ogni modifica
LLM come Giudice#
Ecco una tecnica ingegnosa: usa un LLM per valutare gli output di un altro LLM.
Invece di revisionare manualmente centinaia di risposte, puoi istruire un modello ad agire come giudice:
Stai valutando la qualita' della risposta di un assistente AI.
Domanda utente: {question}
Risposta assistente: {response}
Valuta la risposta su:
1. Accuratezza (1-5): Le informazioni sono corrette?
2. Utilita' (1-5): Aiuta effettivamente l'utente?
3. Chiarezza (1-5): E' facile da capire?
Spiega il tuo ragionamento, poi fornisci i punteggi.Perche’ funziona:
- Scala a migliaia di valutazioni
- Piu’ consistente dei revisori umani (meno affaticamento)
- Puo’ valutare qualita’ sfumate difficili da testare programmaticamente
- Piu’ economico e veloce della valutazione umana
Limitazioni:
- Il modello giudice ha i propri bias e limitazioni
- Puo’ mancare errori che farebbe lui stesso
- Fatica con accuratezza domain-specific senza grounding
- Non e’ un sostituto della valutazione umana completamente - piu’ un complemento
Agenti e Automazione#
Cosa Sono gli Agenti?#
Il termine “agente” viene usato molto. Ecco una definizione operativa: un agente e’ un LLM che puo’ compiere azioni nel mondo, non solo generare testo.
Un chatbot risponde alle tue domande. Un agente potrebbe rispondere alle tue domande e prenotare un ristorante, inviare un’email, interrogare un database, o scrivere ed eseguire codice per risolvere un problema.
Cosa rende qualcosa un agente vs. solo un LLM?
- Obiettivi: Gli agenti lavorano verso obiettivi, non solo rispondono a prompt.
- Azioni: Gli agenti possono fare cose, non solo dire cose.
- Autonomia: Gli agenti prendono decisioni su come raggiungere obiettivi.
- Cicli: Gli agenti spesso girano in cicli - osserva, pensa, agisci, ripeti.
Il pattern di agente piu’ semplice: dai a un LLM accesso a strumenti e lascialo decidere quali strumenti usare. “Trova voli da Londra a Tokyo la prossima settimana, controlla il mio calendario, e prenota l’opzione piu’ economica che funziona con il mio programma.” L’agente scompone questo, chiama API di voli, chiama API del calendario, ed esegue la prenotazione.
Agenti vs Workflow#
Una distinzione importante che spesso viene sfumata:
Workflow sono deterministici. Tu definisci i passi: prima fai A, poi fai B, poi se X fai C altrimenti fai D. L’LLM potrebbe alimentare i singoli passi, ma l’orchestrazione e’ codificata.
1. Estrai entita' dall'email (LLM)
2. Cerca cliente nel database (codice)
3. Genera bozza di risposta (LLM)
4. Invia per revisione umana (codice)Agenti sono autonomi. Dai loro un obiettivo e strumenti, e loro capiscono i passi. L’LLM decide cosa fare dopo basandosi sullo stato corrente.
Obiettivo: "Risolvi questo reclamo cliente"
Strumenti: [email, database, sistema_rimborsi, escalation]
-> L'agente decide cosa fare, in quale ordineQuando usare workflow:
- Processi prevedibili e ben compresi
- Quando hai bisogno di affidabilita’ e verificabilita’
- Ambienti regolamentati
- Compiti ad alto volume e bassa complessita'
Quando usare agenti:
- Compiti nuovi o variabili
- Quando i passi non sono noti in anticipo
- Ragionamento complesso richiesto
- Quando la flessibilita’ conta piu’ della prevedibilita'
L’equazione dei costi: I workflow sono significativamente piu’ economici. Stai pagando per un numero fisso di chiamate LLM per esecuzione - prevedibile, ottimizzabile, verificabile. Gli agenti sono costosi perche’ pensano. Ogni punto di decisione - “quale strumento dovrei usare?”, “ha funzionato?”, “cosa viene dopo?” - e’ una chiamata LLM. Un workflow che fa 3 chiamate LLM potrebbe diventare un agente che fa 15-30 chiamate per risolvere lo stesso problema, perche’ l’agente sta ragionando su come risolverlo, non solo eseguendo passi predefiniti. Per compiti ben compresi su scala, i workflow vincono sui costi. Per problemi complessi e variabili dove non puoi predefinire i passi, gli agenti valgono il premio.
Tool Use & Function Calling#
Per compiere azioni, gli agenti hanno bisogno di strumenti - funzioni che possono chiamare. Questa capacita’ e’ di solito chiamata function calling o tool use.
Ecco come funziona:
- Definisci strumenti con nomi, descrizioni e parametri (di solito come JSON schema)
- Includi queste definizioni nel tuo prompt/chiamata API
- Il modello puo’ scegliere di “chiamare” uno strumento invece di generare testo
- Il tuo codice esegue la funzione e restituisce i risultati al modello
- Il modello usa quei risultati per continuare
Esempio di definizione strumento:
{
"name": "get_weather",
"description": "Get current weather for a city",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "City name"},
"units": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["city"]
}
}Quando chiedi “Com’e’ il tempo a Tokyo?”, il modello non allucina - chiama get_weather(city="Tokyo"), ottiene dati reali, e risponde con fatti.
