Dia 16. E se o adversário IA realmente aprendesse com as derrotas contra ti?
Não um algoritmo minimax que joga na perfeição desde o início. Não um jogador aleatório. Algo que começa burro, observa o que funciona e gradualmente descobre como te vencer. Isso é Q-learning. E foi isso que eu quis construir no jogo mais simples possível.
O Prompt#
“Constrói um jogo do galo com uma IA de Q-learning que aprende com cada jogo, persiste o seu cérebro no localStorage e mostra estatísticas em tempo real”
Como Foi Construído#
O Watchfire dividiu isto em 4 tarefas:
- Estrutura base do projeto Next.js com o tabuleiro de jogo e layout básico
- IA de Q-learning com estratégia epsilon-greedy e persistência da Q-table no localStorage
- Dashboard de estatísticas, visualização do cérebro da IA e modo de treino para jogos em massa contra si própria
- Modos de dificuldade, destaque de jogadas vencedoras, efeitos sonoros e polimento final
A primeira tarefa deu-me um jogo do galo jogável. Nada de especial. A segunda tarefa é onde as coisas ficaram interessantes, porque agora a IA estava de facto a atualizar valores de estado-ação após cada jogo. Ganha um jogo contra ela e ela ajusta-se. Vence-a da mesma maneira duas vezes e ela começa a bloquear essa jogada. A Q-table cresce a cada partida.
