让我们从头开始,循序渐进。
基础概念#
AI vs ML vs 深度学习#
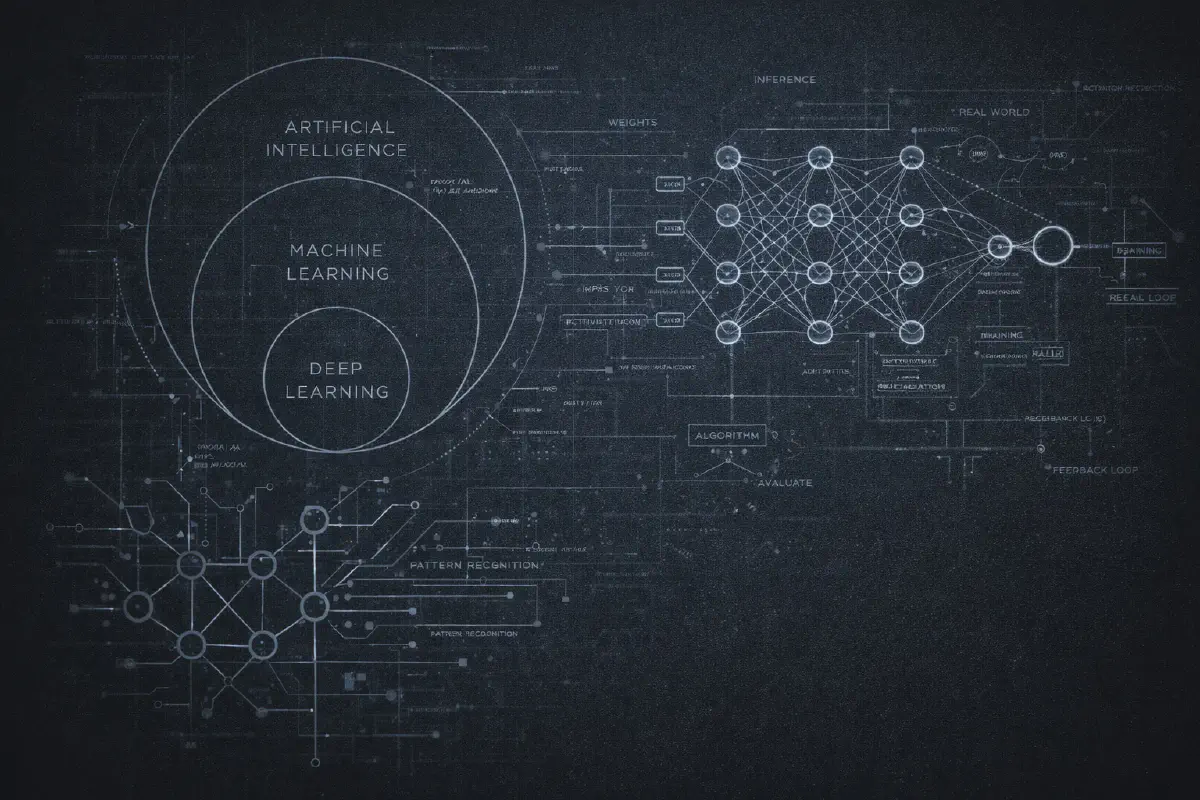
你可能见过这张图:三个同心圆,最外层是 AI,中间是机器学习(Machine Learning),核心是深度学习(Deep Learning)。这图已经成了老生常谈,但对理解这些术语之间的关系确实很有用。
人工智能(Artificial Intelligence) 是最宽泛的术语。它的意思就是"让计算机做那些如果人来做需要智能的事情"。就这么简单。1970 年代的国际象棋程序?AI。你的垃圾邮件过滤器?AI。一个简单的 if-else 规则决定是否给你弹窗?技术上说,也是 AI。这个术语太宽泛了,单独使用几乎没什么意义。
机器学习(Machine Learning) 是 AI 的一个子集,它不是编写明确的规则,而是给计算机提供示例,让它自己找出规律。不是写"如果邮件包含’尼日利亚王子’,标记为垃圾邮件",而是给它看 10000 封标记为"垃圾邮件"或"非垃圾邮件"的邮件,让算法学习什么让垃圾邮件……像垃圾邮件。
深度学习(Deep Learning) 是机器学习的一个子集,它使用多层神经网络(所以叫"深度")。这是 2010 年代事情开始变得有趣的地方。深度学习在图像识别、语音识别方面取得了突破,最终催生了我们现在都在关注的语言模型。
神经网络#
这里有个不完美但有用的类比:神经网络就像一个非常复杂的电子表格,里面有数百万个可调整的数字。
数据从一边输入。它被这些数字相乘、相加、通过一些数学函数,最终在另一边产生输出。“学习"的过程就是调整所有这些数字,直到输出符合你想要的结果。
如果你想深入了解:网络被组织成层。每一层包含"神经元”(实际上就是数学函数)。每个神经元接收输入,乘以权重,加起来,然后通过激活函数传递结果。神奇的地方在于,当你把很多层堆叠在一起时,网络可以学习极其复杂的模式——这些是人类无法手工编程的。
“神经"这个词来自于与大脑中生物神经元的松散类比。不要太当真。这些系统的工作方式与真正的大脑完全不同。这个比喻对 1940 年代的原始研究人员很有用,但现在有些误导。
Training vs Inference#
每个 AI 系统都有两个截然不同的阶段,混淆它们会导致无尽的误解。
训练(Training) 是昂贵的部分。这是你向模型展示数百万(或数十亿)个示例并调整所有内部数字直到模型擅长其任务的阶段。据报道,训练 GPT-4 仅计算成本就超过 1 亿美元。训练只发生一次(或在你想更新模型时定期进行)。
推理(Inference) 是相对便宜的部分。这是你实际使用训练好的模型的时候。你给它一个输入,它产生一个输出。每次你与 ChatGPT 聊天,你都在进行推理。模型的数字是固定的;它只是在运行计算。
把它想象成教育与工作。训练是多年的学校和学习。推理是去上班并使用你学到的东西。投资发生在前期;回报在使用期间产生。
理解 LLM(大语言模型)#
LLM 的特别之处#
大语言模型(Large Language Models)是一种特定类型的深度学习模型,被训练来预测文本。这是核心洞察:从本质上讲,LLM 只是试图预测序列中的下一个词(或 token)。
“猫坐在___上” → “垫子”(大概率)
但这里有个疯狂的地方:当你用互联网、书籍、代码和科学论文上的数万亿个词来训练这个简单的目标时,神奇的事情发生了。模型不仅学会了语法。它学会了事实、推理模式、编码规范,甚至是看起来像常识的东西。
