まず基礎から始めて、順を追って進んでいきましょう。
基礎#
AI vs ML vs ディープラーニング#
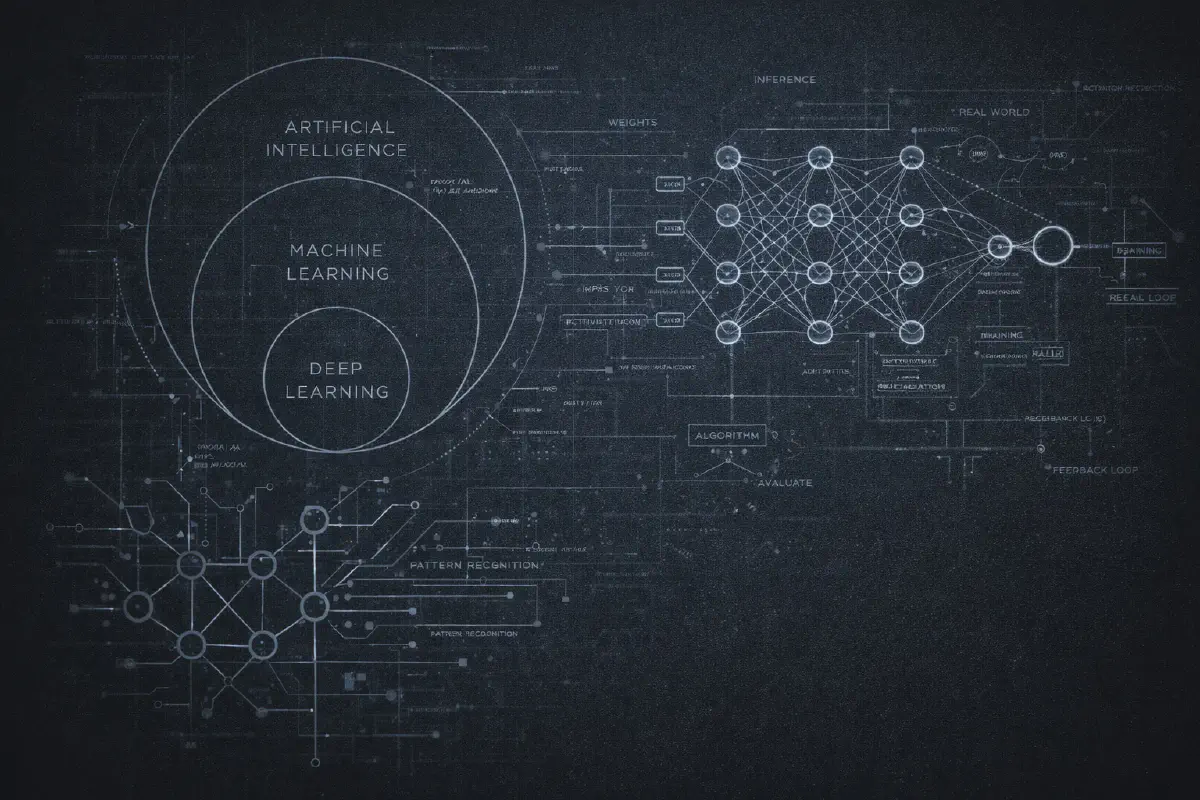
おそらく見たことがある図:AIが外側、機械学習(Machine Learning)が中央、ディープラーニング(Deep Learning)がコアにある3つの同心円。使い古された図ですが、これらの用語の関係を理解するのに本当に役立ちます。
**人工知能(Artificial Intelligence、AI)**は最も広い用語です。これは単に「人間がやれば知能が必要なことをコンピュータにさせる」という意味です。それだけです。1970年代のチェスプログラム?AI。スパムフィルター?AI。ポップアップを表示するかどうかを決める単純なif-elseルール?技術的にはAI。この用語は単独ではほとんど意味がないほど広いです。
**機械学習(Machine Learning、ML)**はAIのサブセットで、明示的なルールをプログラムする代わりに、コンピュータに例を与えてパターンを見つけさせます。「メールに『ナイジェリアの王子』が含まれていたらスパムにする」と書く代わりに、「スパム」または「スパムではない」とラベル付けされた10,000通のメールを見せて、アルゴリズムに何がスパムを…スパムたらしめているのかを学習させます。
**ディープラーニング(Deep Learning)**は機械学習のサブセットで、多くの層を持つニューラルネットワークを使用します(だから「ディープ(深い)」)。2010年代に面白くなったのはここからです。ディープラーニングは画像認識、音声認識、そして最終的には私たちが今夢中になっている言語モデルのブレークスルーを可能にしました。
ニューラルネットワーク#
不完全だけど役立つアナロジー:ニューラルネットワークは何百万もの調整可能な数値を持つ非常に複雑なスプレッドシートのようなものです。
データは片側から入ります。それはこれらの数値で乗算され、加算され、いくつかの数学的関数を通過し、最終的に反対側で出力を生成します。「学習」の部分は、出力が望むものと一致するまでこれらすべての数値を調整することです。
より深く知りたい場合:ネットワークは層に組織化されています。各層には「ニューロン」(実際には単なる数学関数)が含まれています。各ニューロンは入力を受け取り、重みで乗算し、合計し、活性化関数を通して結果を渡します。魔法は多くの層を重ねたときに起こります - ネットワークは人間が手でプログラムできないほど信じられないほど複雑なパターンを学習できるのです。
「ニューラル」という用語は、脳の生物学的ニューロンへの緩いアナロジーから来ています。これを文字通りに受け取らないでください。これらのシステムは実際の脳とはまったく異なる方法で動作します。このメタファーは1940年代の元の研究者にとっては有用でしたが、やや誤解を招くものになっています。
Training vs Inference#
すべてのAIシステムには2つの異なるフェーズがあり、これらを混同すると無限の誤解が生じます。
トレーニングは高価な部分です。これはモデルに何百万(または何十億)もの例を見せ、モデルがそのタスクに習熟するまですべての内部数値を調整するときです。GPT-4のトレーニングには計算だけで1億ドル以上かかったと報告されています。トレーニングは一度(またはモデルを更新したいときに定期的に)行われます。
推論は比較的安価な部分です。これは実際にトレーニングされたモデルを使用するときです。入力を与えると、出力が生成されます。ChatGPTとチャットするたびに、推論を行っています。モデルの数値は固定されており、計算を実行しているだけです。
教育と仕事のように考えてください。トレーニングは何年もの学校と勉強です。推論は仕事に行って学んだことを使うことです。投資は前払いで行われ、見返りは使用中に得られます。
LLMを理解する#
What Makes LLMs Special#
大規模言語モデル(Large Language Models、LLM)はテキストを予測するようにトレーニングされた特定のタイプのディープラーニングモデルです。これが核心の洞察です:本質的に、LLMはシーケンス内の次の単語(またはトークン)を予測しようとしているだけです。
“猫はマットの上に___” → “座った”(おそらく)
しかし、驚くべきことは:インターネット、本、コード、科学論文からの何兆もの単語でこの単純な目的をトレーニングすると、驚くべきことが起こります。モデルは文法だけでなく、事実、推論パターン、コーディング規約、さらには常識のように見える何かを学習します。