As tarefas 3 e 4 transformaram isto de uma experiência de aprendizagem em algo que podes realmente ver a evoluir. A visualização do cérebro mostra os Q-values para cada célula, o dashboard de estatísticas acompanha as taxas de vitória/derrota/empate ao longo do tempo, e o modo de treino permite correr milhares de jogos de auto-aprendizagem para acelerar a educação da IA.
O Que Obtive#
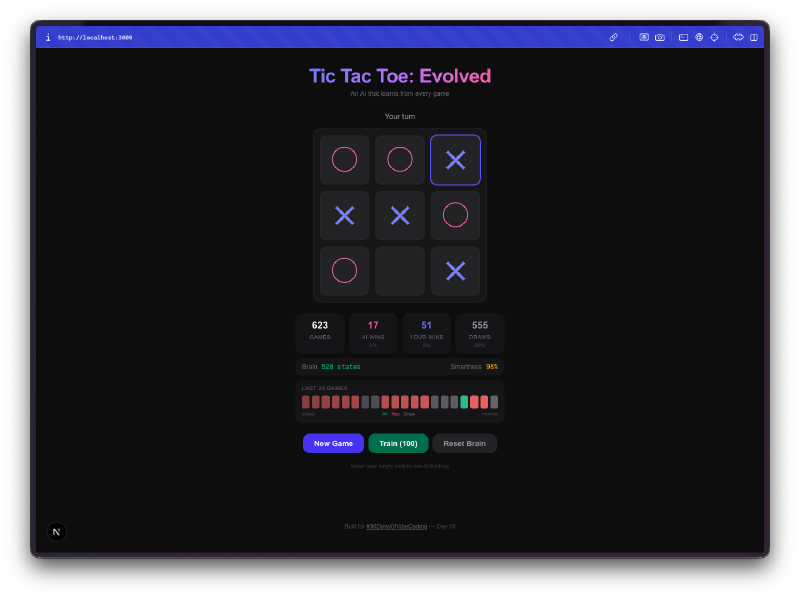
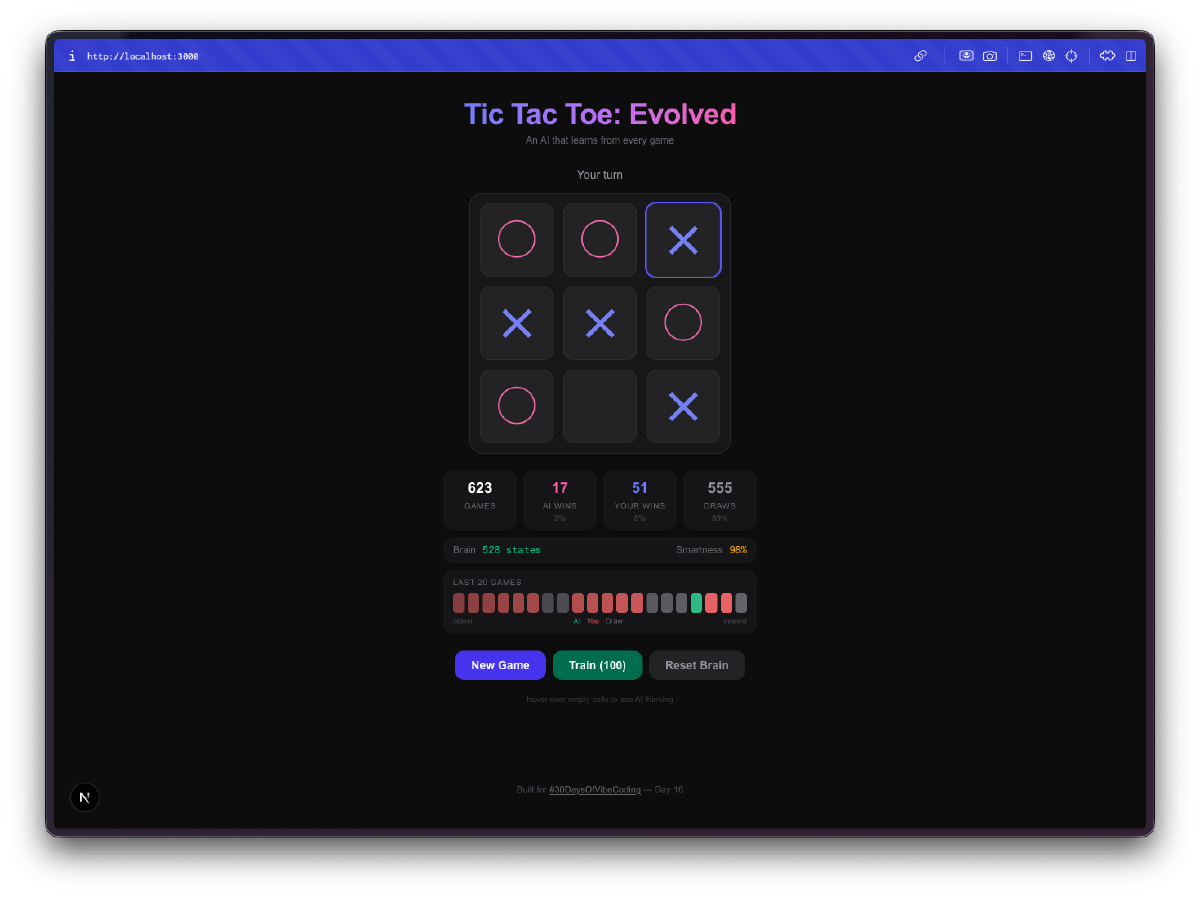
A IA começa horrível. Nos teus primeiros jogos, ela joga quase aleatoriamente. Escolhe quadrados sem estratégia, cai nas mesmas armadilhas, perde de formas óbvias. É esse o objetivo. Está a explorar o espaço do jogo, a tentar jogadas que nunca tentou antes, a construir a sua Q-table do zero.
Depois deixa de ser horrível. Algures entre 50 a 100 jogos, notas que ela bloqueia as tuas jogadas vencedoras. Após algumas centenas de jogos, empata consistentemente. Treina-a com alguns milhares de jogos de auto-aprendizagem e boa sorte a tentar ganhar. A progressão de incompetente para competente é genuinamente divertida de observar.