这被称为涌现行为(emergent behavior)——没有明确训练但从训练规模中产生的能力。没有人编程让 GPT-4 写诗或解数学题。这些能力是从非常非常好地预测下一个 token 的目标中涌现的。
Transformer 和注意力机制#
使现代 LLM 成为可能的架构叫做 Transformer,在 2017 年一篇著名的论文"Attention Is All You Need"中被介绍。
关键创新是注意力机制(attention mechanism)。以前的模型按顺序处理文本——一个词一个词,从左到右。注意力允许模型同时查看所有词,并学习哪些词彼此相关。
简单例子:“这只动物没有过马路,因为它太累了。”
“它"指的是什么?动物。但模型怎么知道的?注意力机制学会了"它"应该强烈关注"动物”,而弱关注"马路”。这种捕捉长距离依赖关系的能力是 Transformer 在语言方面如此强大的原因。
Token 和上下文窗口#
LLM 实际上看不到词——它们看到的是 token。Token 是一段文本,通常是一个词或词的一部分。“Understanding"可能是一个 token,而"un” + “derstand” + “ing"根据模型的分词器可能是三个 token。
为什么这很重要?因为模型有有限的上下文窗口(context window)——它们一次能处理的最大 token 数量。早期的 GPT-3 有 4K token 的上下文。GPT-4 Turbo 扩展到 128K。Claude 可以处理 200K。一些较新的模型声称可以处理数百万。
把上下文窗口想象成模型的工作记忆。你想让模型考虑的一切——你的问题、你分享的任何文档、对话历史——都需要放进这个窗口。
| 模型 | 上下文窗口 | 大致相当于 |
|---|---|---|
| GPT-3 (2020) | 4K tokens | ~3,000 词 |
| GPT-4 Turbo | 128K tokens | ~100,000 词 |
| Claude 3.5 | 200K tokens | ~150,000 词 |
| Gemini 1.5 Pro | 1M+ tokens | ~750,000 词 |
提示工程#
提示词(prompt) 就是你发送给 LLM 的文本。你的问题、你的指令、你提供的任何上下文——这些都是提示词的一部分。
提示工程(prompt engineering) 是编写能获得更好结果的提示词的艺术(以及越来越多的科学)。这听起来很傻——“工程"你的问题?——但它确实很重要。
一些有效的技巧:
- 具体化。 “写一首诗” vs “写一首关于气候变化的14行莎士比亚风格十四行诗”——第二个会得到明显更好的结果。
- 展示示例。 在要求实际输出之前,给模型几个你想要的示例。这叫"少样本提示(few-shot prompting)"。
- 逐步思考。 在复杂问题前添加"让我们逐步思考这个问题"可以提高准确性。这叫"思维链(chain-of-thought)“提示。
- 分配角色。 “你是一位专业的税务会计师"可以使模型的回答更加聚焦。
Temperature 和参数#
当你使用 LLM API 时,你可以调整几个影响输出的参数。最重要的是 temperature。
Temperature 控制随机性。在 temperature 0 时,模型总是选择最可能的下一个 token——确定性的、可预测的、有时无聊的。在 temperature 1 或更高时,它更愿意选择不太可能的 token——更有创意、更多样化、有时是胡说八道。
- Temperature 0: “法国的首都是巴黎。”
- Temperature 1: “法国的首都是巴黎,那座光之城,革命与浪漫在鹅卵石街道上共舞…”