Ogni grande provider di modelli ora supporta function calling: OpenAI, Anthropic, Google, e altri. La sintassi varia leggermente ma il concetto e’ lo stesso.
Protocollo MCP#
Model Context Protocol (MCP) e’ uno standard aperto per connettere modelli AI a strumenti e fonti dati. Pensalo come USB-C per l’AI - un connettore universale che significa che non hai bisogno di un cavo diverso per ogni dispositivo.
Prima di MCP, ogni integrazione era custom. Vuoi che la tua AI acceda a GitHub? Scrivi un’integrazione GitHub. Salesforce? Un’altra integrazione. Il tuo database interno? Ancora un’altra. Questo non scala.
MCP definisce un modo standard per client AI (come Claude, ChatGPT, o il tuo agente custom) per scoprire e usare strumenti da server MCP. Un server MCP potrebbe esporre:
- Strumenti: Funzioni che l’AI puo’ chiamare
- Risorse: Dati che l’AI puo’ leggere
- Prompt: Template per compiti comuni
Le implicazioni sono significative:
- Costruisci un server MCP una volta, ogni AI compatibile puo’ usarlo
- Gli strumenti diventano portabili e riutilizzabili
- Sicurezza e permessi possono essere standardizzati
- L’ecosistema si moltiplica - piu’ server significa agenti piu’ capaci
Per approfondire MCP, ho scritto un articolo piu’ dettagliato: MCP Servers: The USB-C Moment for AI Agents.
Pattern Agentici#
Man mano che gli agenti sono maturati, sono emersi pattern comuni:
ReAct (Reason + Act): L’agente alterna tra ragionamento (“Devo trovare lo storico ordini dell’utente”) e azione (chiamare l’API ordini). Questo passo di ragionamento esplicito migliora l’affidabilita'.
Planning: Prima di agire, l’agente crea un piano: “Per risolvere questo, dovro’ 1) cercare l’ordine, 2) controllare l’inventario, 3) processare il rimborso, 4) inviare conferma.” I piani possono essere validati prima dell’esecuzione.
Reflection: Dopo aver completato un compito (o fallito), l’agente rivede cosa e’ successo: “Il rimborso e’ fallito perche’ l’ordine era troppo vecchio. Avrei dovuto controllare prima la politica di rimborso.” Questo abilita apprendimento e auto-correzione.
Tool selection: Quando un agente ha molti strumenti, scegliere quello giusto diventa non banale. Le tecniche includono descrizioni degli strumenti, esempi few-shot, e organizzazione gerarchica degli strumenti.
Human-in-the-loop: Per azioni ad alto rischio, gli agenti possono fermarsi e richiedere approvazione umana prima di procedere. Buoni agenti sanno quando sono incerti.
Skill#
Le skill sono prompt specializzati e riutilizzabili che estendono le capacita’ di un agente. Pensale come “modalita’ esperte” che puoi collegare a un agente - una skill per la code review, una skill per scrivere documentazione, una skill per analizzare vulnerabilita’ di sicurezza.
A differenza degli strumenti (che sono funzioni che fanno cose), le skill sono istruzioni che modellano come l’agente pensa e risponde. Uno strumento chiama un’API. Una skill dice all’agente “quando ti chiedono di X, approccialo in questo modo, considera questi fattori, e formatta la tua risposta cosi’.”
Perche’ le skill sono importanti:
- Specializzazione senza fine-tuning: Ottieni comportamento esperto senza addestrare un nuovo modello.
- Componibilita’: Mescola e abbina skill per compiti diversi.
- Condivisibilita’: Una skill ben realizzata puo’ essere usata tra team, progetti, o persino condivisa pubblicamente.
- Efficienza del contesto: Invece di spiegare i tuoi requisiti ogni volta, codificali una volta in una skill.
Dove vivono le skill:
Le skill possono essere iniettate in diversi punti del contesto dell’agente:
- System prompt: L’approccio piu’ comune. Le skill diventano parte delle istruzioni base dell’agente, sempre attive.
- Prefisso del messaggio utente: Preposto dinamicamente alle richieste dell’utente. Utile per skill specifiche per il compito.
- Descrizioni degli strumenti: Le skill possono essere incorporate nelle definizioni degli strumenti, guidando come l’agente usa strumenti specifici.
- Prompt MCP: I server MCP possono esporre skill come “prompt” - template riutilizzabili che i client possono scoprire e invocare.
Come le skill influenzano il contesto:
Ogni skill consuma token dalla tua context window. Questo crea compromessi:
- Piu’ skill = agente piu’ capace, ma meno spazio per lo storico della conversazione
- Skill dettagliate = comportamento migliore, ma costo in token piu’ alto per richiesta
- Skill sempre attive vs. skill on-demand = affidabilita’ vs. efficienza
I framework di agenti intelligenti gestiscono questo caricando le skill dinamicamente - attivando skill rilevanti in base al compito e disattivando le altre.
