Day 16。もしAI対戦相手が、あなたに負けたことから本当に学習したらどうなるだろう?
最初から完璧にプレイするミニマックスアルゴリズムじゃない。ランダムに打つやつでもない。最初はバカで、何がうまくいくかを観察して、徐々にあなたの倒し方を学んでいくもの。それがQ学習。そして、それを一番シンプルなゲームに組み込みたかった。
プロンプト#
「Q学習AIを搭載した三目並べゲームを作って。AIは毎試合から学習し、脳をlocalStorageに保存して、リアルタイムの統計情報を表示する」
どうやって作ったか#
Watchfireがこれを4つのタスクに分解してくれた:
- スキャフォールド - Next.jsプロジェクトの基本的なゲームボードとレイアウト
- Q学習AI - ε-greedy戦略とlocalStorageによるQテーブルの永続化
- 統計ダッシュボード、AIの脳の可視化、一括セルフプレイのトレーニングモード
- 難易度モード、勝利手のハイライト、効果音、最終仕上げ
最初のタスクで遊べる三目並べゲームができた。特に目新しいものはない。2つ目のタスクが面白くなったところで、AIが毎試合後に状態-行動価値を実際に更新するようになった。AIに勝てば、調整が入る。同じ方法で2回勝てば、その手をブロックし始める。Qテーブルは対戦するたびに成長していく。
タスク3と4で、学習実験から、実際に進化を観察できるものに変わった。脳の可視化では各セルのQ値が表示され、統計ダッシュボードでは勝率/敗率/引き分け率の推移が追跡でき、トレーニングモードでは数千回のセルフプレイゲームを実行してAIの教育を早送りできる。
できたもの#
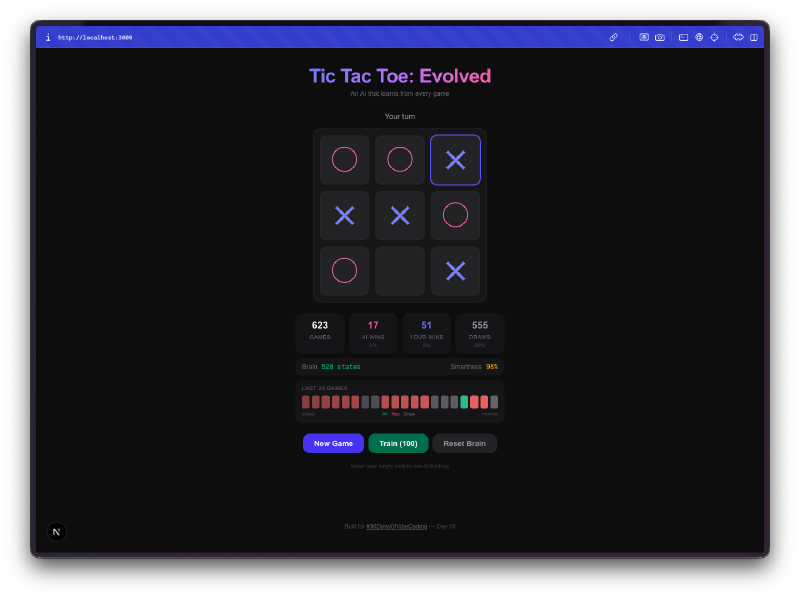
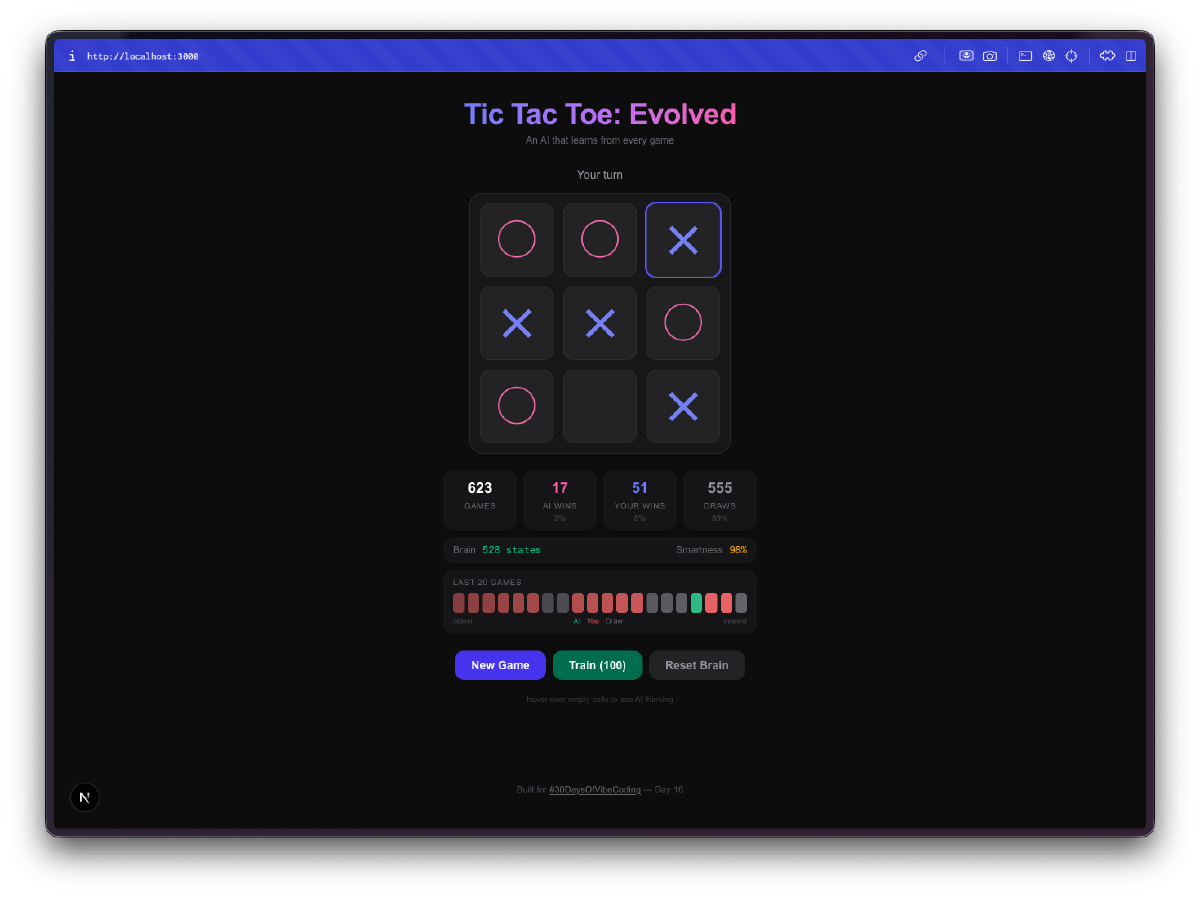
AIは最初ひどい。 最初の数ゲームは、ほぼランダムにプレイする。戦略なしでマスを選び、同じ罠に何度もはまり、明らかな負け方をする。これがポイント。ゲーム空間を探索し、まだ試していない手を試し、ゼロからQテーブルを構築しているんだ。