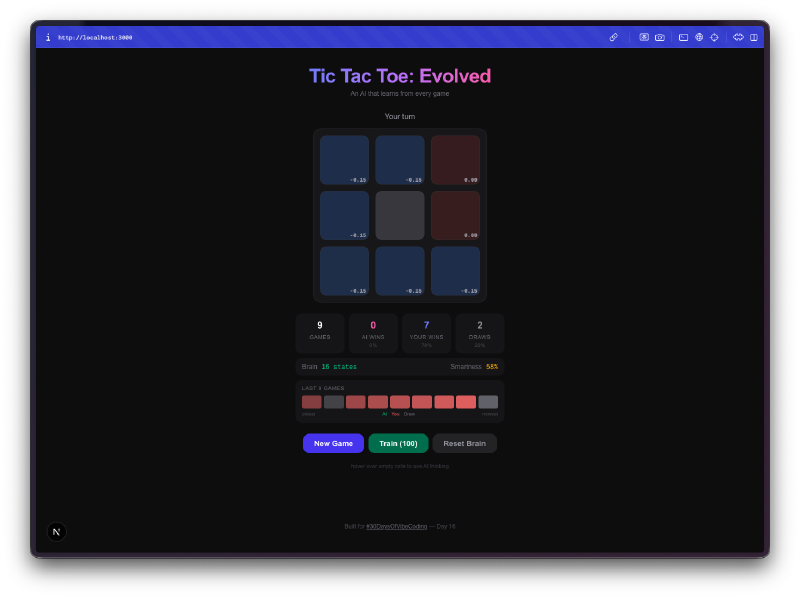
A visualização do cérebro é a melhor parte. Podes passar o rato sobre as células e ver os Q-values que a IA aprendeu para cada posição. Valores positivos altos significam que a IA acha que aquela jogada leva a uma vitória. Valores negativos significam que aprendeu a evitar aquele quadrado no estado atual. Estás literalmente a olhar para a compreensão que a IA tem do jogo, e podes ver esses números a mudar à medida que ela joga mais.
O treino em massa é viciante. Há um modo de treino onde podes correr 100, 1.000 ou 10.000 jogos de auto-aprendizagem. A IA joga contra si própria, aprendendo de ambos os lados. Podes ver o tamanho da Q-table a crescer em tempo real à medida que descobre novos estados do tabuleiro. Após 10.000 jogos, o cérebro já viu milhares de posições únicas e tem uma opinião forte sobre cada uma delas.
Tudo persiste. Fecha o separador, volta amanhã, e a IA lembra-se de tudo o que aprendeu. A Q-table, as estatísticas dos jogos, o historial de séries de vitórias. Está tudo guardado no localStorage. O teu adversário IA tem memória permanente, o que significa que quanto mais jogares contra ela ao longo de dias e semanas, melhor ela fica.
Os modos de dificuldade alteram a taxa de exploração. O modo fácil mantém o epsilon (aleatoriedade) alto para que a IA cometa mais erros. O modo difícil reduz o epsilon para que ela quase sempre escolha a jogada que acha melhor. Isto permite-te controlar o quanto a IA se baseia no que aprendeu versus tentar coisas novas.
Os pequenos detalhes importam. As linhas vencedoras ficam destacadas. Efeitos sonoros tocam em jogadas, vitórias, derrotas e empates. Há um historial de jogos recentes a mostrar os teus últimos 20 resultados como um tracker visual de séries. O conjunto todo parece um jogo a sério, não apenas uma demo técnica.
Os Números#
- 4 tarefas no Watchfire da estrutura base ao polimento
- A Q-table cresce para milhares de entradas após treino em massa
- 3 modos de dificuldade a controlar o tradeoff exploração/exploitação
- Persistência total no localStorage para o cérebro da IA e todas as estatísticas
- 0 estratégia hardcoded na IA. Tudo o que sabe, aprendeu
Experimenta#
Joga algumas rondas e vê a IA a melhorar. Ou carrega no botão de treino e deixa-a ensinar-se a si própria.
Veredito do Dia 16#
O jogo do galo é um jogo resolvido. Qualquer jogador perfeito consegue forçar um empate sempre. É exatamente isso que o torna um ótimo campo de testes para aprendizagem por reforço. O jogo é simples o suficiente para que a IA consiga explorar todo o espaço de estados num número razoável de jogos, e podes realmente vê-la a convergir para a jogada ótima.
O que eu gosto neste projeto é que torna o machine learning tangível. Não estás a ler sobre Q-learning num livro de texto ou a ver curvas de loss de treino num Jupyter notebook. Estás a jogar contra uma IA que está visivelmente a ficar mais esperta. Podes ver os seus Q-values, observar o seu cérebro a crescer e sentir a diferença entre jogar contra ela no jogo 10 versus no jogo 10.000.
O facto de tudo correr no browser sem backend, sem Python, sem TensorFlow, apenas TypeScript e localStorage, faz com que pareça acessível. O Q-learning é um dos algoritmos de aprendizagem por reforço mais simples, mas vê-lo a funcionar em tempo real num jogo que já compreendes faz com que o conceito faça clique de uma forma que a teoria sozinha nunca consegue.
Este é o dia 16 de 30 Days of Vibe Coding. Acompanha-me enquanto lanço 30 projetos em 30 dias usando programação assistida por IA.