これは創発的行動と呼ばれます - 明示的にトレーニングされていないが、トレーニングの規模から生まれた能力。誰もGPT-4に詩を書いたり数学の問題を解いたりするようにプログラムしていません。これらの能力は、次のトークンを本当に、本当にうまく予測するという目的から創発しました。
トランスフォーマーとアテンション#
現代のLLMを可能にしたアーキテクチャはトランスフォーマーと呼ばれ、有名な「Attention Is All You Need」という2017年の論文で紹介されました。
重要なイノベーションはアテンションメカニズムです。以前のモデルはテキストを順番に処理していました - 単語ごとに、左から右へ。アテンションにより、モデルはすべての単語を同時に見て、どの単語が互いに関連しているかを学習できます。
簡単な例:“その動物は疲れすぎていたので道路を渡らなかった。”
「その」は何を指しているでしょうか?動物です。しかし、モデルはどうやって知るのでしょうか?アテンションメカニズムは「その」が「動物」に強く注目し、「道路」に弱く注目すべきことを学習します。この長距離の依存関係を捉える能力が、トランスフォーマーを言語に対してこれほど強力にしています。
トークンとコンテキストウィンドウ#
LLMは実際には単語を見ません - トークンを見ます。トークンはテキストの塊で、通常は単語または単語の一部です。「Understanding」は1つのトークンかもしれませんし、「un」+「derstand」+「ing」はモデルのトークナイザーによっては3つのトークンかもしれません。
なぜこれが重要なのでしょうか?モデルには限られたコンテキストウィンドウ - 一度に処理できるトークンの最大数 - があるからです。初期のGPT-3は4Kトークンのコンテキストを持っていました。GPT-4 Turboは128Kに拡張されました。Claudeは200Kを処理できます。一部の新しいモデルは数百万を主張しています。
コンテキストウィンドウはモデルの作業メモリと考えてください。モデルに考慮させたいすべてのもの - 質問、共有しているドキュメント、会話履歴 - はこのウィンドウに収まる必要があります。
| モデル | コンテキストウィンドウ | おおよその換算 |
|---|---|---|
| GPT-3 (2020) | 4Kトークン | 約3,000語 |
| GPT-4 Turbo | 128Kトークン | 約100,000語 |
| Claude 3.5 | 200Kトークン | 約150,000語 |
| Gemini 1.5 Pro | 100万以上トークン | 約750,000語 |
プロンプトエンジニアリング#
プロンプトはLLMに送信するテキストです。質問、指示、提供するコンテキスト - すべてプロンプトの一部です。
プロンプトエンジニアリングは、より良い結果を得るプロンプトを書く技術(そしてますます科学)です。質問を「エンジニアリング」するなんて馬鹿げているように聞こえますが、本当に重要です。
効果的なテクニック:
- 具体的に。 「詩を書いて」vs.「気候変動についてシェイクスピア風の14行のソネットを書いて」 - 後者ははるかに良い結果を得ます。
- 例を示す。 実際の出力を求める前に、望むものの例をいくつかモデルに与えます。これは「few-shot prompting」と呼ばれます。
- ステップバイステップで考える。 複雑な問題の前に「これをステップバイステップで考えてみましょう」と追加すると精度が向上します。これは「chain-of-thought」プロンプティングと呼ばれます。
- 役割を割り当てる。 「あなたは専門の税理士です」はモデルの応答を焦点化します。
Temperature & Parameters#
LLM APIを使用するとき、出力に影響を与えるいくつかのパラメータを調整できます。最も重要なのは**温度(temperature)**です。
温度はランダム性を制御します。温度0では、モデルは常に最も確率の高い次のトークンを選択します - 決定論的、予測可能、時には退屈。温度1以上では、確率の低いトークンを選ぶ意欲が高まります - より創造的、より多様、時にはナンセンス。
- 温度0: 「フランスの首都はパリです。」
- 温度1: 「フランスの首都はパリ、革命とロマンスが石畳の通りを踊る壮大な光の都市です…」
その他の一般的なパラメータ:
- Top-p(核サンプリング): どのトークンを考慮するかを制限することでランダム性を制御する別の方法。
- Max tokens: 応答の長さ。
- Stop sequences: モデルに生成を停止するタイミングを伝えます。
- Frequency/presence penalty: 繰り返しを減らします。
ハルシネーション#