そのうちひどくなくなる。 50〜100ゲームくらいで、勝ち手をブロックしてくることに気づく。数百ゲームになると、コンスタントに引き分けるようになる。数千回のセルフプレイゲームでトレーニングすれば、勝つのはかなり難しくなる。無知から有能への進歩は、見ていて本当に楽しい。
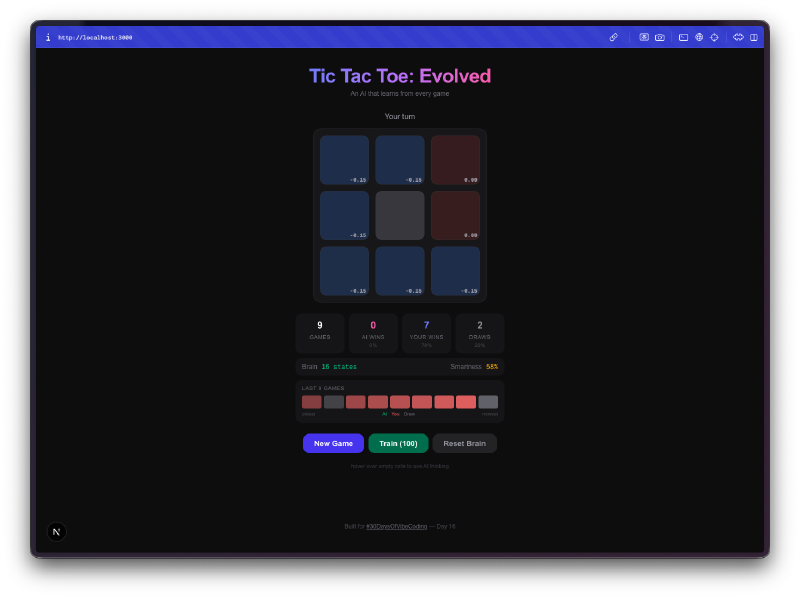
脳の可視化が一番いい部分。 セルにホバーすると、AIが各ポジションについて学習したQ値を見ることができる。高い正の値は、AIがその手が勝利につながると考えていることを意味する。負の値は、現在の状態でそのマスを避けることを学んだことを意味する。文字通りAIのゲーム理解を見ていることになり、プレイを重ねるにつれてその数値が変化していくのを観察できる。
一括トレーニングは中毒性がある。 100、1,000、または10,000回のセルフプレイゲームを実行できるトレーニングモードがある。AIが自分自身と対戦し、両方の側から学習する。新しいボード状態を発見するにつれてQテーブルのサイズがリアルタイムで成長していくのを見ることができる。10,000ゲーム後には、脳は何千ものユニークなポジションを見ており、そのすべてについて確固たる意見を持っている。
すべてが永続化される。 タブを閉じて、明日戻ってきても、AIは学んだことをすべて覚えている。Qテーブル、ゲーム統計、連勝記録。すべてlocalStorageに保存される。AI対戦相手は永久的な記憶を持っているので、日を重ねて週を重ねてプレイすればするほど、AIは強くなる。
難易度モードは探索率を変える。 イージーモードではε(ランダム性)を高く保つので、AIはより多くのミスを犯す。ハードモードではεを下げるので、ほぼ常に最善だと思う手を選ぶ。これにより、AIが学んだことにどれだけ頼るか、新しいことをどれだけ試すかをコントロールできる。
