Vamos começar do início e avançar progressivamente.
Fundamentos#
IA vs ML vs Deep Learning#
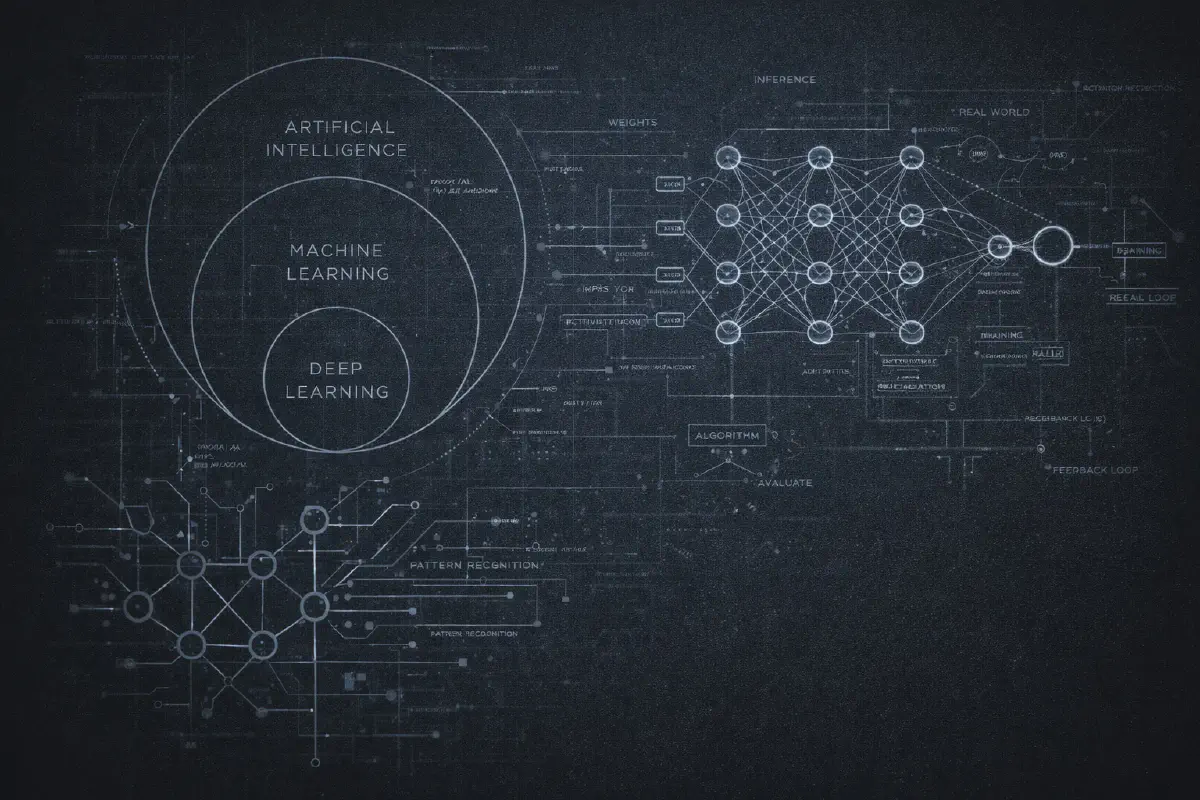
Provavelmente já viste o diagrama: três círculos concêntricos com IA no exterior, Machine Learning no meio, e Deep Learning no centro. Tornou-se um clichê, mas é genuinamente útil para compreender como estes termos se relacionam.
Inteligência Artificial é o termo mais abrangente. Significa simplesmente “fazer computadores fazer coisas que requereriam inteligência se os humanos as fizessem.” É só isso. Um programa de xadrez dos anos 1970? IA. O teu filtro de spam? IA. Uma simples regra if-else que decide se te mostra um popup? Tecnicamente, IA. O termo é tão abrangente que é quase sem significado por si só.
Machine Learning é um subconjunto de IA onde, em vez de programar regras explícitas, dás ao computador exemplos e deixas que ele descubra os padrões. Em vez de escrever “se o email contém ‘príncipe nigeriano’, marcar como spam,” mostras-lhe 10.000 emails rotulados como “spam” ou “não spam” e deixas o algoritmo aprender o que torna o spam… spam.
Deep Learning é um subconjunto de machine learning que usa redes neuronais com muitas camadas (daí “deep”). É aqui que as coisas ficaram interessantes nos anos 2010. O deep learning permitiu avanços no reconhecimento de imagem, reconhecimento de voz, e eventualmente os modelos de linguagem com que estamos todos obcecados agora.
Redes Neuronais#
Aqui está uma analogia que é imperfeita mas útil: uma rede neuronal é como uma folha de cálculo muito complicada com milhões de números ajustáveis.
Os dados entram de um lado. São multiplicados por estes números, somados, passados através de algumas funções matemáticas, e eventualmente produzem um output do outro lado. A parte da “aprendizagem” é ajustar todos esses números até que os outputs correspondam ao que queres.