Esempio di struttura di una skill:
## Skill Code Review
Quando revisioni codice, dovresti:
1. Controllare vulnerabilita' di sicurezza (injection, XSS, problemi di auth)
2. Identificare problemi di performance
3. Valutare leggibilita' e manutenibilita'
4. Suggerire miglioramenti specifici con esempi di codice
Formatta la tua review come:
- Sommario (1-2 frasi)
- Problemi critici (se presenti)
- Suggerimenti (lista puntata)
- Valutazione complessivaAgenti di Coding#
Perche’ Contano#
Gli agenti di coding rappresentano una delle applicazioni piu’ tangibili dell’AI - scrivono effettivamente codice, e il codice funziona davvero. Questo non e’ teorico; gli sviluppatori spediscono funzionalita’ piu’ velocemente grazie a questi strumenti.
L’impatto e’ immediato e misurabile: meno tempo sul boilerplate, debug piu’ veloce, esplorazione piu’ facile di codebase non familiari. Per molti sviluppatori, gli agenti di coding sono diventati essenziali quanto il loro IDE.
Il Panorama#
Claude Code - L’agente di coding basato su terminale di Anthropic. Vive nella tua CLI, capisce l’intero codebase, puo’ leggere file, scrivere codice, eseguire comandi, e iterare sul feedback. Progettato per sviluppatori che vivono nel terminale.
Cursor - Un IDE AI-native costruito da zero attorno all’assistenza AI. Non solo autocompletamento - puoi chattare con il tuo codebase, generare intere funzionalita’, e far fare all’AI modifiche ampie attraverso file. La cosa piu’ vicina al pair programming con un’AI.
GitHub Copilot - L’originale e il piu’ diffuso. Iniziato come autocompletamento, evoluto in chat, ora include Copilot Workspace per compiti piu’ grandi. Integrazione profonda con GitHub.
Windsurf - L’IDE AI di Codeium, si posiziona come alternativa a Cursor. Forte enfasi sulla velocita’ e comprensione di codebase grandi.
Cody (Sourcegraph) - Si concentra sulla comprensione del codebase. Particolarmente forte per codebase grandi e complessi dove il contesto e’ critico.
Continue - Assistente di coding open-source che funziona con qualsiasi IDE. Porta il tuo modello (locale o cloud). Buono per team che vogliono controllo sul loro setup AI.
OpenCode - Alternativa open-source a Claude Code. Basato su terminale, agnostico rispetto al modello, sviluppo guidato dalla community.
Aider - Un altro eccellente agente di coding terminale open-source. Conosciuto per la sua integrazione git e capacita’ di lavorare con file multipli in modo coerente.
Prossimi Passi#
Hai completato i fondamentali. E ora?
Costruire Cose#
- Inizia semplice. Usa un’API (OpenAI, Anthropic, etc.) e costruisci un chatbot base o sistema RAG. Non pensare troppo allo stack inizialmente.
- Prova modelli locali. Installa Ollama e fai girare Llama o Qwen sul tuo laptop. E’ sorprendentemente facile.
- Esplora gli agenti. Dai un’occhiata a framework come LangChain, LlamaIndex, o CrewAI per costruire sistemi di agenti.
- Impara MCP. La documentazione ufficiale e’ solida. Prova a far girare alcuni server MCP localmente.
- Costruisci eval presto. Qualunque cosa costruisci, crea eval dal primo giorno. Ti ringrazierai dopo.
Capire il Campo#
- Segui la ricerca. Paper ArXiv, alert Google Scholar su argomenti che ti interessano.
- Leggi l’hype criticamente. La maggior parte delle “scoperte” sono incrementali. Cerca risultati riproducibili e benchmark reali.
- Sperimenta tu stesso. L’intuizione su cosa funziona viene dall’esperienza pratica, non dalla lettura.
Risorse#
- Hugging Face - Modelli, dataset, e una community incredibile
- Papers With Code - Paper di ricerca con implementazioni
- Ollama - Esecuzione di modelli locali semplicissima
- LangChain / LlamaIndex - Framework popolari per costruire con LLM
- Model Context Protocol - La specifica MCP e gli SDK
- Chatbot Arena - Confronta modelli testa a testa con voto umano
L’AI nel 2026 e’ simultaneamente sopravvalutata e sottovalutata. La tecnologia e’ genuinamente trasformativa - ma e’ anche genuinamente limitata. Gli LLM inventano cose. Gli agenti sono fragili. I costi sono alti. Il progresso e’ veloce ma disomogeneo.
L’approccio migliore e’ pragmatico: capire i fondamentali, sperimentare con problemi reali, restare scettici sulle grandi affermazioni, e costruire cose. Le persone che prospereranno in questa era non sono quelle che possono recitare ogni acronimo - sono quelle che possono spedire prodotti che funzionano davvero.
Ora vai a costruire qualcosa.