細かいところが大事。 勝利ラインがハイライトされる。手を打った時、勝った時、負けた時、引き分けた時に効果音が鳴る。直近20試合の結果をビジュアルストリークトラッカーとして表示する最近のゲーム履歴がある。全体がちゃんとしたゲームのように感じられて、ただの技術デモではない。
数字で見る#
- Watchfireタスク4つ スキャフォールドから仕上げまで
- Qテーブル 一括トレーニング後に数千エントリーに成長
- 3つの難易度モード 探索/活用のトレードオフをコントロール
- 完全なlocalStorage永続化 AIの脳とすべての統計情報
- ハードコードされた戦略ゼロ AIが知っていることはすべて、自分で学んだもの
試してみて#
数ラウンドプレイして、AIが上達していくのを見てみよう。もしくはトレーニングボタンを押して、自分で学ばせてみよう。
Day 16の評価#
三目並べは解かれたゲームだ。完璧なプレイヤーなら毎回引き分けに持ち込める。だからこそ強化学習の素晴らしい実験場なんだ。ゲームが十分にシンプルなので、AIが妥当な回数のゲームで全状態空間を探索でき、最適なプレイに収束していくのを実際に見ることができる。
このプロジェクトで気に入っているのは、機械学習を実感できるものにしているところだ。教科書でQ学習について読んだり、Jupyterノートブックで学習損失曲線を見たりしているんじゃない。目に見えて賢くなっていくAIと対戦しているんだ。Q値を見て、脳が成長するのを観察し、10ゲーム目と10,000ゲーム目の違いを体感できる。
バックエンドなし、Pythonなし、TensorFlowなし、TypeScriptとlocalStorageだけでブラウザ上で全部動くという事実が、親しみやすく感じさせる。Q学習は最もシンプルな強化学習アルゴリズムの1つだけど、すでに理解しているゲームでリアルタイムに動くのを見ると、理論だけでは絶対にできない形でコンセプトが腹落ちする。
これは30 Days of Vibe Codingの16日目です。AIアシステッドコーディングを使って30日間で30プロジェクトを出荷する過程をフォローしてね。