Se quiseres ir mais fundo: a rede está organizada em camadas. Cada camada contém “neurónios” (na verdade apenas funções matemáticas). Cada neurónio recebe inputs, multiplica-os por pesos, soma-os, e passa o resultado através de uma função de ativação. A magia acontece porque quando empilhas muitas camadas juntas, a rede consegue aprender padrões incrivelmente complexos - coisas que nenhum humano conseguiria programar à mão.
O termo “neural” vem de uma analogia solta com os neurónios biológicos no cérebro. Não leves isto muito literalmente. Estes sistemas não funcionam nada como cérebros reais. A metáfora foi útil para os investigadores originais nos anos 1940 mas tornou-se algo enganadora.
Treino vs Inferência#
Todo o sistema de IA tem duas fases distintas, e confundi-las causa mal-entendidos intermináveis.
Treino é a parte cara. É quando mostras ao modelo milhões (ou milhares de milhões) de exemplos e ajustas todos aqueles números internos até o modelo ficar bom na sua tarefa. Treinar o GPT-4 custou alegadamente mais de 100 milhões de dólares só em computação. O treino acontece uma vez (ou periodicamente quando queres atualizar o modelo).
Inferência é a parte barata - relativamente falando. É quando realmente usas o modelo treinado. Dás-lhe um input, ele produz um output. Cada vez que conversas com o ChatGPT, estás a fazer inferência. Os números do modelo estão congelados; está apenas a correr cálculos.
Pensa nisto como educação vs. trabalhar. O treino são anos de escola e estudo. A inferência é aparecer no trabalho e usar o que aprendeste. O investimento acontece antecipadamente; o retorno vem durante o uso.
Compreender os LLMs#
O Que Torna os LLMs Especiais#
Large Language Models são um tipo específico de modelo de deep learning treinado para prever texto. Esse é o insight central: no seu âmago, os LLMs estão apenas a tentar prever a próxima palavra (ou token) numa sequência.
“O gato sentou-se no ___” → “tapete” (provavelmente)
Mas aqui está o que é impressionante: quando treinas este objetivo simples em triliões de palavras da internet, livros, código e artigos científicos, algo notável acontece. O modelo não aprende apenas gramática. Aprende factos, padrões de raciocínio, convenções de código, e até algo que parece bom senso.
Isto chama-se comportamento emergente - capacidades que não foram explicitamente treinadas mas surgiram da escala do treino. Ninguém programou o GPT-4 para escrever poesia ou resolver problemas de matemática. Essas capacidades emergiram do objetivo de prever o próximo token muito, muito bem.
Transformers e Atenção#
A arquitetura que tornou os LLMs modernos possíveis chama-se Transformer, introduzida num artigo de 2017 famosamente intitulado “Attention Is All You Need.”
A inovação chave é o mecanismo de atenção. Os modelos anteriores processavam texto sequencialmente - palavra por palavra, da esquerda para a direita. A atenção permite ao modelo olhar para todas as palavras simultaneamente e aprender quais palavras são relevantes umas para as outras.
Exemplo simples: “O animal não atravessou a rua porque ele estava muito cansado.”
A que se refere “ele”? Ao animal. Mas como é que o modelo sabe? O mecanismo de atenção aprende que “ele” deve prestar muita atenção a “animal” e pouca atenção a “rua.” Esta capacidade de capturar dependências de longo alcance é o que torna os Transformers tão poderosos para linguagem.
Tokens e Janelas de Contexto#
Os LLMs não veem realmente palavras - veem tokens. Um token é um pedaço de texto, tipicamente uma palavra ou parte de uma palavra. “Understanding” pode ser um token, enquanto “un” + “derstand” + “ing” podem ser três tokens dependendo do tokenizer do modelo.
Porque é que isto importa? Porque os modelos têm janelas de contexto limitadas - o número máximo de tokens que conseguem processar de uma vez. O GPT-3 inicial tinha um contexto de 4K tokens. O GPT-4 Turbo expandiu para 128K. O Claude consegue lidar com 200K. Alguns modelos mais recentes alegam milhões.
Pensa na janela de contexto como a memória de trabalho do modelo. Tudo o que queres que o modelo considere - a tua pergunta, quaisquer documentos que estejas a partilhar, o histórico da conversa - precisa de caber nesta janela.
| Modelo | Janela de Contexto | Equivalente Aproximado |
|---|---|---|
| GPT-3 (2020) | 4K tokens | ~3.000 palavras |
| GPT-4 Turbo | 128K tokens | ~100.000 palavras |
| Claude 3.5 | 200K tokens | ~150.000 palavras |
| Gemini 1.5 Pro | 1M+ tokens | ~750.000 palavras |
Engenharia de Prompts#
Um prompt é simplesmente o texto que envias a um LLM. A tua pergunta, as tuas instruções, qualquer contexto que forneças - isso tudo faz parte do prompt.
Engenharia de prompts é a arte (e cada vez mais, ciência) de escrever prompts que obtêm melhores resultados. Parece parvo - “engenharia” das tuas perguntas? - mas genuinamente importa.