其他常见参数:
- Top-p(核采样): 另一种控制随机性的方式,通过限制考虑哪些 token。
- Max tokens: 响应可以有多长。
- Stop sequences: 告诉模型何时停止生成。
- Frequency/presence penalty: 减少重复。
幻觉#
LLM 会编造东西。它们以完全的自信陈述错误。它们引用不存在的论文。它们发明统计数据。这被称为幻觉(hallucination),这不是会被修复的 bug——这是这些模型工作方式的结果。
记住:LLM 被训练来预测看起来合理的文本,而不是真实的文本。如果你询问一个模型训练数据有限的话题,它会生成一些听起来正确的东西。模型没有内部事实检查器,没有与真相的连接,没有办法说"我不知道”。
为什么会发生这种情况?
- 训练目标: 预测下一个 token,而不是验证真相。
- 概率分布: 模型从可能性中采样。即使真正的答案最有可能,采样也可能选择其他东西。
- 没有知识截止意识: 模型不能可靠地知道其知识的边界。
减少幻觉的策略:
- 使用 RAG 将响应建立在实际文档上
- 要求模型引用来源并验证它们
- 对事实性任务降低 temperature
- 使用约束响应的结构化输出
- 实施事实检查层
模型版图#
开源 vs 闭源模型#
闭源: 你可以通过 API 使用模型,但看不到权重、不能修改架构、也不能自己运行。OpenAI 的 GPT-4、Anthropic 的 Claude、Google 的 Gemini。
开源/开放权重: 权重是公开可用的。你可以下载它们、本地运行、微调、修改。Meta 的 Llama、Mistral、阿里巴巴的 Qwen、DeepSeek 等等。
这个区别很重要但有细微差别:
- “开放权重"意味着你可以下载并运行模型
- “开源"传统上意味着训练代码和数据也可用(对于大模型来说很少见)
- 许可证各不相同——一些开放模型有商业限制
为什么 Meta 免费发布 Llama?战略原因:使互补品商品化、建立生态系统、吸引人才、设定标准。愤世嫉俗的观点:他们无法在 API 收入上与 OpenAI 竞争,所以他们通过免费提供模型层并在其他地方获利来竞争。
多模态模型#
早期的 LLM 只理解文本。多模态模型(multimodal models) 理解多种类型的数据——文本、图像、音频、视频。
GPT-4V 可以看照片并描述它。Claude 可以分析图表和图形。Gemini 可以观看视频。这不仅仅是新奇——它开启了全新的用例:
- 截图一个 bug 并寻求调试帮助
- 上传手写图表并获取代码
- 分析医学图像
- 处理视频以进行内容审核
- 无需单独语音转文本的语音界面
架构各不相同。一些模型是原生多模态训练的。其他的连接单独的视觉和语言模型。这个区别对性能很重要,但对大多数用户不重要。
推理模型#
标准 LLM 逐 token 生成响应,没有明确的"思考”。推理模型(reasoning models) 采用不同的方法——它们在回答之前花费额外的计算来思考问题。
OpenAI 的 o1 和 o3 模型开创了这种方法。这些模型不是立即响应,而是生成内部推理链(有时对用户隐藏),考虑多种方法,并在产生最终答案之前检查自己的工作。
结果令人瞩目:推理模型在数学、编程、科学和逻辑问题上大大超越标准 LLM。o3 在某些基准测试上取得的分数被认为还需要数年才能实现。
权衡:推理模型更慢、更贵。GPT-4 立即回答的简单问题可能需要 o1 几秒钟(和 10 倍的成本)来"思考”。对于简单任务,这是浪费。对于困难问题,这是值得的。
何时使用推理模型:
- 复杂的数学或逻辑问题
- 多步骤编程挑战
- 需要仔细分析的任务
- 任何准确性比速度更重要的事情
何时标准 LLM 更好:
- 简单问答
- 创意写作
- 实时应用
- 成本敏感的用例
消费级 AI 产品#
在深入技术细节之前,让我们梳理一下你可能已经使用过的产品:
ChatGPT(OpenAI)——引发主流 AI 浪潮的产品。可以访问 GPT-4、o1、用于图像的 DALL-E 和各种插件。其他人都与之比较的基准。
Claude(Anthropic)——以强大的写作、长上下文窗口和细腻的推理而闻名。Claude.ai 是消费者界面;API 为许多应用提供支持。
Gemini(Google)——与 Google 生态系统深度集成。可通过 gemini.google.com 访问,越来越多地嵌入到搜索、文档、Gmail 和 Android 中。
Copilot(Microsoft)——Microsoft 跨产品的 AI 层。与 GitHub Copilot(编程)不同——这是 Windows、Edge 和 Microsoft 365 中的消费者助手。
Perplexity——AI 原生搜索引擎。用引用和来源回答问题。一瞥搜索可能的未来。
其他值得了解的: Grok(xAI,集成到 X/Twitter)、Pi(Inflection)、Le Chat(Mistral)、DeepSeek Chat,以及许多区域/专业替代品。
本地运行模型#
为什么要本地运行?#
云端模型在别人的服务器上运行。你通过互联网发送请求并按使用付费。OpenAI、Anthropic、Google——这是他们的业务。
本地模型在你自己的硬件上运行。你的笔记本电脑、你的服务器、你的数据中心。数据永远不会离开你的控制。
为什么要本地运行?
- 隐私: 敏感数据留在本地
- 成本: 没有 API 费用(但硬件不是免费的)
- 延迟: 没有网络往返
- 可用性: 离线工作,没有速率限制
- 控制: 没有你未选择的服务条款和内容过滤
本地和云端之间的差距已经大大缩小。对于许多实际应用,本地模型已经足够好——特别是对于编程、写作和分析任务。
权衡:前沿能力仍然需要云端。如果你需要在困难推理任务上获得绝对最佳性能,GPT-4、Claude 或 Gemini 是仅限云端的。但这个差距随着每次发布都在缩小。
Ollama#
Ollama 已经成为本地运行模型的事实标准。它使曾经复杂的过程变得非常简单。
# 两个命令安装并运行模型
ollama pull llama3.2
ollama run llama3.2就这样。你正在与完全在你机器上运行的强大 LLM 聊天。
Ollama 处理复杂性:下载模型、管理内存、针对你的硬件优化,并提供 CLI 和本地 API。它支持数十种模型——Llama、Mistral、Qwen、Phi、CodeLlama 等等。
主要功能:
- 简单的 CLI 界面
- OpenAI 兼容的 API(易于替换到现有代码中)
- 一键下载的模型库
- 适用于 Mac、Linux 和 Windows
- 可用时支持 GPU 加速
对于开发者,Ollama 的本地 API 意味着你可以针对本地模型开发,然后在生产中切换到云端 API——或者反过来——只需最少的代码更改。
硬件考虑#
本地运行模型需要硬件。以下是重要的事项:
GPU vs CPU: GPU 大大加速推理。一个在 CPU 上每次响应需要 30 秒的模型可能在 GPU 上只需要 2 秒。Apple Silicon Mac 模糊了这条界限——它们的统一内存和神经引擎使它们在本地推理方面出奇地有能力。