LLMは物事をでっち上げます。完全な自信を持って虚偽を述べます。存在しない論文を引用します。統計を捏造します。これは**ハルシネーション(幻覚)**と呼ばれ、修正されるバグではありません - これらのモデルの動作方法の結果です。
覚えておいてください:LLMは真実のテキストではなく、もっともらしいテキストを予測するようにトレーニングされています。モデルのトレーニングデータが限られているトピックについて質問すると、正しく聞こえる何かを生成します。モデルには内部のファクトチェッカーがなく、真実への接続がなく、「分かりません」と言う方法がありません。
なぜこれが起こるのでしょうか?
- トレーニング目的: 真実を検証するのではなく、次のトークンを予測する。
- 確率分布: モデルは可能性からサンプリングします。正しい答えが最も可能性が高くても、サンプリングは別のものを選ぶかもしれません。
- 知識カットオフの認識がない: モデルはその知識の境界を確実に知りません。
ハルシネーションを減らす戦略:
- RAGを使用して実際のドキュメントに応答を基づかせる
- モデルにソースを引用させ、それを検証する
- 事実に基づくタスクには温度を下げる
- 応答を制約する構造化された出力を使用する
- ファクトチェック層を実装する
モデルの状況#
Open vs Closed Models#
クローズドソース: APIを介してモデルを使用できますが、重み、アーキテクチャの変更、自分での実行はできません。OpenAIのGPT-4、AnthropicのClaude、GoogleのGemini。
オープンソース/オープンウェイト: 重みは公開されています。ダウンロード、ローカル実行、ファインチューニング、変更ができます。MetaのLlama、Mistral、AlibabaのQwen、DeepSeek、その他多数。
区別は重要ですがニュアンスがあります:
- 「オープンウェイト」はモデルをダウンロードして実行できることを意味します
- 「オープンソース」は伝統的にトレーニングコードとデータも利用可能であることを意味します(大規模モデルではまれ)
- ライセンスは様々です - 一部のオープンモデルには商用制限があります
なぜMetaはLlamaを無料で公開するのでしょうか?戦略的な理由:補完物のコモディティ化、エコシステムの構築、人材の獲得、標準の設定。皮肉な見方:APIの収益でOpenAIと競争できないので、モデル層を無料にして他の場所で利益を得ることで競争しています。
マルチモーダルモデル#
初期のLLMはテキストのみを理解しました。マルチモーダルモデルは複数のタイプのデータ - テキスト、画像、音声、ビデオ - を理解します。
GPT-4Vは写真を見て説明できます。Claudeはチャートや図を分析できます。Geminiはビデオを見ることができます。これは単なる目新しさではありません - まったく新しいユースケースを開きます:
- バグのスクリーンショットを撮ってデバッグの助けを求める
- 手書きの図をアップロードしてコードを取得する
- 医療画像を分析する
- コンテンツモデレーションのためにビデオを処理する
- 別々の音声テキスト変換なしの音声インターフェース
アーキテクチャは様々です。一部のモデルはネイティブにマルチモーダルとしてトレーニングされています。他のモデルは別々のビジョンモデルと言語モデルを接続します。この区別はパフォーマンスには重要ですが、ほとんどのユーザーには関係ありません。
推論モデル#
標準的なLLMは明示的な「思考」なしにトークンごとに応答を生成します。推論モデルは異なるアプローチを取ります - 回答する前に問題を考え抜くために追加の計算を費やします。
OpenAIのo1とo3モデルがこのアプローチを開拓しました。すぐに応答する代わりに、これらのモデルは内部推論チェーン(ユーザーには見えないことがある)を生成し、複数のアプローチを検討し、最終的な回答を生成する前に作業をチェックします。
結果は印象的です:推論モデルは数学、コーディング、科学、論理問題で標準的なLLMを劇的に上回ります。o3は何年も先だと思われていた特定のベンチマークでスコアを達成しました。
トレードオフ:推論モデルは遅く、より高価です。GPT-4がすぐに答える簡単な質問でも、o1が「考える」と数秒(そして10倍のコスト)かかるかもしれません。単純なタスクでは、それは無駄です。難しい問題には、価値があります。
推論モデルを使うとき:
- 複雑な数学や論理問題
- 複数ステップのコーディングチャレンジ
- 慎重な分析が必要なタスク
- 速度よりも精度が重要なもの
標準的なLLMがより良いとき:
- シンプルなQ&A
- クリエイティブライティング