Algumas técnicas que funcionam:
- Sê específico. “Escreve um poema” vs. “Escreve um soneto de 14 linhas sobre alterações climáticas ao estilo de Shakespeare” - o segundo obtém resultados dramaticamente melhores.
- Mostra exemplos. Dá ao modelo alguns exemplos do que queres antes de pedir o output real. Isto chama-se “few-shot prompting.”
- Pensa passo a passo. Adicionar “Vamos pensar nisto passo a passo” antes de um problema complexo melhora a precisão. Isto chama-se “chain-of-thought” prompting.
- Atribui um papel. “És um contabilista fiscal especialista” foca as respostas do modelo.
Temperatura & Parâmetros#
Quando usas uma API de LLM, podes ajustar vários parâmetros que afetam o output. O mais importante é a temperatura.
A temperatura controla a aleatoriedade. Com temperatura 0, o modelo escolhe sempre o próximo token mais provável - determinístico, previsível, por vezes aborrecido. Com temperatura 1 ou superior, está mais disposto a escolher tokens menos prováveis - mais criativo, mais variado, por vezes sem sentido.
- Temperatura 0: “A capital de França é Paris.”
- Temperatura 1: “A capital de França é Paris, aquela cidade magnífica de luzes onde revolução e romance dançam pelas ruas de calçada…”
Outros parâmetros comuns:
- Top-p (nucleus sampling): Outra forma de controlar aleatoriedade limitando quais tokens são considerados.
- Max tokens: Quão longa pode ser a resposta.
- Sequências de paragem: Diz ao modelo quando parar de gerar.
- Penalidade de frequência/presença: Reduz repetição.
Alucinações#
Os LLMs inventam coisas. Afirmam falsidades com confiança total. Citam artigos que não existem. Inventam estatísticas. Isto chama-se alucinação, e não é um bug que vai ser corrigido - é uma consequência de como estes modelos funcionam.
Lembra-te: os LLMs são treinados para prever texto plausível, não texto verdadeiro. Se perguntares sobre um tópico onde o modelo tem dados de treino limitados, vai gerar algo que soa correto. O modelo não tem verificador de factos interno, nenhuma conexão à verdade fundamental, nenhuma forma de dizer “não sei.”
Porque é que isto acontece?
- Objetivo de treino: Prever o próximo token, não verificar a verdade.
- Distribuição de probabilidade: O modelo amostra de possibilidades. Mesmo que a resposta verdadeira seja mais provável, a amostragem pode escolher outra coisa.
- Sem consciência de corte de conhecimento: O modelo não sabe de forma fiável os limites do seu conhecimento.
Estratégias para reduzir alucinações:
- Usa RAG para fundamentar respostas em documentos reais
- Pede ao modelo para citar fontes e verifica-as
- Baixa a temperatura para tarefas factuais
- Usa outputs estruturados que restringem a resposta
- Implementa camadas de verificação de factos
O Panorama dos Modelos#
Modelos Open vs Closed#
Closed source: Podes usar o modelo via API mas não consegues ver os pesos, modificar a arquitetura, ou corrê-lo tu próprio. GPT-4 da OpenAI, Claude da Anthropic, Gemini da Google.
Open source/open weights: Os pesos estão publicamente disponíveis. Podes descarregá-los, corrê-los localmente, fazer fine-tuning, modificá-los. Llama da Meta, Mistral, Qwen da Alibaba, DeepSeek, e muitos outros.
A distinção é importante mas com nuances:
- “Open weights” significa que podes descarregar e correr o modelo
- “Open source” tradicionalmente significa que o código de treino e os dados também estão disponíveis (raro para modelos grandes)
- As licenças variam - alguns modelos abertos têm restrições comerciais
Porque é que a Meta lança o Llama gratuitamente? Razões estratégicas: comoditizar o complemento, construir ecossistema, atrair talento, definir standards. A visão cínica: não conseguem competir com a OpenAI em receita de API, então competem tornando a camada do modelo gratuita e lucrando noutro lado.
Modelos Multimodais#
Os primeiros LLMs só compreendiam texto. Modelos multimodais compreendem múltiplos tipos de dados - texto, imagens, áudio, vídeo.
O GPT-4V consegue olhar para uma foto e descrevê-la. O Claude consegue analisar gráficos e diagramas. O Gemini consegue ver vídeos. Isto não é apenas novidade - abre casos de uso inteiramente novos:
- Fazer screenshot de um bug e pedir ajuda para depurar
- Carregar um diagrama manuscrito e obter código
- Analisar imagens médicas
- Processar vídeo para moderação de conteúdo
- Interfaces de voz sem speech-to-text separado
As arquiteturas variam. Alguns modelos são treinados nativamente multimodais. Outros conectam modelos de visão e linguagem separados. A distinção importa para o desempenho mas não para a maioria dos utilizadores.
Modelos de Raciocínio#
Os LLMs standard geram respostas token por token sem “pensamento” explícito. Modelos de raciocínio adotam uma abordagem diferente - gastam computação extra a pensar nos problemas antes de responder.