内存(VRAM/RAM): 这通常是限制因素。模型需要适合内存。一个 7B 参数的模型大约需要 4-8GB。一个 70B 的模型需要 35-70GB。量化(下面讨论)减少了这些要求。
量化(Quantization): 将模型权重的精度从 32 位降低到 16 位、8 位甚至 4 位。这减少了内存需求并加速推理,质量损失最小。大多数本地模型以量化格式分发(GGUF、GPTQ、AWQ)。
实用指导:
- 16GB+ RAM 的 Mac: 可以舒适地运行 7B-13B 模型
- 32GB+ RAM 的 Mac: 可以运行 30B+ 模型
- 带 RTX 3090/4090(24GB VRAM)的 PC: 可以运行大多数高达 70B 的模型(量化后)
- 没有 GPU: 仍然可以工作,只是更慢。适合开发和实验。
定制与知识#
微调 vs RAG#
你有一个基础 LLM。你想让它更适合你的特定用例。两种主要方法:
微调(Fine-Tuning)#
拿一个现有模型,继续用你自己的数据训练它。模型的权重实际上会改变。微调后,模型原生"知道"你的信息。
优点: 推理快,知识深度整合,可以学习新风格或行为。 缺点: 昂贵,需要 ML 专业知识,知识可能过时,有灾难性遗忘的风险(模型在其他任务上变差)。
RAG(检索增强生成)#
保持模型不变。当问题来时,首先在你的知识库中搜索相关文档,然后将这些文档与问题一起包含在提示词中。
优点: 更便宜,知识保持最新,不需要训练,易于审计(你可以看到检索了什么)。 缺点: 更慢(两步过程),受上下文窗口限制,检索质量非常重要。
嵌入和向量数据库#
这是使 RAG 工作的技术——而且确实很巧妙。
嵌入(embedding) 是一种将文本(或图像,或任何东西)表示为数字列表——向量——的方式。神奇之处在于:相似的东西有相似的向量。“狗"和"小狗"的向量很接近。“狗"和"民主"相距很远。
你使用嵌入模型创建嵌入(与 LLM 不同,尽管一些 LLM 有嵌入能力)。OpenAI、Cohere、Voyage 和许多其他公司提供嵌入 API。像 BGE 和 E5 这样的开源选项也很好用。
向量数据库(vector database) 是一种优化用于存储和搜索这些向量的数据库。当你问"我们的退款政策是什么?“时,系统:
- 将你的问题转换为向量
- 在向量数据库中搜索相似向量
- 返回这些向量代表的文档
- 将这些文档与你的问题一起输入 LLM
流行的向量数据库包括 Pinecone、Weaviate、Chroma、Qdrant 和 Milvus。带 pgvector 的 Postgres 对许多用例来说效果出奇地好。
评估#
基准测试#
你怎么知道一个模型是否比另一个"更好”?基准测试试图通过在标准化任务上测试模型来回答这个问题。
常见基准测试:
- MMLU(大规模多任务语言理解): 跨 57 个学科的多选题。测试一般知识。
- HumanEval: 编程问题。测试编程能力。
- GSM8K: 小学数学应用题。测试数学推理。
- HellaSwag: 关于日常情况的常识推理。
- TruthfulQA: 测试模型是否给出真实答案,而不是听起来有说服力的废话。
基准测试的问题: 它们是可以被刷分的。模型可以被专门训练在流行基准测试上表现良好,而实际上在真实任务上没有改进。一个在 MMLU 上得分 90% 的模型可能仍然在你的特定用例上失败。
Eval#
Eval(评估)是你为特定用例创建的测试。与基准测试不同,eval 衡量的是对你的应用真正重要的东西。
正在构建客户服务机器人?你的 eval 可能测试:
- 它是否正确回答你 FAQ 中的问题?