- リアルタイムアプリケーション
- コスト重視のユースケース
消費者向けAI製品#
技術的な詳細に深入りする前に、おそらくすでに使用した製品をマッピングしましょう:
ChatGPT(OpenAI) - 主流のAIの波を始めた製品。GPT-4、o1、画像用のDALL-E、各種プラグインへのアクセス。他のすべてが比較されるベンチマーク。
Claude(Anthropic) - 強力なライティング、長いコンテキストウィンドウ、ニュアンスのある推論で知られています。Claude.aiは消費者向けインターフェース;APIは多くのアプリケーションを動かしています。
Gemini(Google) - Googleのエコシステムと深く統合されています。gemini.google.comを介してアクセスし、Search、Docs、Gmail、Androidにますます組み込まれています。
Copilot(Microsoft) - 製品全体にわたるMicrosoftのAI層。GitHub Copilot(コーディング)とは異なります - これはWindows、Edge、Microsoft 365の消費者向けアシスタントです。
Perplexity - AIネイティブの検索エンジン。引用とソースで質問に答えます。検索がどうなるかの一端を垣間見せています。
他に知っておくべきもの: Grok(xAI、X/Twitterに統合)、Pi(Inflection)、Le Chat(Mistral)、DeepSeek Chat、および多くの地域/専門的な代替品。
モデルをローカルで実行する#
なぜローカルで実行するのか?#
クラウドモデルは他の誰かのサーバーで実行されます。インターネット経由でリクエストを送信し、使用量に応じて支払います。OpenAI、Anthropic、Google - これが彼らのビジネスです。
ローカルモデルは自分のハードウェアで実行されます。ノートパソコン、サーバー、データセンター。データは決して管理外に出ません。
なぜローカルで実行するのでしょうか?
- プライバシー: 機密データはオンプレミスに留まる
- コスト: API料金なし(ただしハードウェアは無料ではない)
- レイテンシー: ネットワークラウンドトリップなし
- 可用性: オフラインで動作、レート制限なし
- コントロール: 利用規約なし、選択しなかったコンテンツフィルターなし
ローカルとクラウドのギャップは劇的に縮小しました。多くの実用的なアプリケーションでは、ローカルモデルで十分です - 特にコーディング、ライティング、分析タスクでは。
トレードオフ:フロンティアの能力にはまだクラウドが必要です。難しい推論タスクで絶対最高のパフォーマンスが必要な場合、GPT-4、Claude、Geminiはクラウドのみです。しかし、そのギャップはリリースごとに縮小しています。
Ollama#
Ollamaはモデルをローカルで実行するためのデファクトスタンダードになりました。かつては複雑だったプロセスを驚くほど簡単にします。
# 2つのコマンドでモデルをインストールして実行
ollama pull llama3.2
ollama run llama3.2これだけです。完全にあなたのマシンで実行される有能なLLMとチャットしています。
Ollamaは複雑さを処理します:モデルのダウンロード、メモリ管理、ハードウェアの最適化、CLIとローカルAPIの両方の提供。何十ものモデルをサポートしています - Llama、Mistral、Qwen、Phi、CodeLlama、その他多数。
主な機能:
- シンプルなCLIインターフェース
- OpenAI互換API(既存のコードへの簡単なスワップ)
- ワンコマンドダウンロードのモデルライブラリ
- Mac、Linux、Windowsで動作
- 利用可能な場合はGPUアクセラレーション
開発者にとって、OllamaのローカルAPIはローカルモデルに対して開発し、本番用にクラウドAPIに切り替える - またはその逆 - ことを最小限のコード変更で可能にします。
ハードウェアの考慮事項#
モデルをローカルで実行するにはハードウェアが必要です。重要なものは以下の通りです:
GPU vs CPU: GPUは推論を劇的に加速します。CPUで1回の応答に30秒かかるモデルが、GPUでは2秒かかるかもしれません。Apple Silicon Macはこの境界をぼかします - 統合メモリとNeural Engineにより、ローカル推論に驚くほど有能です。
メモリ(VRAM/RAM): これが通常制限要因です。モデルはメモリに収まる必要があります。7Bパラメータモデルは約4-8GB必要です。70Bモデルは35-70GB必要です。量子化(後述)はこれらの要件を削減します。