Os modelos o1 e o3 da OpenAI foram pioneiros nesta abordagem. Em vez de responder imediatamente, estes modelos geram cadeias de raciocínio internas (por vezes escondidas dos utilizadores), consideram múltiplas abordagens, e verificam o seu trabalho antes de produzir uma resposta final.
Os resultados são impressionantes: os modelos de raciocínio superam dramaticamente os LLMs standard em matemática, programação, ciência e problemas de lógica. O o3 alcançou pontuações em certos benchmarks que se pensava estarem a anos de distância.
O compromisso: os modelos de raciocínio são mais lentos e mais caros. Uma pergunta simples que o GPT-4 responde instantaneamente pode levar o o1 vários segundos (e 10x o custo) enquanto “pensa.” Para tarefas simples, isso é desperdício. Para problemas difíceis, vale a pena.
Quando usar modelos de raciocínio:
- Problemas complexos de matemática ou lógica
- Desafios de programação multi-passo
- Tarefas que requerem análise cuidadosa
- Qualquer coisa onde a precisão importa mais que a velocidade
Quando os LLMs standard são melhores:
- Q&A simples
- Escrita criativa
- Aplicações em tempo real
- Casos de uso sensíveis ao custo
Produtos de IA para Consumidores#
Antes de mergulhar mais fundo em detalhes técnicos, vamos mapear os produtos que provavelmente já usaste:
ChatGPT (OpenAI) - O produto que iniciou a onda mainstream de IA. Acesso ao GPT-4, o1, DALL-E para imagens, e vários plugins. O benchmark com que todos os outros são comparados.
Claude (Anthropic) - Conhecido pela escrita forte, janelas de contexto longas, e raciocínio matizado. Claude.ai é a interface para consumidores; a API alimenta muitas aplicações.
Gemini (Google) - Profundamente integrado com o ecossistema da Google. Acesso via gemini.google.com e cada vez mais embutido na Pesquisa, Docs, Gmail, e Android.
Copilot (Microsoft) - A camada de IA da Microsoft através dos seus produtos. Diferente do GitHub Copilot (programação) - este é o assistente para consumidores no Windows, Edge, e Microsoft 365.
Perplexity - Motor de pesquisa nativo de IA. Responde a perguntas com citações e fontes. Um vislumbre do que a pesquisa pode tornar-se.
Outros que vale a pena conhecer: Grok (xAI, integrado no X/Twitter), Pi (Inflection), Le Chat (Mistral), DeepSeek Chat, e muitas alternativas regionais/especializadas.
Correr Modelos Localmente#
Porquê Correr Localmente?#
Modelos na cloud correm nos servidores de outra pessoa. Envias pedidos pela internet e pagas por uso. OpenAI, Anthropic, Google - este é o negócio deles.
Modelos locais correm no teu próprio hardware. O teu portátil, os teus servidores, o teu data center. Os dados nunca saem do teu controlo.
Porquê correr localmente?
- Privacidade: Dados sensíveis ficam nas tuas instalações
- Custo: Sem taxas de API (mas o hardware não é grátis)
- Latência: Sem ida e volta pela rede
- Disponibilidade: Funciona offline, sem limites de taxa
- Controlo: Sem termos de serviço, sem filtros de conteúdo que não escolheste
A diferença entre local e cloud diminuiu dramaticamente. Para muitas aplicações práticas, os modelos locais são suficientemente bons - especialmente para tarefas de programação, escrita e análise.
O compromisso: as capacidades de fronteira ainda requerem cloud. Se precisas do melhor desempenho absoluto em tarefas de raciocínio difíceis, GPT-4, Claude, ou Gemini são apenas cloud. Mas essa diferença diminui a cada lançamento.
Ollama#
Ollama tornou-se o standard de facto para correr modelos localmente. Torna o que costumava ser um processo complexo trivialmente fácil.
# Instala e corre um modelo em dois comandos
ollama pull llama3.2
ollama run llama3.2É isso. Estás a conversar com um LLM capaz a correr inteiramente na tua máquina.
O Ollama lida com a complexidade: descarregar modelos, gerir memória, otimizar para o teu hardware, e fornecer tanto uma CLI como uma API local. Suporta dezenas de modelos - Llama, Mistral, Qwen, Phi, CodeLlama, e muitos mais.
Funcionalidades chave:
- Interface CLI simples
- API compatível com OpenAI (fácil de trocar em código existente)
- Biblioteca de modelos com downloads de um comando
- Funciona em Mac, Linux, e Windows
- Aceleração GPU quando disponível
Para programadores, a API local do Ollama significa que podes desenvolver contra modelos locais e mudar para APIs cloud para produção - ou vice-versa - com alterações mínimas de código.
Considerações de Hardware#
Correr modelos localmente requer hardware. Aqui está o que importa:
GPU vs CPU: GPUs aceleram dramaticamente a inferência. Um modelo que demora 30 segundos por resposta em CPU pode demorar 2 segundos em GPU. Os Macs com Apple Silicon esbatam esta linha - a sua memória unificada e Neural Engine tornam-nos surpreendentemente capazes para inferência local.