- 它是否在需要时适当地升级到人工?
- 它是否保持品牌调性并遵循你的语气指南?
- 它是否拒绝做出公司无法兑现的承诺?
为什么 eval 重要:
- 回归检测: 当你更改提示词或切换模型时,eval 在用户之前发现问题。
- 比较: 客观比较不同模型、提示词或方法对你的用例的效果。
- 迭代: 你无法改进你无法衡量的东西。Eval 使改进变得系统化。
构建好的 eval:
- 从真实用户查询和预期响应开始
- 包括边缘情况和对抗性示例
- 测试模型应该做什么和不应该做什么
- 自动化,以便在每次更改时运行 eval
LLM 作为评判者#
这是一个巧妙的技术:用一个 LLM 来评估另一个 LLM 的输出。
不是手动审查数百个响应,你可以提示一个模型充当评判者:
你正在评估 AI 助手响应的质量。
用户问题:{question}
助手响应:{response}
对响应进行评分:
1. 准确性(1-5):信息是否正确?
2. 有用性(1-5):它真的帮助了用户吗?
3. 清晰度(1-5):它容易理解吗?
解释你的推理,然后提供分数。为什么这有效:
- 扩展到数千个评估
- 比人类审查员更一致(更少疲劳)
- 可以评估难以用程序测试的细微品质
- 比人工评估更便宜更快
局限性:
- 评判模型有自己的偏见和局限性
- 可能会错过它自己也会犯的错误
- 在没有基础的情况下难以处理领域特定的准确性
- 不能完全替代人工评估——更多的是补充
智能体与自动化#
什么是智能体?#
“智能体(agent)“这个词被到处使用。这里有一个工作定义:智能体是一个可以在世界上采取行动的 LLM,而不仅仅是生成文本。
聊天机器人回答你的问题。智能体可能回答你的问题并且预订餐厅、发送电子邮件、查询数据库或编写并执行代码来解决问题。
什么使某物成为智能体而不仅仅是 LLM?
- 目标: 智能体朝着目标工作,而不仅仅是响应提示词。
- 行动: 智能体可以做事情,而不仅仅是说事情。
- 自主性: 智能体决定如何实现目标。
- 循环: 智能体通常在循环中运行——观察、思考、行动、重复。
最简单的智能体模式:给 LLM 访问工具的权限,让它决定使用哪些工具。“找下周从伦敦到东京的航班,检查我的日历,预订与我日程相符的最便宜选项。“智能体将此分解,调用航班 API,调用日历 API,并执行预订。
智能体 vs 工作流#
一个经常被模糊的重要区别:
工作流(Workflows) 是确定性的。你定义步骤:首先做 A,然后做 B,如果 X 则做 C 否则做 D。LLM 可能驱动单个步骤,但编排是编码的。
1. 从电子邮件中提取实体(LLM)
2. 在数据库中查找客户(代码)
3. 生成响应草稿(LLM)
4. 发送给人工审核(代码)智能体 是自主的。你给它们一个目标和工具,它们自己找出步骤。LLM 根据当前状态决定下一步做什么。
目标:"解决这个客户投诉"
工具:[email, database, refund_system, escalation]
→ 智能体决定做什么,以什么顺序何时使用工作流:
- 可预测、已充分理解的流程
- 当你需要可靠性和可审计性时
- 受监管的环境
- 高容量、低复杂度的任务
何时使用智能体:
- 新颖或可变的任务
- 当步骤事先未知时
- 需要复杂推理
- 当灵活性比可预测性更重要时
成本等式: 工作流明显更便宜。你每次运行支付固定数量的 LLM 调用——可预测、可优化、可审计。智能体很贵是因为它们思考。每个决策点——“我应该使用什么工具?"、“那有效吗?"、“下一步是什么?"——都是一次 LLM 调用。一个进行 3 次 LLM 调用的工作流可能变成一个进行 15-30 次调用来解决同一问题的智能体,因为智能体正在推理如何解决它,而不仅仅是执行预定义的步骤。对于大规模已充分理解的任务,工作流在成本上获胜。对于你无法预定义步骤的复杂、可变问题,智能体值得溢价。
工具使用和函数调用#
为了让智能体采取行动,它们需要工具——它们可以调用的函数。这种能力通常被称为函数调用(function calling)或工具使用(tool use)。
它是这样工作的:
- 你用名称、描述和参数定义工具(通常作为 JSON schemas)