量子化: モデルの重みの精度を32ビットから16ビット、8ビット、または4ビットに削減すること。これによりメモリ要件が縮小し、品質の低下を最小限に抑えて推論が高速化されます。ほとんどのローカルモデルは量子化された形式(GGUF、GPTQ、AWQ)で配布されています。
実践的なガイダンス:
- 16GB以上のRAMを持つMac: 7B-13Bモデルを快適に実行できます
- 32GB以上のRAMを持つMac: 30B以上のモデルを実行できます
- RTX 3090/4090(24GB VRAM)を持つPC: ほとんどの70Bまでのモデルを実行できます(量子化)
- GPUなし: まだ動作しますが、遅くなります。開発と実験には問題ありません。
カスタマイズと知識#
Fine-Tuning vs RAG#
ベースのLLMがあります。特定のユースケースに合わせてより良くしたい。主に2つのアプローチがあります:
ファインチューニング#
既存のモデルを取り、自分のデータで引き続きトレーニングします。モデルの重みが実際に変わります。ファインチューニング後、モデルはあなたの情報をネイティブに「知って」います。
利点: 高速推論、知識の深い統合、新しいスタイルや動作を学習できる。 欠点: 高価、MLの専門知識が必要、知識が古くなる可能性、壊滅的忘却のリスク(モデルが他のタスクで悪化する)。
RAG(検索拡張生成)#
モデルはそのまま維持します。質問が来たら、まず関連するドキュメントのためにナレッジベースを検索し、それらのドキュメントを質問と一緒にプロンプトに含めます。
利点: 安価、知識は最新の状態を維持、トレーニング不要、監査が容易(何が検索されたか見える)。 欠点: 遅い(2ステッププロセス)、コンテキストウィンドウによって制限、検索品質が非常に重要。
Embeddings & Vector DBs#
これはRAGを機能させる技術です - そして本当に賢いです。
エンベディングはテキスト(または画像、または何でも)を数値のリスト - ベクトル - として表現する方法です。魔法:似たものは似たベクトルを持ちます。「犬」と「子犬」は近いベクトルを持ちます。「犬」と「民主主義」は離れています。
エンベディングモデルを使用してエンベディングを作成します(LLMとは異なりますが、一部のLLMにはエンベディング機能があります)。OpenAI、Cohere、Voyage、および他の多くがエンベディングAPIを提供しています。BGEやE5などのオープンソースオプションもうまく機能します。
ベクターデータベースはこれらのベクトルを保存および検索するために最適化されたデータベースです。「返金ポリシーは何ですか?」と質問すると、システムは:
- 質問をベクトルに変換する
- ベクターデータベースで類似のベクトルを検索する
- それらのベクトルが表すドキュメントを返す
- それらのドキュメントを質問とともにLLMにフィードする
人気のあるベクターデータベースには、Pinecone、Weaviate、Chroma、Qdrant、Milvusがあります。pgvectorを使用したPostgresは多くのユースケースで驚くほどうまく機能します。
評価#
ベンチマーク#
あるモデルが別のモデルより「優れている」かどうかをどうやって知りますか?ベンチマークは標準化されたタスクでモデルをテストすることでこれに答えようとします。
一般的なベンチマーク:
- MMLU(Massive Multitask Language Understanding): 57科目にわたる多肢選択問題。一般知識をテスト。
- HumanEval: コーディング問題。プログラミング能力をテスト。
- GSM8K: 小学校レベルの算数の文章問題。数学的推論をテスト。
- HellaSwag: 日常的な状況についての常識的推論。
- TruthfulQA: モデルが説得力のあるナンセンスではなく真実の回答を与えるかをテスト。
ベンチマークの問題: ゲーム化できます。モデルは実際のタスクで改善することなく、人気のあるベンチマークでうまくいくように特別にトレーニングできます。MMLUで90%をスコアするモデルが、あなたの特定のユースケースではまだ失敗するかもしれません。
Evals#
**評価(Evals)**は特定のユースケースのために作成するテストです。ベンチマークとは異なり、評価はアプリケーションにとって実際に重要なことを測定します。
カスタマーサービスボットを構築していますか?評価は以下をテストするかもしれません:
- FAQからの質問に正しく答えるか?
- 必要なときに適切に人間にエスカレーションするか?
- ブランドに沿って、トーンガイドラインに従うか?
- 会社が守れない約束をすることを拒否するか?