Memória (VRAM/RAM): Este é normalmente o fator limitante. Os modelos precisam de caber na memória. Um modelo de 7B parâmetros precisa de aproximadamente 4-8GB. Um modelo de 70B precisa de 35-70GB. A quantização (discutida abaixo) reduz estes requisitos.
Quantização: Reduzir a precisão dos pesos do modelo de 32-bit para 16-bit, 8-bit, ou mesmo 4-bit. Isto diminui os requisitos de memória e acelera a inferência com perda mínima de qualidade. A maioria dos modelos locais são distribuídos em formatos quantizados (GGUF, GPTQ, AWQ).
Orientação prática:
- Mac com 16GB+ RAM: Consegue correr modelos 7B-13B confortavelmente
- Mac com 32GB+ RAM: Consegue correr modelos 30B+
- PC com RTX 3090/4090 (24GB VRAM): Consegue correr a maioria dos modelos até 70B (quantizados)
- Sem GPU: Ainda funciona, apenas mais lento. Adequado para desenvolvimento e experimentação.
Personalização e Conhecimento#
Fine-Tuning vs RAG#
Tens um LLM base. Queres torná-lo melhor para o teu caso de uso específico. Duas abordagens principais:
Fine-Tuning#
Pega num modelo existente e continua a treiná-lo com os teus próprios dados. Os pesos do modelo realmente mudam. Após o fine-tuning, o modelo “sabe” a tua informação nativamente.
Prós: Inferência rápida, integração profunda de conhecimento, pode aprender novos estilos ou comportamentos. Contras: Caro, requer experiência em ML, o conhecimento pode ficar desatualizado, risco de esquecimento catastrófico (o modelo fica pior em outras tarefas).
RAG (Retrieval-Augmented Generation)#
Mantém o modelo como está. Quando chega uma pergunta, primeiro pesquisa a tua base de conhecimento por documentos relevantes, depois inclui esses documentos no prompt junto com a pergunta.
Prós: Mais barato, o conhecimento mantém-se atualizado, não requer treino, fácil de auditar (podes ver o que foi recuperado). Contras: Mais lento (processo de dois passos), limitado pela janela de contexto, a qualidade da recuperação importa muito.
Embeddings & Vector DBs#
Esta é a tecnologia que faz o RAG funcionar - e é genuinamente inteligente.
Um embedding é uma forma de representar texto (ou imagens, ou qualquer coisa) como uma lista de números - um vetor. A magia: coisas semelhantes têm vetores semelhantes. “Cão” e “cachorro” têm vetores que estão próximos. “Cão” e “democracia” estão distantes.
Crias embeddings usando modelos de embedding (diferentes dos LLMs, embora alguns LLMs tenham capacidades de embedding). OpenAI, Cohere, Voyage, e muitos outros oferecem APIs de embedding. Opções open source como BGE e E5 também funcionam muito bem.
Uma base de dados vetorial é uma base de dados otimizada para armazenar e pesquisar estes vetores. Quando perguntas “Qual é a nossa política de reembolso?”, o sistema:
- Converte a tua pergunta num vetor
- Pesquisa a base de dados vetorial por vetores semelhantes
- Devolve os documentos que esses vetores representam
- Alimenta esses documentos ao LLM com a tua pergunta
Bases de dados vetoriais populares incluem Pinecone, Weaviate, Chroma, Qdrant, e Milvus. Postgres com pgvector funciona surpreendentemente bem para muitos casos de uso.
Avaliação#
Benchmarks#
Como sabes se um modelo é “melhor” que outro? Os benchmarks tentam responder a isto testando modelos em tarefas padronizadas.
Benchmarks comuns:
- MMLU (Massive Multitask Language Understanding): Perguntas de escolha múltipla em 57 assuntos. Testa conhecimento geral.
- HumanEval: Problemas de programação. Testa capacidade de programação.
- GSM8K: Problemas de matemática do ensino básico. Testa raciocínio matemático.
- HellaSwag: Raciocínio de senso comum sobre situações quotidianas.
- TruthfulQA: Testa se os modelos dão respostas verdadeiras vs. disparates que soam convincentes.
O problema com benchmarks: São manipuláveis. Os modelos podem ser treinados especificamente para ter bom desempenho em benchmarks populares sem realmente melhorar em tarefas reais. Um modelo que pontua 90% no MMLU pode ainda falhar no teu caso de uso específico.
Evals#
Evals (avaliações) são testes que crias para o teu caso de uso específico. Ao contrário dos benchmarks, os evals medem o que realmente importa para a tua aplicação.
A construir um bot de serviço ao cliente? Os teus evals podem testar:
- Responde corretamente a perguntas do teu FAQ?
- Escala apropriadamente para humanos quando necessário?
- Mantém-se dentro da marca e segue as tuas diretrizes de tom?
- Recusa fazer promessas que a empresa não pode cumprir?
Porque é que os evals importam:
- Deteção de regressão: Quando mudas prompts ou trocas modelos, os evals apanham problemas antes dos utilizadores.