- 你在提示词/API 调用中包含这些定义
- 模型可以选择"调用"工具而不是生成文本
- 你的代码执行函数并将结果返回给模型
- 模型使用这些结果继续
示例工具定义:
{
"name": "get_weather",
"description": "Get current weather for a city",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "City name"},
"units": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["city"]
}
}当你问"东京的天气怎么样?“时,模型不会产生幻觉——它调用 get_weather(city="Tokyo"),获取真实数据,然后用事实回应。
每个主要模型提供商现在都支持函数调用:OpenAI、Anthropic、Google 等。语法略有不同,但概念是一样的。
MCP 协议#
模型上下文协议(Model Context Protocol,MCP) 是一个用于连接 AI 模型与工具和数据源的开放标准。把它想象成 AI 的 USB-C——一个通用连接器,意味着你不需要每个设备一根不同的线缆。
在 MCP 之前,每个集成都是定制的。想让你的 AI 访问 GitHub?编写一个 GitHub 集成。Salesforce?另一个集成。你的内部数据库?又一个。这无法扩展。
MCP 定义了一种标准方式,让 AI 客户端(如 Claude、ChatGPT 或你的自定义智能体)从 MCP 服务器发现和使用工具。一个 MCP 服务器可能暴露:
- 工具: AI 可以调用的函数
- 资源: AI 可以读取的数据
- 提示词: 常见任务的模板
影响是显著的:
- 构建一次 MCP 服务器,每个兼容的 AI 都可以使用它
- 工具变得可移植和可重用
- 安全和权限可以标准化
- 生态系统复合——更多服务器意味着更有能力的智能体
关于 MCP 的更多内容,我写了一篇更深入的文章:MCP 服务器:AI 智能体的 USB-C 时刻。
智能体模式#
随着智能体的成熟,常见模式已经出现:
ReAct(推理 + 行动): 智能体在推理(“我需要找到用户的订单历史”)和行动(调用订单 API)之间交替。这个明确的推理步骤提高了可靠性。
规划: 在行动之前,智能体创建一个计划:“为了解决这个问题,我需要 1)查找订单,2)检查库存,3)处理退款,4)发送确认。“计划可以在执行前验证。
反思: 在完成任务(或失败)后,智能体回顾发生了什么:“退款失败是因为订单太旧了。我应该先检查退款政策。“这使得学习和自我纠正成为可能。
工具选择: 当智能体有很多工具时,选择正确的工具变得不简单。技术包括工具描述、少样本示例和层次化工具组织。
人在回路中: 对于高风险行动,智能体可以暂停并在继续之前请求人工批准。好的智能体知道它们何时不确定。
技能#
技能(Skills) 是可重用的专业化提示词,用于扩展智能体的能力。可以把它们想象成你可以插入智能体的"专家模式”——用于代码审查的技能、用于编写文档的技能、用于分析安全漏洞的技能。
与工具(执行操作的函数)不同,技能是塑造智能体思考和响应方式的指令。工具调用 API。技能告诉智能体"当被问到关于 X 的问题时,用这种方式处理,考虑这些因素,并按这种格式输出响应。”
为什么技能很重要:
- 无需微调的专业化: 无需训练新模型就能获得专家级行为。
- 可组合性: 为不同任务混合搭配技能。
- 可分享性: 精心设计的技能可以跨团队、项目使用,甚至可以公开分享。
- 上下文效率: 不必每次都解释你的需求,只需在技能中编码一次。
技能的位置:
技能可以在智能体上下文的不同位置注入:
- 系统提示词: 最常见的方式。技能成为智能体基础指令的一部分,始终保持激活。
- 用户消息前缀: 动态添加到用户请求之前。适用于特定任务的技能。
- 工具描述: 技能可以嵌入工具定义中,指导智能体如何使用特定工具。
- MCP 提示词: MCP 服务器可以将技能作为"提示词"暴露——客户端可以发现和调用的可重用模板。
技能如何影响上下文:
每个技能都会消耗上下文窗口中的 token。这会产生权衡:
- 更多技能 = 更强大的智能体,但对话历史的空间更少
- 详细的技能 = 更好的行为,但每次请求的 token 成本更高
- 始终激活的技能 vs 按需技能 = 可靠性 vs 效率
智能框架通过动态加载技能来管理这一点——根据任务激活相关技能并停用其他技能。
技能结构示例:
## 代码审查技能
审查代码时,你应该:
1. 检查安全漏洞(注入、XSS、认证问题)
2. 识别性能问题
3. 评估可读性和可维护性
4. 提供具体的改进建议和代码示例
按以下格式输出审查结果:
- 摘要(1-2 句话)
- 严重问题(如果有)
- 建议(项目列表)
- 总体评估编程智能体#
为什么重要#
编程智能体代表了 AI 最切实的应用之一——它们实际编写代码,而且代码确实有效。这不是理论;开发者因为这些工具而更快地发布功能。
影响是直接和可衡量的:更少时间在样板代码上,更快的调试,更容易探索不熟悉的代码库。对于许多开发者来说,编程智能体已经变得像他们的 IDE 一样必不可少。
版图#
Claude Code——Anthropic 的基于终端的编程智能体。存在于你的 CLI 中,理解你的整个代码库,可以读取文件、编写代码、运行命令,并根据反馈迭代。为生活在终端中的开发者设计。
Cursor——一个围绕 AI 辅助从头构建的 AI 原生 IDE。不仅仅是自动完成——你可以与你的代码库聊天,生成整个功能,并让 AI 在文件之间进行大范围更改。最接近与 AI 结对编程的东西。
GitHub Copilot——最早也是部署最广泛的。从自动完成开始,发展到聊天,现在包括用于更大任务的 Copilot Workspace。深度 GitHub 集成。
Windsurf——Codeium 的 AI IDE,定位为 Cursor 的替代品。强调速度和理解大型代码库。
Cody(Sourcegraph)——专注于代码库理解。对于上下文至关重要的大型复杂代码库特别强大。
Continue——适用于任何 IDE 的开源编程助手。自带模型(本地或云端)。适合想要控制其 AI 设置的团队。
OpenCode——Claude Code 的开源替代品。基于终端,模型无关,社区驱动的开发。
Aider——另一个优秀的开源终端编程智能体。以其 git 集成和连贯地处理多个文件的能力而闻名。
下一步#
你已经完成了基础知识。接下来呢?
构建东西#
- 从简单开始。 使用 API(OpenAI、Anthropic 等)并构建一个基本的聊天机器人或 RAG 系统。一开始不要过度考虑技术栈。
- 尝试本地模型。 安装 Ollama,在你的笔记本电脑上运行 Llama 或 Qwen。这出奇地简单。
- 探索智能体。 查看 LangChain、LlamaIndex、CrewAI 等框架来构建智能体系统。
- 学习 MCP。 官方文档很扎实。尝试在本地运行一些 MCP 服务器。
- 尽早构建 eval。 无论你构建什么,从第一天就创建 eval。你以后会感谢自己的。
理解这个领域#
- 关注研究。 ArXiv 论文,Google Scholar 对你关心的话题设置提醒。
- 批判性地阅读炒作。 大多数"突破"是渐进的。寻找可复现的结果和真正的基准测试。
- 自己实验。 对什么有效的直觉来自实践经验,而不是阅读。
资源#
- Hugging Face——模型、数据集和一个令人难以置信的社区
- Papers With Code——带实现的研究论文
- Ollama——极其简单的本地模型运行
- LangChain / LlamaIndex——用 LLM 构建的流行框架
- Model Context Protocol——MCP 规范和 SDK
- Chatbot Arena——通过人类投票头对头比较模型
2026 年的 AI 同时被过度炒作和低估。这项技术是真正变革性的——但它也有真正的局限性。LLM 会编造东西。智能体很脆弱。成本很高。进展很快但不均衡。
最好的方法是务实的:理解基础知识,用真实问题实验,对宏大宣言保持怀疑,并构建东西。在这个时代会蓬勃发展的人不是那些能背诵每个缩写词的人——而是那些能发布实际有效的产品的人。
现在去构建一些东西吧。





