Giorno 16. E se l’avversario IA imparasse davvero dalle sconfitte contro di te?
Non un algoritmo minimax che gioca perfettamente fin dall’inizio. Non un giocatore casuale. Qualcosa che parte stupido, osserva cosa funziona, e gradualmente capisce come batterti. Questo e il Q-learning. Ed e quello che volevo integrare nel gioco piu semplice possibile.
Il Prompt#
“Costruisci un gioco di tic-tac-toe con un’IA Q-learning che impara da ogni partita, salva il suo cervello nel localStorage, e mostra statistiche in tempo reale”
Come e stato costruito#
Watchfire ha suddiviso il progetto in 4 task:
- Scaffolding del progetto Next.js con il tabellone di gioco base e il layout
- IA Q-learning con strategia epsilon-greedy e persistenza localStorage per la Q-table
- Dashboard delle statistiche, visualizzazione del cervello dell’IA, e una modalita di allenamento per partite in massa contro se stessa
- Modalita di difficolta, evidenziazione delle mosse vincenti, effetti sonori, e rifinitura finale
Il primo task mi ha dato un tic-tac-toe giocabile. Niente di speciale. Il secondo task e dove le cose si sono fatte interessanti, perche ora l’IA aggiornava davvero i valori stato-azione dopo ogni partita. Vinci una partita contro di lei, e si adatta. Battila allo stesso modo due volte, e inizia a bloccare quella mossa. La Q-table cresce con ogni partita.