- Comparação: Compara objetivamente diferentes modelos, prompts, ou abordagens para o teu caso de uso.
- Iteração: Não podes melhorar o que não podes medir. Os evals tornam a melhoria sistemática.
Construir bons evals:
- Começa com queries reais de utilizadores e respostas esperadas
- Inclui casos extremos e exemplos adversários
- Testa tanto o que o modelo deve fazer COMO o que não deve
- Automatiza para poderes correr evals em cada mudança
LLM como Juiz#
Aqui está uma técnica inteligente: usar um LLM para avaliar os outputs de outro LLM.
Em vez de rever manualmente centenas de respostas, podes dar um prompt a um modelo para agir como juiz:
Estás a avaliar a qualidade da resposta de um assistente de IA.
Pergunta do utilizador: {question}
Resposta do assistente: {response}
Avalia a resposta em:
1. Precisão (1-5): A informação está correta?
2. Utilidade (1-5): Ajuda realmente o utilizador?
3. Clareza (1-5): É fácil de compreender?
Explica o teu raciocínio, depois fornece pontuações.Porque é que isto funciona:
- Escala para milhares de avaliações
- Mais consistente que revisores humanos (menos fadiga)
- Consegue avaliar qualidades subtis que são difíceis de testar programaticamente
- Mais barato e mais rápido que avaliação humana
Limitações:
- O modelo juiz tem os seus próprios vieses e limitações
- Pode não detetar erros que ele próprio cometeria
- Tem dificuldade com precisão específica de domínio sem fundamentação
- Não é um substituto total para avaliação humana - mais um complemento
Agentes e Automação#
O Que São Agentes?#
O termo “agente” é muito usado. Aqui está uma definição funcional: um agente é um LLM que pode tomar ações no mundo, não apenas gerar texto.
Um chatbot responde às tuas perguntas. Um agente pode responder às tuas perguntas e fazer uma reserva de restaurante, enviar um email, consultar uma base de dados, ou escrever e executar código para resolver um problema.
O que torna algo um agente vs. apenas um LLM?
- Objetivos: Os agentes trabalham para objetivos, não apenas respondem a prompts.
- Ações: Os agentes podem fazer coisas, não apenas dizer coisas.
- Autonomia: Os agentes tomam decisões sobre como alcançar objetivos.
- Ciclos: Os agentes frequentemente correm em ciclos - observar, pensar, agir, repetir.
O padrão de agente mais simples: dar a um LLM acesso a ferramentas e deixá-lo decidir quais ferramentas usar. “Encontra voos de Londres para Tóquio na próxima semana, verifica o meu calendário, e reserva a opção mais barata que funcione com a minha agenda.” O agente decompõe isto, chama APIs de voos, chama APIs de calendário, e executa a reserva.
Agentes vs Fluxos de Trabalho#
Uma distinção importante que frequentemente fica esbatida:
Fluxos de trabalho são determinísticos. Defines os passos: primeiro faz A, depois faz B, depois se X faz C senão faz D. O LLM pode alimentar passos individuais, mas a orquestração está codificada.
1. Extrair entidades do email (LLM)
2. Procurar cliente na base de dados (código)
3. Gerar rascunho de resposta (LLM)
4. Enviar para revisão humana (código)Agentes são autónomos. Dás-lhes um objetivo e ferramentas, e eles descobrem os passos. O LLM decide o que fazer a seguir com base no estado atual.
Objetivo: "Resolver esta reclamação de cliente"
Ferramentas: [email, base_dados, sistema_reembolso, escalamento]
→ O agente decide o que fazer, em que ordemQuando usar fluxos de trabalho:
- Processos previsíveis e bem compreendidos
- Quando precisas de fiabilidade e auditabilidade
- Ambientes regulados
- Tarefas de alto volume e baixa complexidade
Quando usar agentes:
- Tarefas novas ou variáveis
- Quando os passos não são conhecidos antecipadamente
- Raciocínio complexo necessário
- Quando a flexibilidade importa mais que a previsibilidade
A equação de custos: Os fluxos de trabalho são significativamente mais baratos. Pagas por um número fixo de chamadas LLM por execução - previsível, otimizável, auditável. Os agentes são caros porque pensam. Cada ponto de decisão - “que ferramenta devo usar?”, “isso funcionou?”, “qual é o próximo passo?” - é uma chamada LLM. Um fluxo de trabalho que faz 3 chamadas LLM pode tornar-se um agente que faz 15-30 chamadas para resolver o mesmo problema, porque o agente está a raciocinar sobre como resolvê-lo, não apenas a executar passos predefinidos. Para tarefas bem compreendidas em escala, os fluxos de trabalho ganham em custo. Para problemas complexos e variáveis onde não consegues predefinir os passos, os agentes valem o prémio.
Uso de Ferramentas & Chamada de Funções#
Para os agentes tomarem ações, precisam de ferramentas - funções que podem chamar. Esta capacidade é normalmente chamada function calling ou tool use.