評価が重要な理由:
- 回帰検出: プロンプトを変更したりモデルを切り替えたりするとき、評価はユーザーより先に問題をキャッチします。
- 比較: ユースケースに対して異なるモデル、プロンプト、アプローチを客観的に比較します。
- イテレーション: 測定できないものは改善できません。評価は改善を体系的にします。
良い評価を構築する:
- 実際のユーザークエリと期待される応答から始める
- エッジケースと敵対的な例を含める
- モデルがすべきこととすべきでないことの両方をテストする
- すべての変更で評価を実行できるように自動化する
LLM as a Judge(審査員としてのLLM)#
賢いテクニックがあります:あるLLMを使用して別のLLMの出力を評価します。
数百の応答を手動でレビューする代わりに、モデルに審査員として行動するようプロンプトできます:
あなたはAIアシスタントの応答の品質を評価しています。
ユーザーの質問:{question}
アシスタントの応答:{response}
応答を以下の基準で評価してください:
1. 正確性(1-5):情報は正確ですか?
2. 有用性(1-5):実際にユーザーを助けていますか?
3. 明確さ(1-5):理解しやすいですか?
理由を説明してから、スコアを提供してください。なぜこれが機能するか:
- 何千もの評価にスケールする
- 人間のレビュアーより一貫性がある(疲労が少ない)
- プログラムでテストするのが難しいニュアンスのある品質を評価できる
- 人間の評価より安価で速い
制限:
- 審査員モデルには独自のバイアスと制限がある
- 自分がするであろうエラーを見逃す可能性がある
- グラウンディングなしではドメイン固有の正確性に苦労する
- 人間の評価の完全な代替ではない - むしろ補完
エージェントと自動化#
エージェントとは何か?#
「エージェント」という用語はよく使われます。ここに実用的な定義があります:エージェントは世界でアクションを取ることができるLLMで、単にテキストを生成するだけではありません。
チャットボットは質問に答えます。エージェントは質問に答えかつレストランの予約をし、メールを送信し、データベースをクエリし、問題を解決するためにコードを書いて実行するかもしれません。
何かがただのLLMではなくエージェントである理由は何でしょうか?
- 目標: エージェントはプロンプトに応答するだけでなく、目的に向かって働きます。
- アクション: エージェントは言うだけでなく、行うことができます。
- 自律性: エージェントは目標を達成する方法について決定を下します。
- ループ: エージェントはしばしばループで実行されます - 観察、考え、行動、繰り返し。
最もシンプルなエージェントパターン:LLMにツールへのアクセスを与え、どのツールを使用するか決定させます。「来週のロンドンから東京へのフライトを見つけて、カレンダーをチェックし、スケジュールに合う最も安いオプションを予約してください。」エージェントはこれを分解し、フライトAPIを呼び出し、カレンダーAPIを呼び出し、予約を実行します。
エージェント vs ワークフロー#
しばしばぼやける重要な区別:
ワークフローは決定論的です。ステップを定義します:まずAをして、次にBをして、Xなら Cをそうでなければ Dをする。LLMは個々のステップを動かすかもしれませんが、オーケストレーションはコード化されています。
1. メールからエンティティを抽出(LLM)
2. データベースで顧客を検索(コード)
3. 応答ドラフトを生成(LLM)
4. 人間のレビューに送信(コード)エージェントは自律的です。目標とツールを与えると、ステップを自分で見つけ出します。LLMは現在の状態に基づいて次に何をするかを決定します。
目標:「この顧客の苦情を解決する」
ツール:[email, database, refund_system, escalation]
→ エージェントが何を、どの順序で行うかを決定ワークフローを使うとき:
- 予測可能で、よく理解されたプロセス
- 信頼性と監査可能性が必要なとき
- 規制環境
- 大量、低複雑性のタスク
エージェントを使うとき:
- 新規または可変のタスク
- ステップが事前に分からないとき
- 複雑な推論が必要
- 予測可能性よりも柔軟性が重要なとき
コスト方程式: ワークフローは大幅に安価です。実行ごとに固定数のLLM呼び出しに対して支払います - 予測可能、最適化可能、監査可能。エージェントは考えるので高価です。すべての決定ポイント - 「どのツールを使うべきか?」「それはうまくいったか?」「次は何?」 - はLLM呼び出しです。3回のLLM呼び出しを行うワークフローは、同じ問題を解決するエージェントでは15-30回の呼び出しになるかもしれません。なぜなら、エージェントはどのように解決するかについて推論しているからで、事前定義されたステップを実行しているだけではありません。大規模でよく理解されたタスクでは、ワークフローがコストで勝ちます。ステップを事前定義できない複雑で可変な問題では、エージェントはプレミアムの価値があります。
Tool Use & Function Calling#
エージェントがアクションを取るには、ツール - 呼び出せる関数 - が必要です。この機能は通常関数呼び出しまたはツール使用と呼ばれます。
仕組みは以下の通りです:
- 名前、説明、パラメータ(通常はJSONスキーマとして)を持つツールを定義する
- これらの定義をプロンプト/API呼び出しに含める
- モデルはテキストを生成する代わりにツールを「呼び出す」ことを選択できる