I task 3 e 4 l’hanno trasformata da esperimento di apprendimento in qualcosa che puoi davvero guardare evolversi. La visualizzazione del cervello mostra i Q-values per ogni cella, la dashboard traccia i tassi di vittoria/sconfitta/pareggio nel tempo, e la modalita di allenamento ti permette di lanciare migliaia di partite contro se stessa per accelerare l’educazione dell’IA.
Cosa ho ottenuto#
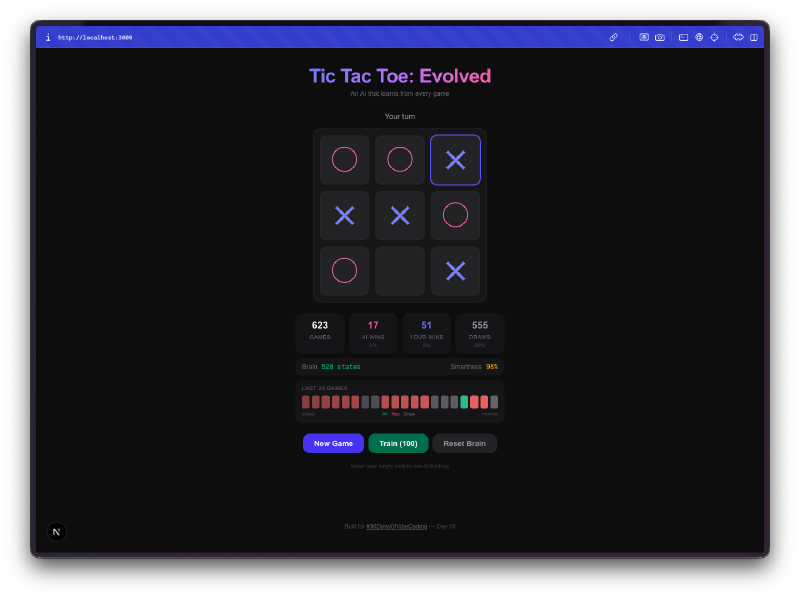
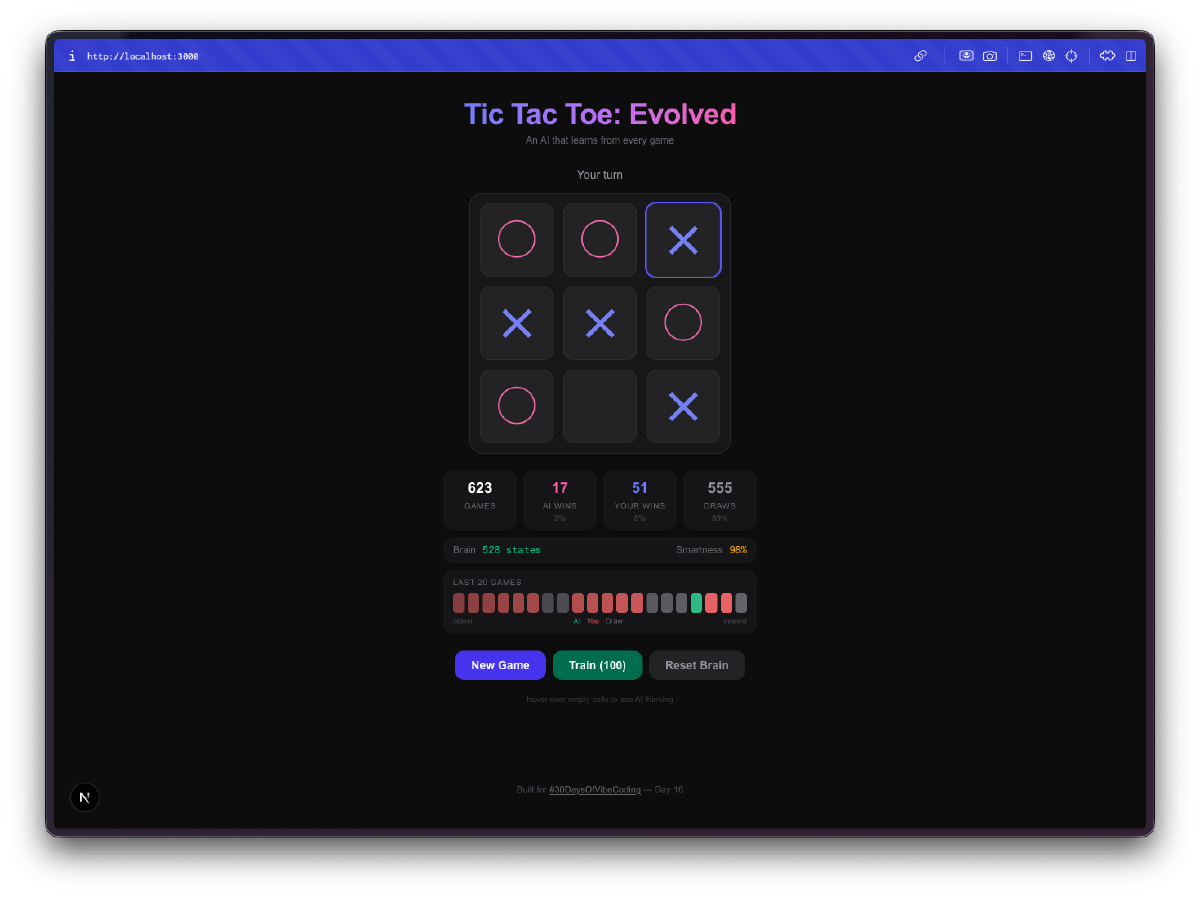
L’IA inizia malissimo. Le tue prime partite, gioca quasi a caso. Sceglie caselle senza strategia, cade nelle stesse trappole, perde in modi ovvi. Questo e esattamente il punto. Sta esplorando lo spazio di gioco, provando mosse che non ha mai provato prima, costruendo la sua Q-table da zero.
Poi smette di essere terribile. Da qualche parte tra le 50 e le 100 partite, noti che blocca le tue mosse vincenti. Dopo qualche centinaio di partite, pareggia costantemente. Allenala con qualche migliaio di partite contro se stessa e buona fortuna a vincere. La progressione da incapace a competente e davvero divertente da osservare.
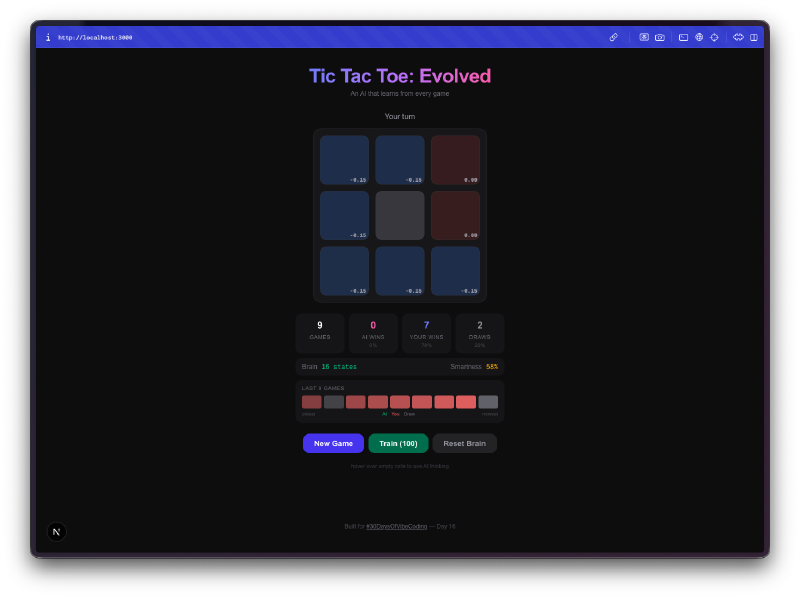
La visualizzazione del cervello e la parte migliore. Puoi passare il mouse sulle celle e vedere i Q-values che l’IA ha imparato per ogni posizione. Valori positivi alti significano che l’IA pensa che quella mossa porti a una vittoria. Valori negativi significano che ha imparato a evitare quella casella nello stato attuale. Stai letteralmente guardando la comprensione del gioco da parte dell’IA, e puoi vedere quei numeri cambiare man mano che gioca di piu.