Aqui está como funciona:
- Defines ferramentas com nomes, descrições e parâmetros (normalmente como esquemas JSON)
- Incluis estas definições no teu prompt/chamada API
- O modelo pode escolher “chamar” uma ferramenta em vez de gerar texto
- O teu código executa a função e devolve resultados ao modelo
- O modelo usa esses resultados para continuar
Exemplo de definição de ferramenta:
{
"name": "get_weather",
"description": "Obter tempo atual para uma cidade",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "Nome da cidade"},
"units": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["city"]
}
}Quando perguntas “Como está o tempo em Tóquio?”, o modelo não alucina - chama get_weather(city="Tokyo"), obtém dados reais, e responde com factos.
Todos os principais fornecedores de modelos suportam agora function calling: OpenAI, Anthropic, Google, e outros. A sintaxe varia ligeiramente mas o conceito é o mesmo.
Protocolo MCP#
Model Context Protocol (MCP) é um standard aberto para conectar modelos de IA a ferramentas e fontes de dados. Pensa nisto como USB-C para IA - um conector universal que significa que não precisas de um cabo diferente para cada dispositivo.
Antes do MCP, cada integração era personalizada. Queres que a tua IA aceda ao GitHub? Escreve uma integração GitHub. Salesforce? Outra integração. A tua base de dados interna? Mais outra. Isto não escala.
O MCP define uma forma standard para clientes de IA (como Claude, ChatGPT, ou o teu agente personalizado) descobrirem e usarem ferramentas de servidores MCP. Um servidor MCP pode expor:
- Ferramentas: Funções que a IA pode chamar
- Recursos: Dados que a IA pode ler
- Prompts: Templates para tarefas comuns
As implicações são significativas:
- Constrói um servidor MCP uma vez, toda a IA compatível pode usá-lo
- As ferramentas tornam-se portáteis e reutilizáveis
- Segurança e permissões podem ser padronizadas
- O ecossistema multiplica-se - mais servidores significa agentes mais capazes
Para mais sobre MCP, escrevi um aprofundamento: MCP Servers: The USB-C Moment for AI Agents.
Padrões Agênticos#
À medida que os agentes amadureceram, padrões comuns emergiram:
ReAct (Reason + Act): O agente alterna entre raciocinar (“Preciso de encontrar o histórico de encomendas do utilizador”) e agir (chamar a API de encomendas). Este passo de raciocínio explícito melhora a fiabilidade.
Planeamento: Antes de agir, o agente cria um plano: “Para resolver isto, vou precisar de 1) procurar a encomenda, 2) verificar inventário, 3) processar o reembolso, 4) enviar confirmação.” Os planos podem ser validados antes da execução.
Reflexão: Após completar uma tarefa (ou falhar), o agente revê o que aconteceu: “O reembolso falhou porque a encomenda era muito antiga. Devia ter verificado a política de reembolso primeiro.” Isto permite aprendizagem e auto-correção.
Seleção de ferramentas: Quando um agente tem muitas ferramentas, escolher a certa torna-se não-trivial. As técnicas incluem descrições de ferramentas, exemplos few-shot, e organização hierárquica de ferramentas.
Humano no ciclo: Para ações de alto risco, os agentes podem pausar e pedir aprovação humana antes de prosseguir. Bons agentes sabem quando estão incertos.
Skills#
Skills são prompts especializados e reutilizáveis que estendem o que um agente consegue fazer. Pensa nelas como “modos especializados” que podes ligar a um agente - uma skill para revisão de código, uma skill para escrever documentação, uma skill para analisar vulnerabilidades de segurança.
Ao contrário das ferramentas (que são funções que fazem coisas), as skills são instruções que moldam como o agente pensa e responde. Uma ferramenta chama uma API. Uma skill diz ao agente “quando te perguntarem sobre X, aborda desta forma, considera estes fatores, e formata a tua resposta assim.”
Porque é que as skills importam:
- Especialização sem fine-tuning: Obténs comportamento especializado sem treinar um novo modelo.
- Composabilidade: Mistura e combina skills para diferentes tarefas.
- Partilhabilidade: Uma skill bem elaborada pode ser usada entre equipas, projetos, ou até partilhada publicamente.
- Eficiência de contexto: Em vez de explicar os teus requisitos sempre, codifica-os uma vez numa skill.
Onde vivem as skills:
As skills podem ser injetadas em diferentes pontos do contexto do agente:
- Prompt de sistema: A abordagem mais comum. As skills tornam-se parte das instruções base do agente, sempre ativas.
- Prefixo da mensagem do utilizador: Adicionado dinamicamente aos pedidos do utilizador. Útil para skills específicas de tarefas.
- Descrições de ferramentas: As skills podem ser embutidas nas definições de ferramentas, guiando como o agente usa ferramentas específicas.
- Prompts MCP: Os servidores MCP podem expor skills como “prompts” - templates reutilizáveis que os clientes podem descobrir e invocar.