- あなたのコードが関数を実行し、結果をモデルに返す
- モデルはそれらの結果を使用して続行する
ツール定義の例:
{
"name": "get_weather",
"description": "都市の現在の天気を取得",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "都市名"},
"units": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["city"]
}
}「東京の天気は?」と聞くと、モデルはハルシネーションせず - get_weather(city="Tokyo")を呼び出し、実際のデータを取得し、事実で応答します。
すべての主要なモデルプロバイダーが関数呼び出しをサポートしています:OpenAI、Anthropic、Googleなど。構文はわずかに異なりますが、コンセプトは同じです。
MCPプロトコル#
**Model Context Protocol(MCP)**はAIモデルをツールやデータソースに接続するためのオープンスタンダードです。AIのためのUSB-Cと考えてください - デバイスごとに異なるケーブルが必要ないユニバーサルコネクタです。
MCP以前は、すべての統合がカスタムでした。AIにGitHubへのアクセスを許可したい?GitHub統合を書く。Salesforce?別の統合。社内データベース?さらに別の統合。これはスケールしません。
MCPはAIクライアント(Claude、ChatGPT、またはカスタムエージェントなど)がMCPサーバーからツールを発見して使用するための標準的な方法を定義します。MCPサーバーは以下を公開するかもしれません:
- ツール: AIが呼び出せる関数
- リソース: AIが読めるデータ
- プロンプト: 一般的なタスクのテンプレート
意味は重要です:
- MCPサーバーを一度構築すれば、互換性のあるすべてのAIが使用できる
- ツールはポータブルで再利用可能になる
- セキュリティと権限を標準化できる
- エコシステムは複合的 - サーバーが増えればより有能なエージェントになる
MCPについてより詳しくは、私がより深く書いた記事があります:MCPサーバー:AIエージェントのUSB-Cモーメント。
エージェントパターン#
エージェントが成熟するにつれて、一般的なパターンが現れてきました:
ReAct(推論+行動): エージェントは推論(「ユーザーの注文履歴を見つける必要がある」)と行動(注文APIを呼び出す)を交互に行います。この明示的な推論ステップは信頼性を向上させます。
計画: 行動する前に、エージェントは計画を作成します:「これを解決するには、1)注文を検索し、2)在庫を確認し、3)返金を処理し、4)確認を送信する必要があります。」計画は実行前に検証できます。
リフレクション: タスクを完了した後(または失敗した後)、エージェントは何が起こったかをレビューします:「注文が古すぎたため返金が失敗しました。最初に返金ポリシーを確認すべきでした。」これにより学習と自己修正が可能になります。
ツール選択: エージェントに多くのツールがあるとき、適切なものを選ぶことは簡単ではありません。テクニックにはツールの説明、few-shotの例、階層的なツール組織が含まれます。
ヒューマン・イン・ザ・ループ: 高リスクのアクションでは、エージェントは続行する前に一時停止して人間の承認を求めることができます。良いエージェントは自分が不確かなときを知っています。
スキル#
スキルは、エージェントができることを拡張する再利用可能で専門化されたプロンプトです。エージェントにプラグインできる「エキスパートモード」と考えてください - コードレビュー用のスキル、ドキュメント作成用のスキル、セキュリティ脆弱性分析用のスキルなど。
ツール(何かを実行する関数)とは異なり、スキルはエージェントがどのように考え、応答するかを形作る指示です。ツールはAPIを呼び出します。スキルはエージェントに「Xについて質問されたら、このようにアプローチし、これらの要素を考慮し、このように応答をフォーマットしてください」と伝えます。
スキルが重要な理由:
- ファインチューニングなしの専門化: 新しいモデルをトレーニングすることなく、エキスパートな振る舞いを得られます。
- 構成可能性: 異なるタスクに応じてスキルを組み合わせることができます。
- 共有可能性: よく作られたスキルはチーム、プロジェクト、または公開で共有できます。
- コンテキスト効率: 毎回要件を説明する代わりに、一度スキルにエンコードします。
スキルの配置場所:
スキルはエージェントのコンテキストの異なるポイントに注入できます:
- システムプロンプト: 最も一般的なアプローチ。スキルはエージェントの基本指示の一部となり、常にアクティブです。
- ユーザーメッセージプレフィックス: ユーザーリクエストに動的に前置されます。タスク固有のスキルに便利です。
- ツール説明: スキルはツール定義に埋め込むことができ、エージェントが特定のツールをどのように使用するかをガイドします。
- MCPプロンプト: MCPサーバーはスキルを「プロンプト」として公開できます - クライアントが発見して呼び出せる再利用可能なテンプレートです。
スキルがコンテキストに与える影響:
すべてのスキルはコンテキストウィンドウからトークンを消費します。これはトレードオフを生みます:
- より多くのスキル = より有能なエージェント、しかし会話履歴のための余地が少なくなる