L’allenamento in massa crea dipendenza. C’e una modalita di allenamento dove puoi lanciare 100, 1.000 o 10.000 partite contro se stessa. L’IA gioca contro se stessa, imparando da entrambi i lati. Puoi guardare la dimensione della Q-table crescere in tempo reale mentre scopre nuovi stati del tabellone. Dopo 10.000 partite, il cervello ha visto migliaia di posizioni uniche e ha un’opinione forte su ognuna di esse.
Tutto persiste. Chiudi la scheda, torna domani, e l’IA ricorda tutto cio che ha imparato. La Q-table, le statistiche di gioco, la cronologia delle serie di vittorie. E tutto salvato nel localStorage. Il tuo avversario IA ha una memoria permanente, il che significa che piu giochi contro di lei nel corso dei giorni e delle settimane, migliore diventa.
Le modalita di difficolta cambiano il tasso di esplorazione. La modalita facile mantiene l’epsilon (la casualita) alto cosi che l’IA commette piu errori. La modalita difficile abbassa l’epsilon cosi che sceglie quasi sempre la mossa che pensa sia migliore. Questo ti permette di controllare quanto l’IA si affida a cio che ha imparato rispetto al provare cose nuove.
I piccoli dettagli contano. Le linee vincenti vengono evidenziate. Gli effetti sonori accompagnano le mosse, vittorie, sconfitte e pareggi. C’e una cronologia delle partite recenti che mostra i tuoi ultimi 20 risultati come tracker visivo delle serie. Il tutto da l’impressione di un vero gioco, non solo una demo tecnica.
I Numeri#
- 4 task Watchfire dallo scaffolding alla rifinitura
- La Q-table cresce fino a migliaia di voci dopo l’allenamento in massa
- 3 modalita di difficolta che controllano il compromesso esplorazione/sfruttamento
- Persistenza completa in localStorage per il cervello dell’IA e tutte le statistiche
- 0 strategie codificate nell’IA. Tutto cio che sa, l’ha imparato
Provalo#
Gioca qualche partita e guarda l’IA migliorare. Oppure premi il pulsante di allenamento e lascia che impari da sola.
Verdetto del Giorno 16#
Il tic-tac-toe e un gioco risolto. Qualsiasi giocatore perfetto puo forzare un pareggio ogni volta. Ed e esattamente questo che lo rende un campo di gioco ideale per il reinforcement learning. Il gioco e abbastanza semplice perche l’IA possa esplorare l’intero spazio degli stati in un numero ragionevole di partite, e puoi davvero vederla convergere verso il gioco ottimale.
Quello che mi piace di questo progetto e che rende il machine learning tangibile. Non stai leggendo del Q-learning in un libro di testo o guardando curve di perdita in un notebook Jupyter. Stai giocando contro un’IA che diventa visibilmente piu intelligente. Puoi vedere i suoi Q-values, guardare il suo cervello crescere, e sentire la differenza tra giocarci alla partita 10 rispetto alla partita 10.000.
Il fatto che tutto giri nel browser senza backend, senza Python, senza TensorFlow, solo TypeScript e localStorage, lo rende accessibile. Il Q-learning e uno degli algoritmi di reinforcement learning piu semplici, ma vederlo funzionare in tempo reale su un gioco che gia capisci fa scattare il concetto in un modo che la teoria da sola non riesce mai a fare.
Questo e il giorno 16 di 30 Days of Vibe Coding. Segui l’avventura mentre pubblico 30 progetti in 30 giorni usando il coding assistito dall’IA.