Como as skills influenciam o contexto:
Cada skill consome tokens da tua janela de contexto. Isto cria compromissos:
- Mais skills = agente mais capaz, mas menos espaço para histórico de conversa
- Skills detalhadas = melhor comportamento, mas custo de tokens mais alto por pedido
- Skills sempre ativas vs. skills a pedido = fiabilidade vs. eficiência
Frameworks de agentes inteligentes gerem isto carregando skills dinamicamente - ativando skills relevantes com base na tarefa e desativando outras.
Exemplo de estrutura de skill:
## Skill de Revisão de Código
Ao rever código, deves:
1. Verificar vulnerabilidades de segurança (injeção, XSS, problemas de autenticação)
2. Identificar preocupações de desempenho
3. Avaliar legibilidade e manutenibilidade
4. Sugerir melhorias específicas com exemplos de código
Formata a tua revisão como:
- Resumo (1-2 frases)
- Problemas críticos (se houver)
- Sugestões (lista com marcadores)
- Avaliação geralAgentes de Código#
Porque Importam#
Os agentes de código representam uma das aplicações mais tangíveis de IA - eles realmente escrevem código, e o código realmente funciona. Isto não é teórico; os programadores estão a entregar funcionalidades mais rapidamente por causa destas ferramentas.
O impacto é imediato e mensurável: menos tempo em código boilerplate, depuração mais rápida, exploração mais fácil de codebases desconhecidas. Para muitos programadores, os agentes de código tornaram-se tão essenciais como o seu IDE.
O Panorama#
Claude Code - O agente de código baseado em terminal da Anthropic. Vive na tua CLI, compreende toda a tua codebase, consegue ler ficheiros, escrever código, correr comandos, e iterar com base em feedback. Desenhado para programadores que vivem no terminal.
Cursor - Um IDE nativo de IA construído desde o início à volta de assistência de IA. Não é apenas autocomplete - podes conversar com a tua codebase, gerar funcionalidades inteiras, e ter a IA a fazer mudanças abrangentes em ficheiros. A coisa mais próxima de pair programming com uma IA.
GitHub Copilot - O original e mais amplamente implementado. Começou como autocomplete, evoluiu para chat, agora inclui Copilot Workspace para tarefas maiores. Integração profunda com GitHub.
Windsurf - O IDE de IA da Codeium, posicionando-se como alternativa ao Cursor. Forte ênfase em velocidade e compreensão de codebases grandes.
Cody (Sourcegraph) - Foca-se na compreensão de codebases. Particularmente forte para codebases grandes e complexas onde o contexto é crítico.
Continue - Assistente de código open-source que funciona com qualquer IDE. Traz o teu próprio modelo (local ou cloud). Bom para equipas que querem controlo sobre a sua configuração de IA.
OpenCode - Alternativa open-source ao Claude Code. Baseado em terminal, agnóstico de modelo, desenvolvimento impulsionado pela comunidade.
Aider - Outro excelente agente de código terminal open-source. Conhecido pela sua integração com git e capacidade de trabalhar com múltiplos ficheiros de forma coerente.
Próximos Passos#
Passaste pelos fundamentos. E agora?
Construir Coisas#
- Começa simples. Usa uma API (OpenAI, Anthropic, etc.) e constrói um chatbot básico ou sistema RAG. Não penses demasiado na stack inicialmente.
- Experimenta modelos locais. Instala Ollama e corre Llama ou Qwen no teu portátil. É surpreendentemente fácil.
- Explora agentes. Vê frameworks como LangChain, LlamaIndex, ou CrewAI para construir sistemas de agentes.
- Aprende MCP. A documentação oficial é sólida. Experimenta correr alguns servidores MCP localmente.
- Constrói evals cedo. O que quer que construas, cria evals desde o primeiro dia. Vais agradecer-te mais tarde.
Compreender o Campo#
- Segue a investigação. Artigos ArXiv, alertas Google Scholar sobre tópicos que te interessam.
- Lê o hype criticamente. A maioria dos “avanços” são incrementais. Procura resultados reproduzíveis e benchmarks reais.
- Experimenta tu próprio. A intuição sobre o que funciona vem da experiência prática, não da leitura.
Recursos#
- Hugging Face - Modelos, datasets, e uma comunidade incrível
- Papers With Code - Artigos de investigação com implementações
- Ollama - Execução de modelos locais super simples
- LangChain / LlamaIndex - Frameworks populares para construir com LLMs
- Model Context Protocol - A especificação MCP e SDKs
- Chatbot Arena - Compara modelos frente-a-frente com votação humana
A IA em 2026 é simultaneamente sobrevalorizada e subvalorizada. A tecnologia é genuinamente transformadora - mas também é genuinamente limitada. Os LLMs inventam coisas. Os agentes são frágeis. Os custos são altos. O progresso é rápido mas desigual.
A melhor abordagem é pragmática: compreende os fundamentos, experimenta com problemas reais, mantém-te cético em relação a grandes afirmações, e constrói coisas. As pessoas que vão prosperar nesta era não são as que conseguem recitar cada acrónimo - são as que conseguem entregar produtos que realmente funcionam.
Agora vai construir algo.