- 詳細なスキル = より良い振る舞い、しかしリクエストごとのトークンコストが高くなる
- 常時オンのスキル vs オンデマンドのスキル = 信頼性 vs 効率性
スマートなエージェントフレームワークは、タスクに基づいて関連するスキルをアクティブにし、他のスキルを非アクティブにすることで、これを動的に管理します。
スキル構造の例:
## コードレビュースキル
コードをレビューする際は、以下を行ってください:
1. セキュリティ脆弱性をチェック(インジェクション、XSS、認証問題)
2. パフォーマンスの懸念を特定
3. 可読性と保守性を評価
4. コード例を含む具体的な改善を提案
レビューは以下の形式でフォーマットしてください:
- 概要(1-2文)
- 重大な問題(ある場合)
- 提案(箇条書きリスト)
- 総合評価コーディングエージェント#
なぜ重要なのか#
コーディングエージェントはAIの最も具体的なアプリケーションの1つを代表しています - 実際にコードを書き、そのコードは実際に動作します。これは理論的ではありません;開発者はこれらのツールのおかげでより速く機能を出荷しています。
影響は即座に測定可能です:ボイラープレートに費やす時間が減り、デバッグが速くなり、馴染みのないコードベースの探索が容易になります。多くの開発者にとって、コーディングエージェントはIDEと同じくらい必要不可欠なものになっています。
状況#
Claude Code - Anthropicのターミナルベースのコーディングエージェント。CLIに存在し、コードベース全体を理解し、ファイルを読み、コードを書き、コマンドを実行し、フィードバックに基づいてイテレーションできます。ターミナルで暮らす開発者向けに設計されています。
Cursor - AI支援を中心にゼロから構築されたAIネイティブIDE。単なる自動補完ではありません - コードベースとチャットし、機能全体を生成し、AIにファイル全体にわたる大規模な変更を行わせることができます。AIとのペアプログラミングに最も近いものです。
GitHub Copilot - オリジナルで最も広く展開されています。自動補完として始まり、チャットに進化し、現在はより大きなタスク用のCopilot Workspaceを含みます。深いGitHub統合。
Windsurf - CodeiumのAI IDE、Cursorの代替として位置付けられています。スピードと大規模なコードベースの理解に強い強調。
Cody(Sourcegraph) - コードベースの理解に焦点を当てています。コンテキストが重要な大規模で複雑なコードベースに特に強い。
Continue - 任意のIDEで動作するオープンソースのコーディングアシスタント。自分のモデルを持参(ローカルまたはクラウド)。AI設定を制御したいチーム向けに良い。
OpenCode - Claude Codeのオープンソース代替。ターミナルベース、モデルにとらわれない、コミュニティ主導の開発。
Aider - もう1つの優れたオープンソースターミナルコーディングエージェント。git統合と複数のファイルを一貫して操作する能力で知られています。
次のステップ#
基礎を一通り見てきました。次はどこへ?
Building Things#
- シンプルに始める。 API(OpenAI、Anthropicなど)を使用して、基本的なチャットボットまたはRAGシステムを構築します。最初はスタックを考えすぎないでください。
- ローカルモデルを試す。 Ollamaをインストールして、ノートパソコンでLlamaまたはQwenを実行します。驚くほど簡単です。
- エージェントを探索する。 エージェントシステムを構築するためにLangChain、LlamaIndex、CrewAIなどのフレームワークをチェックしてください。
- MCPを学ぶ。 公式ドキュメントはしっかりしています。ローカルでいくつかのMCPサーバーを実行してみてください。
- 早めに評価を構築する。 何を構築しても、初日から評価を作成してください。後で感謝するでしょう。
Understanding the Field#
- 研究をフォローする。 ArXivの論文、関心のあるトピックのGoogle Scholarアラート。
- 誇大広告を批判的に読む。 ほとんどの「ブレークスルー」は漸進的です。再現可能な結果と実際のベンチマークを探してください。
- 自分で実験する。 何がうまくいくかについての直感は、読むことではなく、実践的な経験から来ます。
リソース#
- Hugging Face - モデル、データセット、そして信じられないほどのコミュニティ
- Papers With Code - 実装付きの研究論文
- Ollama - 非常にシンプルなローカルモデル実行
- LangChain / LlamaIndex - LLMで構築するための人気のフレームワーク
- Model Context Protocol - MCPの仕様とSDK
- Chatbot Arena - 人間の投票でモデルを直接比較
2026年のAIは同時に過大評価され、過小評価されています。この技術は本当に変革的です - しかし本当に限られてもいます。LLMは物事をでっち上げます。エージェントは脆弱です。コストは高いです。進歩は速いですが不均一です。
最良のアプローチは実用的です:基礎を理解し、実際の問題で実験し、大きな主張には懐疑的でいて、物を構築する。この時代に繁栄する人々は、すべての略語を暗唱できる人ではありません - 実際に動く製品を出荷できる人です。
さあ、何か構築しましょう。





